Слияние кода завершено, страница обновится автоматически
Dart VM — это набор компонентов для локального выполнения кода на Dart, который включает следующие основные элементы:
С точки зрения реализации, Dart VM можно рассматривать как виртуальную машину, предоставляющую среду выполнения для высокоуровневого языка программирования. Однако это не означает, что Dart всегда выполняется путём интерпретации или JIT-компиляции.
Например, можно использовать Dart VM AOT для преобразования кода на Dart в машинный код, а затем запустить его в урезанной версии Dart VM, которая не содержит компилятора и не может динамически загружать исходный код Dart.
Dart VM имеет несколько способов выполнения вашего кода, такие как:
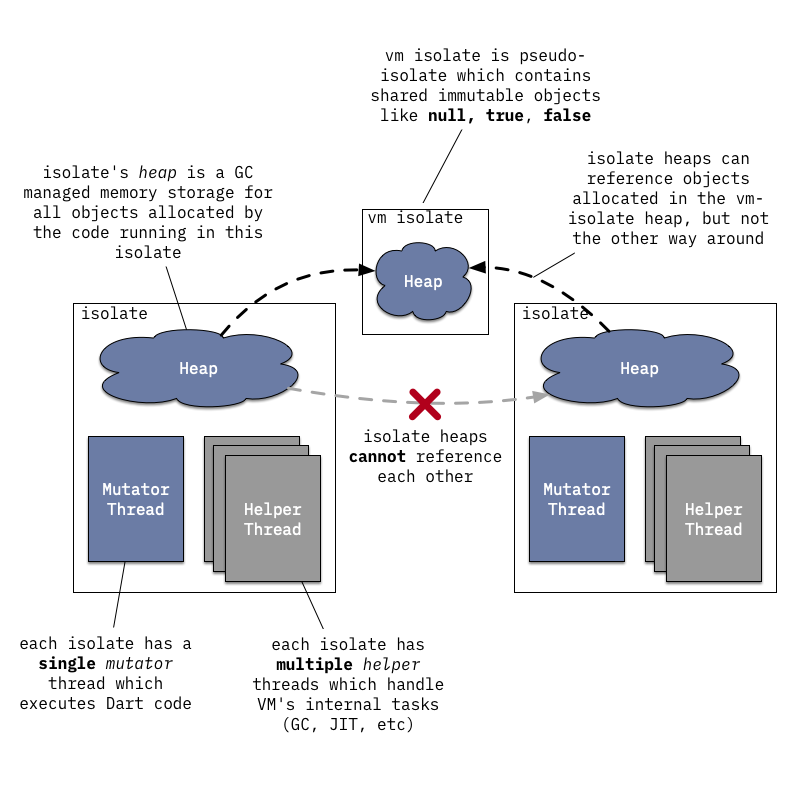
Любой Dart-код внутри Dart VM выполняется в некотором isolate, который можно описать как изолированное пространство выполнения Dart со своим собственным управлением памятью (участком памяти) и обычно со своим собственным потоком управления (mutator-потоком).
Dart VM может одновременно выполнять множество isolates, но они не могут непосредственно делиться состоянием; взаимодействовать они могут только через порты (не путайте с сетевыми портами!).
Отношение между операционными системными потоками и isolates здесь немного расплывчато и сильно зависит от того, как Dart VM внедряется в приложение, однако важно понимать следующее:
isolate за один раз, если он хочет перейти в другой isolate, ему нужно выйти из текущего isolate;isolate; mutator-поток — это поток, который выполняет код Dart и использует общую C-API VM.Однако тот же операционный системный поток может войти в один isolate, выполнить код Dart, выйти из него и войти в другой isolate, чтобы продолжить выполнение; либо множество различных операционных системных потоков могут входить в один isolate и выполнять там код Dart, хотя все они не могут делать это одновременно. Конечно, кроме одного потока Mutator, isolate также может ассоциироваться с несколькими вспомогательными потоками, такими как:- фоновым потоком JIT-компилятора;VM использует внутри себя пулы потоков (dart::ThreadPool), чтобы управлять потоками ОС, и код построен вокруг концепции dart::ThreadPool::Task, а не вокруг концепции потоков ОС.
Например, задача dart::ConcurrentSweeperTask публикуется в глобальный пуле потоков VM вместо создания специального потока для выполнения фоновой очистки; пул потоков выбирает либо свободный поток, либо создает новый поток при отсутствии доступных потоков. Аналогично, по умолчанию реализация для обработки сообщений isolate фактически не создаёт специализированный поток цикла событий, а вместо этого публикует задачу dart::MessageHandlerTask в пуле потоков при получении нового сообщения.
dart::Isolateкласс эквивалентенisolate,dart::Heapкласс эквивалентен кучеisolate, аdart::Threadкласс описывает состояние соединения потока сisolate.
Обратите внимание, что название
Threadможет вызывать путаницу, поскольку все потоки ОС привязываются к одному и тому жеisolate, используя повторно тот же экземпляр потока. Для по умолчанию реализации обработки сообщенийisolateобратитесь кDart_RunLoopиdart::MessageHandler.
Этот раздел объясняет, что происходит при выполнении Dart с командной строки:```dart // hello.dart main() => print('Привет, мир!');
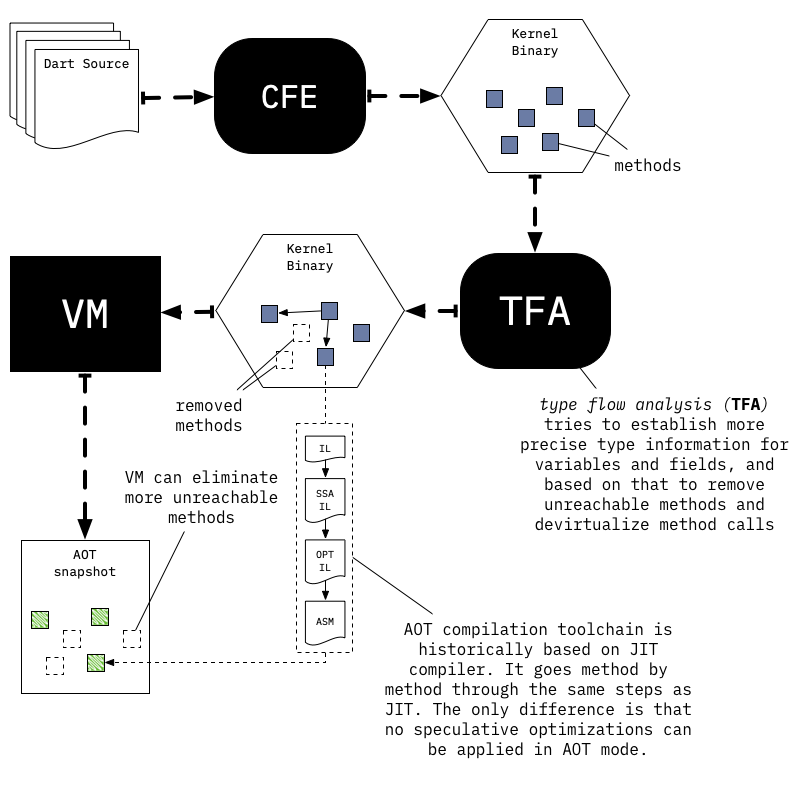
**Dart 2 VM больше не имеет возможности непосредственно выполнять Dart с исходного кода; вместо этого VM ожидает получить бинарный файл ядра (также известный как dill файл), содержащий сериализованное дерево абстрактного синтаксического дерева (AST)**. Задача перевода Dart исходного кода в Kernel AST выполняется универсальным передним конечным устройством (CFE), которое написано на Dart и используется во всех различных инструментах Dart (например, VM, dart2js, Dart Dev Compiler).
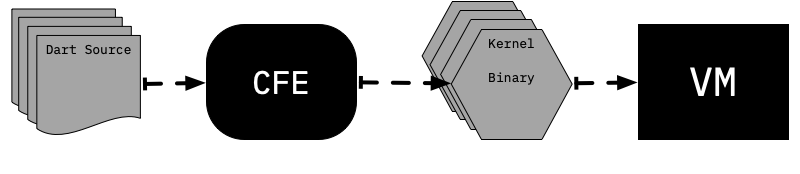
Чтобы обеспечить возможность непосредственного выполнения Dart с исходного кода, здесь хранится вспомогательный `isolate`, называемый сервисом ядра, который занимается компиляцией Dart исходного кода в ядро, после чего VM запускает сгенерированный бинарный файл ядра.
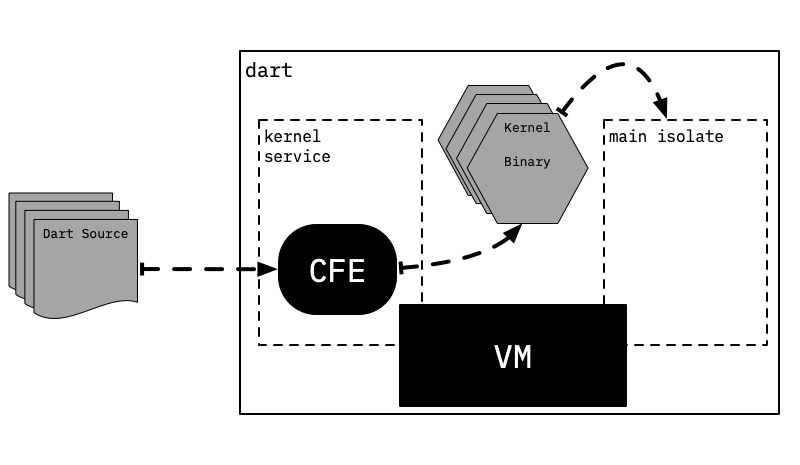
Однако это не единственный способ конфигурации для выполнения Dart-кода CFE и VM; например, **Flutter полностью разделён процесс компиляции в Kernel от процесса его выполнения**, и эти процессы реализуются на разных устройствах: компиляция происходит на машине разработчика (хосте), а выполнение — на целевой мобильной устройстве, которое получает отправленные ему бинарные файлы Kernel с помощью инструмента Flutter.
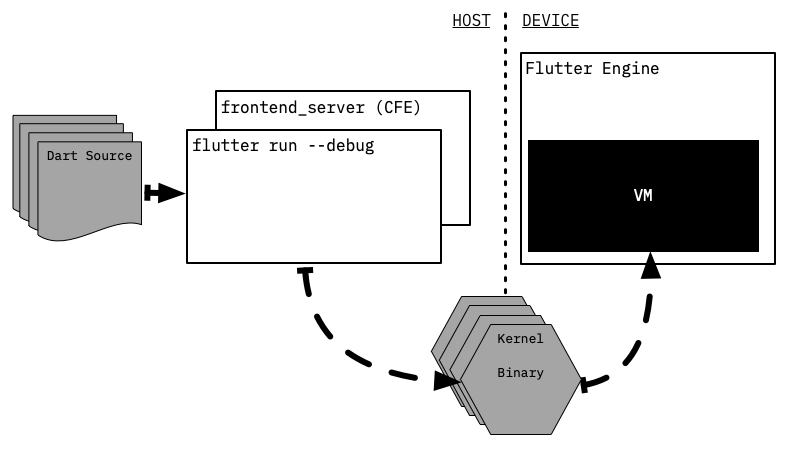Здесь следует обратить внимание на то, что сам Flutter-инструмент не занимается парсингом Dart-кода; вместо этого он создает другой долгоживущий процесс `frontend_server`, который в сущности представляет собой обертку вокруг CFE и некоторых специфических для Flutter преобразований ядра.
`frontend_server` компилирует Dart-источник в файлы ядра, а затем отправляет их на устройство. Когда разработчик запрашивает горячую перезагрузку (`hot reload`), `frontend_server` начинает действовать: в этом случае `frontend_server` может использовать состояние CFE из предыдущей компиляции и переопределять компиляцию только измененных библиотек.
**Как только ядро-бинарники загружены в среду выполнения (VM), они анализируются для создания объектов, представляющих различные программные сущности, однако этот процесс является ленивым**: сначала загружаются базовые данные о библиотеках и классах, каждая сущность, происходящая из ядро-бинарников, хранит указатель на бинарник, чтобы позднее можно было загружать дополнительные данные по мере необходимости.
> Каждый раз, когда мы обращаемся к внутренним объектам VM, мы используем префикс Untagged, поскольку это соответствует названию, используемому внутри VM: внутренние объекты VM определяются C++-классами, название которых начинается с Untagged-заголовка файла `runtime/vm/raw_object.h`. Например, `dart::UntaggedClass` описывает объект VM, представляющий Dart-класс, а `dart::UntaggedField` — объект VM, представляющий поле.**Полностью декодируется информация о классе только при необходимости во время выполнения (например, при поиске членов класса, выделении экземпляров и т.д.)**, на этом этапе члены класса читаются из ядра-бинарников, но на данном этапе не декодируются полностью тела функций, а лишь их сигнатуры.

На этом этапе методы могут успешно быть распознаны и вызваны во время выполнения, так как достаточно информации уже загружено из ядра-бинарников, например, это позволяет распознавать и вызывать функции из библиотеки `main`.>`package:kernel/ast.dart` определяет классы, описывающие AST ядра; `package:front_end` отвечает за парсинг Dart-источника и создание AST ядра из него. `dart::kernel::KernelLoader::LoadEntireProgram` является входной точкой для декодирования AST ядра в соответствующие объекты VM; `pkg/vm/bin/kernel_service.dart` реализует изоляцию сервиса ядра; `runtime/vm/kernel_isolate.cc` связывает реализацию Dart с остальной частью VM; `package:vm` содержит большинство функциональностей VM, основанных на ядре, таких как различные преобразования ядра к ядру; некоторые специфические для VM преобразования всё ещё находятся в `package:kernel` по историческим причинам. Сначала все функции имеют заполнитель вместо своего исполняемого кода: они указывают на `LazyCompileStub`, который просто требует от системы выполнения сгенерировать исполняемый код для текущей функции, а затем выполняет `tail-call` этого нового сгенерированного кода.
Первая компиляция функции осуществляется с помощью незапечатанного компилятора.

Незапечатанный компилятор генерирует машинный код за два прохода:
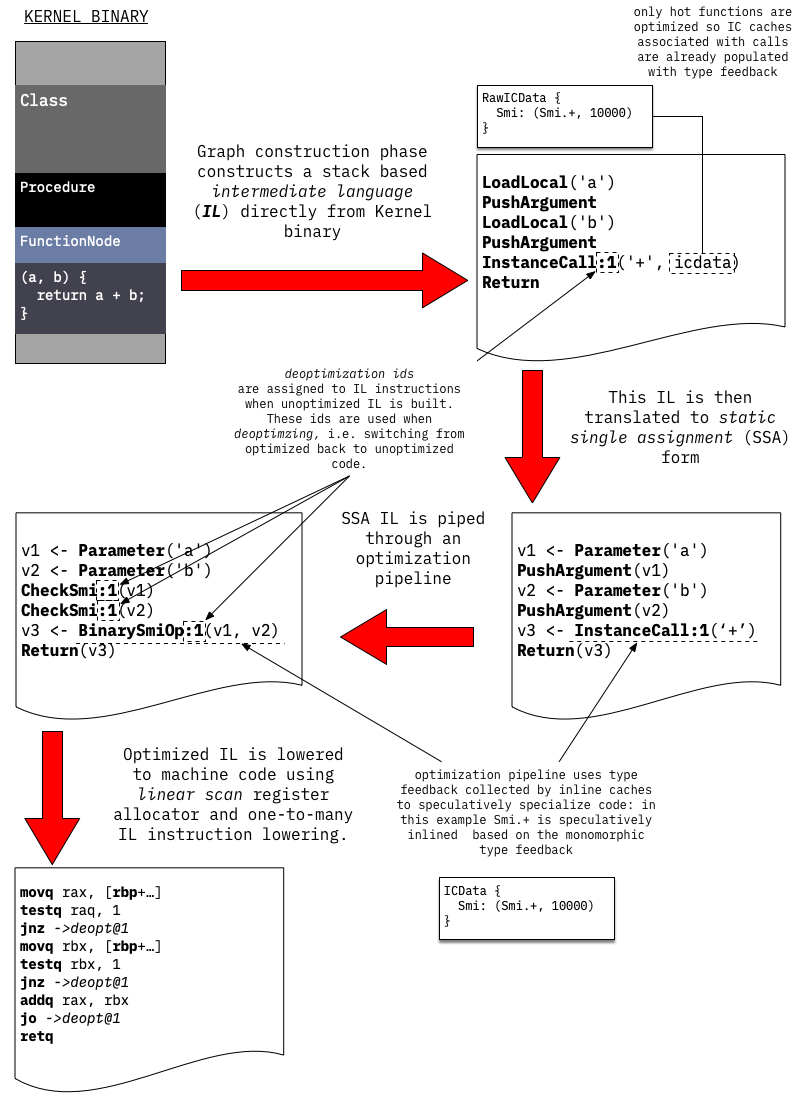
- 1. **Проходит через сериализованное дерево разбора (AST) тела функции для создания графа потока управления (CFG)**, CFG состоит из базовых блоков, заполненных инструкциями промежуточного уровня (IL). В этом этапе используемые IL-инструкции аналогичны командам виртуальной машины на основе стека: они получают операнды из стека, выполняют операцию и помещают результат обратно в тот же стек.
> На самом деле не все функции имеют реальное тело AST Dart/Kernal, например, локальные функции, определённые на C++, или искусственные функции `tear-off`, созданные Dart VM, в этих случаях IL просто создаётся из ниоткуда, а не генерируется из Kernel AST.
- 2. Генерируемый CFG прямым образом компилируется в машинный код с использованием пары IL-инструкций: каждая IL-инструкция расширяется до нескольких команд на уровне машинного кода.
На данном этапе никакие оптимизации не применяются; основной целью незапечатанного компилятора является быстрое генерирование исполняемого кода.Это также означает, что **неразмеченной компилятор не пытается статически разрешать любые вызовы, которые еще не были разрешены в бинарном файле Kernel**, VM в настоящее время не использует расписание на основе виртуальных таблиц или таблиц интерфейсов, а вместо этого использует **встроенный кэш** для реализации динамических вызовов.> Оригинальная реализация встроенного кэша фактически заключалась в модификации нативного кода функции, поэтому она называется **встроенным кэшем**, идея встроенного кэша восходит к Smalltalk-80, см. Эффективную реализацию системы Smalltalk-80.
**Основная идея встроенного кэша заключается в том, чтобы кэшировать результаты разрешения методов при конкретных точках вызова**, механизмы встроенного кэша, используемые VM, включают:
- Кэш, специфический для вызова (`dart::UntaggedICData`), который отображает класс получателя на метод, если получатель является экземпляром совпадающего класса, он должен вызвать этот метод; кэш также хранит некоторую вспомогательную информацию, такую как счетчик частоты вызовов, который используется для отслеживания частоты появления данного класса в данной точке вызова.
- Общий stub для поиска, который реализует быстрый путь для вызова метода. Этот stub ищет в заданном кэше, чтобы проверить наличие записи, которая соответствует классу получателя. Если запись найдена, stub увеличивает счетчик частоты и использует кэшированный метод с помощью `tail-calls`. В противном случае stub обращается к помощнику системы выполнения для реализации логики разбора метода. Если разбор метода успешен, кэш будет обновлен, и последующие вызовы уже не потребуют входа в систему выполнения.Перевод выполнен согласно указанным правилам, сохранив структуру и смысл оригинального текста.
Схема ниже демонстрирует структуру и состояние встроенной кэшированной области, связанной с вызовом `animal.toFace()`, который был выполнен дважды с использованием экземпляра `Dog` и один раз — с использованием экземпляра `Cat`.

Неоптимизированная компиляторная система сама по себе способна выполнять любой Dart-код, но она генерирует довольно медленный код, поэтому виртуальная машина также реализует адаптивную систему оптимизации. Основная идея адаптивной оптимизации заключается в следующем: **используйте профиль выполнения программы для управления решениями по оптимизации**.
При выполнении неоптимизированного кода он собирает следующую информацию:
- Как было указано выше, встроенная кэшированная область собирает информацию о типах получателей, наблюдаемых при вызовах;
- Счетчики выполнения, связанные с функциями и базовыми блоками внутри функций, отслеживают горячие зоны кода;
Когда счетчики выполнения, связанные с функциями, достигают определённого порогового значения, эти функции передаются фоновой оптимизационной компиляторной системе для оптимизации.Запуск оптимизированной компиляции происходит аналогично запуску неоптимизированной компиляции: **путем последовательного прохождения сериализованного ядра AST и построения неоптимизированного IL для оптимизируемой функции**.Однако вместо того, чтобы непосредственно преобразовывать IL в машинный код, оптимизационная компиляционная система продолжает преобразование неоптимизированного IL в статическое одноразовое присвоение (SSA), а затем использует оптимизацию IL на основе SSA, основанную на собранной обратной связи типа, для специализации и прогнозирования, а также применяет ряд оптимизаций, специфичных для Dart, таких как:
- Инлайнование (inlining);
- Анализ диапазона значений (range analysis);
- Пропагация типов данных (type propagation);
- Выбор представления данных (representation selection);
- Передача хранилищ (store-to-load и load-to-load forwarding);
- Глобальное значение вычисление (global value numbering);
- Вывод назначений (allocation sinking);
И так далее.
Наконец, оптимизированный IL преобразуется в машинный код с помощью линейного сканирования регистров и простого снижения IL-инструкций одним к многим.
По завершении компиляции фоновая компиляционная система просит мутаторный поток войти в безопасную точку и прикрепляет оптимизированный код к функции.
> В общих чертах, поток считается находящимся в безопасной точке, когда состояние, связанное с потоком (например, стековые кадры, куча и т.д.), согласовано, и доступ к нему или его модификация могут происходить без прерывания самого потока. Обычно это означает, что поток либо приостановлен, либо выполняет код вне среды исполнения, такой как выполнение нативного кода.Следующий вызов этой функции будет использовать оптимизированный код. Некоторые функции содержат очень длинные циклы выполнения, и для этих функций имеет смысл выполнять переход с неоптимизированного кода на оптимизированный код, пока функция остаётся активной. **Этот процесс называется заменой стека (OSR)**, так как при этом стековый кадр одной версии функции прозрачно заменяется стековым кадром другой версии той же самой функции.
> Исходный код компилятора расположен в директории `runtime/vm/compiler`; входная точка компилирования — это `dart::CompileParsedFunctionHelper::Compile`; IL определён в `runtime/vm/compiler/backend/il.h`; преобразование ядра в IL начинается с функции `dart::kernel::StreamingFlowGraphBuilder::BuildGraph`, которая также отвечает за построение IL для различных искусственных функций; когда `InlineCacheMissHandler` обрабатывает пропущенные значения кэша IC, `dart::compiler::StubCodeCompiler::GenerateNArgsCheckInlineCacheStub` генерирует машинный код для стуб-функций кэширования; оптимизирующие пайпы компилятора определены в `runtime/vm/compiler/compiler_pass.cc`; большинство специализации основана на типах обратной связи и реализуется через `dart::JitCallSpecializer`.
Необходимо отметить, что код, созданный оптимизирующим компилятором, создаётся на основе предположений, сделанных на основе профилей выполнения приложения.Например, если динамический вызов точки видел только экземпляр класса C в качестве получателя, он будет преобразован в объект, который можно непосредственно вызвать, проверяя, является ли получатель экземпляром ожидаемого класса C. Однако эти предположения могут быть нарушены во время выполнения программы:
```c
void printAnimal(obj) {
print('Животное {');
print(' ${obj.toString()}');
print('}');
}
// Вызовите printAnimal(...) много раз с экземпляром Кота.
// В результате printAnimal(...) будет оптимизировано,
// предполагая, что obj всегда является Котом.
for (int i = 0; i < 50000; i++)
printAnimal(Kot());
// Теперь вызовите printAnimal(...) с Пёсиком - оптимизированная версия
// не сможет обработать такой объект, поскольку она была
// скомпилирована, предполагая, что obj всегда является Котом.
// Это приведёт к деоптимизации.
printAnimal(Pesik());
Каждый раз, когда код делает предположения для оптимизации, они могут быть нарушены во время выполнения, поэтому важно гарантировать восстановление первоначального поведения при нарушении этих предположений.Процесс восстановления также известен как деоптимизация: когда оптимизированная версия встречает ситуацию, которую она не может обработать, она просто передаёт выполнение на соответствующую точку в некомпилированной версии функции и продолжает выполнение там, где нет никаких предположений, а значит, она способна обрабатывать все возможные входные данные. ВМ обычно отказывается от оптимизированной версии функции после декомпиляции, а затем снова её оптимизирует с использованием более свежих данных типизации.ВМ использует два способа защиты предположений, сделанных компилятором:
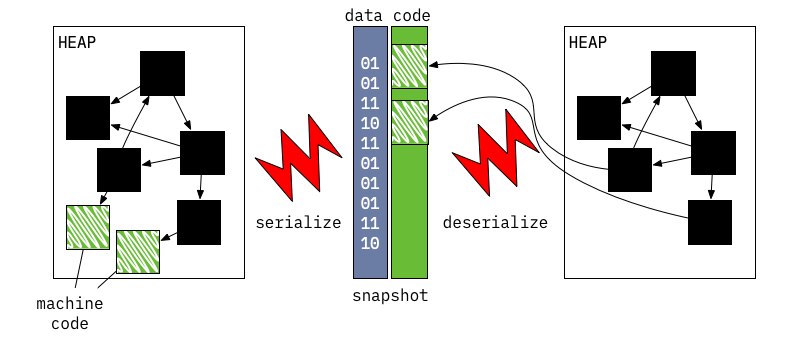
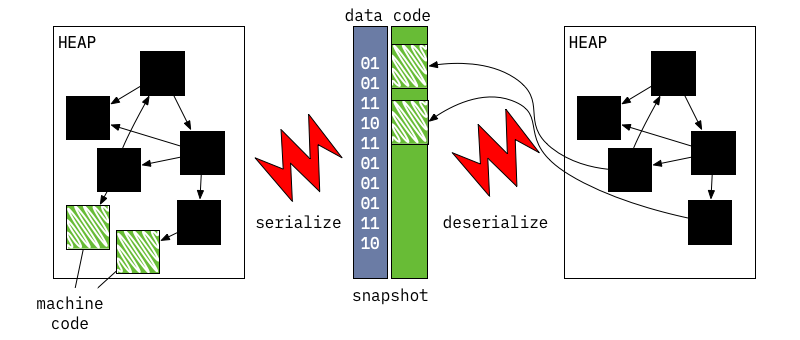
C никогда не расширялся, и использовать эту информацию в процессе типизации. Однако последующее динамическое загрузка кода или завершение класса может ввести подкласс C. В этом случае среда выполнения должна найти и удалить все оптимизированные версии кода, скомпилированные на основе предположения, что класс C не имеет подклассов. Среда выполнения может найти некоторые теперь недействительные оптимизированные версии кода на стеке выполнения; в таком случае затронутые кадры будут помечены как "недействительные", и будут декомпилироваться при возврате выполнения. Эта декомпилирование называется ленивой декомпилированием: поскольку она откладывается до тех пор, пока управление не вернется к оптимизированному коду.> Декомпиляционный механизм реализован в runtime/vm/deopt_instructions.cc, который представляет собой микрокод для интерпретатора декомпиляционных инструкций, описывающих, как восстановить состояние независимого кода из состояния оптимизированного кода. Инструкции декомпиляции создаются методом dart::CompilerDeoptInfo::CreateDeoptInfo для каждого потенциально "недействительного" места в оптимизированном коде во время компиляции.ВМ может создать бинарный снимок стеков изолатов или более точную сериализованную графу объектов, находящихся в стеках, и затем использовать этот снимок для воссоздания такого же состояния при запуске новых изолатов.
Формат снимка является нижележащим и оптимизированным для быстрого старта: он представляет собой список объектов, которые следует создать, вместе с указаниями о том, как их соединять.
Изначальная идея за снимками заключается в том, чтобы ВМ могла быстро распаковать все необходимые внутренние структуры данных из снимка вместо анализа исходного кода Dart и последующего создания внутренних структур данных ВМ.> Идея снимков была вдохновлена Smalltalk образами, которые, в свою очередь, были вдохновлены магистерской диссертацией Алана Кая. Dart ВМ использует кластеризацию сериализации, которая аналогична технологии Parcels: быстрая и многофункциональная технология двоичной развертки и Clustering Serialization with Fuel. Первоначальный снимок не включал машинный код, но позже эта возможность была добавлена при разработке компилятора AOT. Мотивация для разработки компилятора AOT и снимков с кодом заключается в возможности использования виртуальной машины на платформах, где JIT-компиляция невозможна из-за ограничений уровня платформы.Снимки с кодом работают практически так же, как обычные снимки, но имеют некоторые различия: они содержат раздел с кодом, который отличается от других частей снимка тем, что ему не требуется десериализация. Этот раздел кода организован таким образом, чтобы после его загрузки в память он сразу становился частью кучи.
runtime/vm/clustered_snapshot.ccзанимается сериализацией и десериализацией снимков; API-функцииDart_CreateXyzSnapshot[AsAssembly]отвечают за запись снимков кучи (например,Dart_CreateAppJITSnapshotAsBlobsиDart_CreateAppAOTSnapshotAssembly);Dart_CreateIsolateGroupможет выбрать получение данных снимка для запускаisolate.
AppJIT-снимки были введены для снижения времени предварительной JIT-компиляции для крупных Dart-приложений, таких как dartanalyzer или dart2js. Когда эти инструменты используются для работы с малыми проектами, время, затраченное ими на выполнение реальной работы, равно времени, затраченному виртуальной машиной на JIT-компиляцию этих приложений.
AppJIT-снимки могут решить эту проблему: можно запустить приложение на виртуальной машине с использованием некоторого набора тренировочных данных, а затем сериализовать все сгенерированное кодовое пространство и внутренние данные структур виртуальной машины в AppJIT-снимок, вместо распространения приложения в виде исходников (или ядра).При запуске с этого снимка виртуальная машина всё ещё способна выполнять JIT-компиляцию.
AOT-снимки были введены для платформ, где JIT-компиляция невозможна, но они также могут использоваться для быстрого старта и снижения потерь производительности.
Сравнение характеристик производительности между JIT и AOT часто вызывает много путаницы:
В настоящее время лучшая производительность достигается при работе Dart VM с JIT, а лучшее время старта — при использовании Dart VM с AOT. Неспособность выполнять JIT компиляцию означает:
Все эти анализы являются консервативными: это значит, что они не могут выполнять больше оптимизаций, чем JIT, поскольку всегда можно вернуться к незапущенному состоянию для обеспечения правильного поведения.
Все возможные функции будут скомпилированы в машинный код без использования спекулятивной оптимизации, а информация о потоке типов будет обрабатываться специальным образом (например, удаление виртуальных вызовов).
После компиляции всех функций можно сделать снимок стека, после чего можно использовать предварительно скомпилированный runtime для запуска созданного снимка. Это особая вариация Dart VM, которая не включает JIT и средства динамической загрузки кода.
"package:vm/transformations/type_flow/transformer.dart"является точкой входа для анализа и преобразования потока типов на основе результатов TFA;dart::Precompiler::DoCompileAll— точка входа для цикла AOT компиляции в VM.
dart::UntaggedICData);InlineCacheStub);В режиме JIT время выполнения обновляет только сам кэш, но в режиме AOT время выполнения может заменять кэш и локальный блок кода в зависимости от состояния inline cache.
Изначально все динамические вызовы начинаются в состоянии несвязанного, когда достигается первая точка вызова, SwitchableCallMissStub вызывает помощник выполнения DRT_SwitchableCallMiss, который связывает эту точку вызова.
Затем DRT_SwitchableCallMiss пытается превратить точку вызова в мономорфическое состояние, где точка вызова становится прямым вызовом, она обращается к методу через специальную точку входа, которая проверяет, имеет ли получатель ожидаемый класс. На приведённом выше примере мы допускаем, что при первом выполнении вызова obj.method() экземпляром является класс C, а также что obj.method разрешается как C.method.
При следующем выполнении того же точки входа вызов будет непосредственно осуществляться через C.method, минуя любой процесс поиска метода по типу.Однако он войдет в специальную точку входа, которая проверяет, остается ли obj экземпляром класса C. В случае отсутствия этого условия будет вызван DRT_SwitchableCallMiss, который попытается выбрать следующее состояние точки входа.C.method может продолжать оставаться действительной целью для вызова, например, если obj является экземпляром класса D, расширяющим класс C, но не переопределяющим метод C.method. В этом случае мы будем проверять возможность преобразования точки входа в состояние с единственной целевой точкой, реализованное через SingleTargetCallStub (см. также dart::UntaggedSingleTargetCache).

Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.



Опубликовать ( 0 )