Слияние кода завершено, страница обновится автоматически
| title | category | head | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
读写分离和分库分表详解 |
高性能 |
|
见名思意,根据读写分离的名字,我们就可以知道:读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
我简单画了一张图来帮助不太清楚读写分离的小伙伴理解。
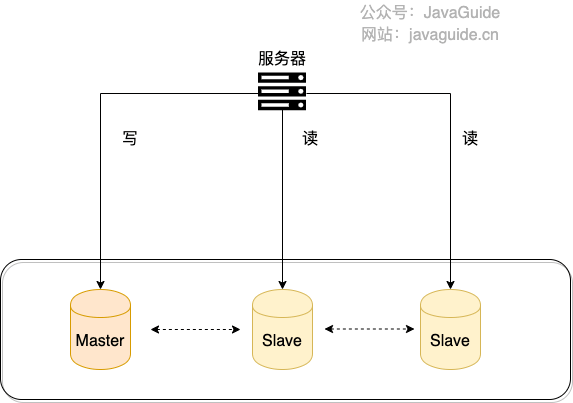
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。
不论是使用哪一种读写分离具体的实现方案,想要实现读写分离一般包含如下几步:
落实到项目本身的话,常用的方式有两种:
1. 代理方式
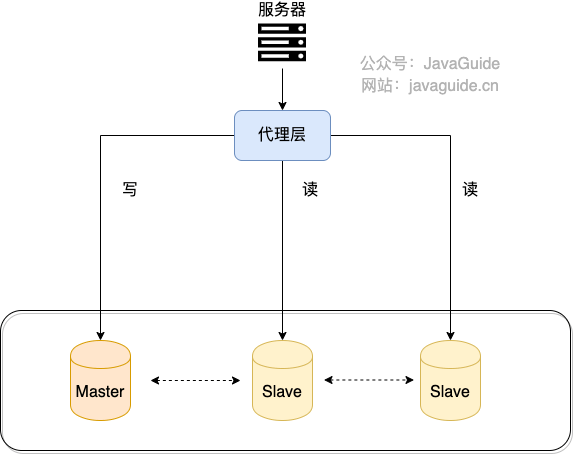
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
提供类似功能的中间件有 MySQL Router(官方, MySQL Proxy 的替代方案)、Atlas(基于 MySQL Proxy)、MaxScale、MyCat。
关于 MySQL Router 多提一点:在 MySQL 8.2 的版本中,MySQL Router 能自动分辨对数据库读写/操作并把这些操作路由到正确的实例上。这是一项有价值的功能,可以优化数据库性能和可扩展性,而无需在应用程序中进行任何更改。具体介绍可以参考官方博客:MySQL 8.2 – transparent read/write splitting。
2. 组件方式
在这种方式中,我们可以通过引入第三方组件来帮助我们读写请求。
这也是我比较推荐的一种方式。这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用 sharding-jdbc ,直接引入 jar 包即可使用,非常方便。同时,也节省了很多运维的成本。
你可以在 shardingsphere 官方找到 sharding-jdbc 关于读写分离的操作。
MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)。因此,我们根据主库的 MySQL binlog 日志就能够将主库的数据同步到从库中。
更具体和详细的过程是这个样子的(图片来自于:《MySQL Master-Slave Replication on the Same Machine》):
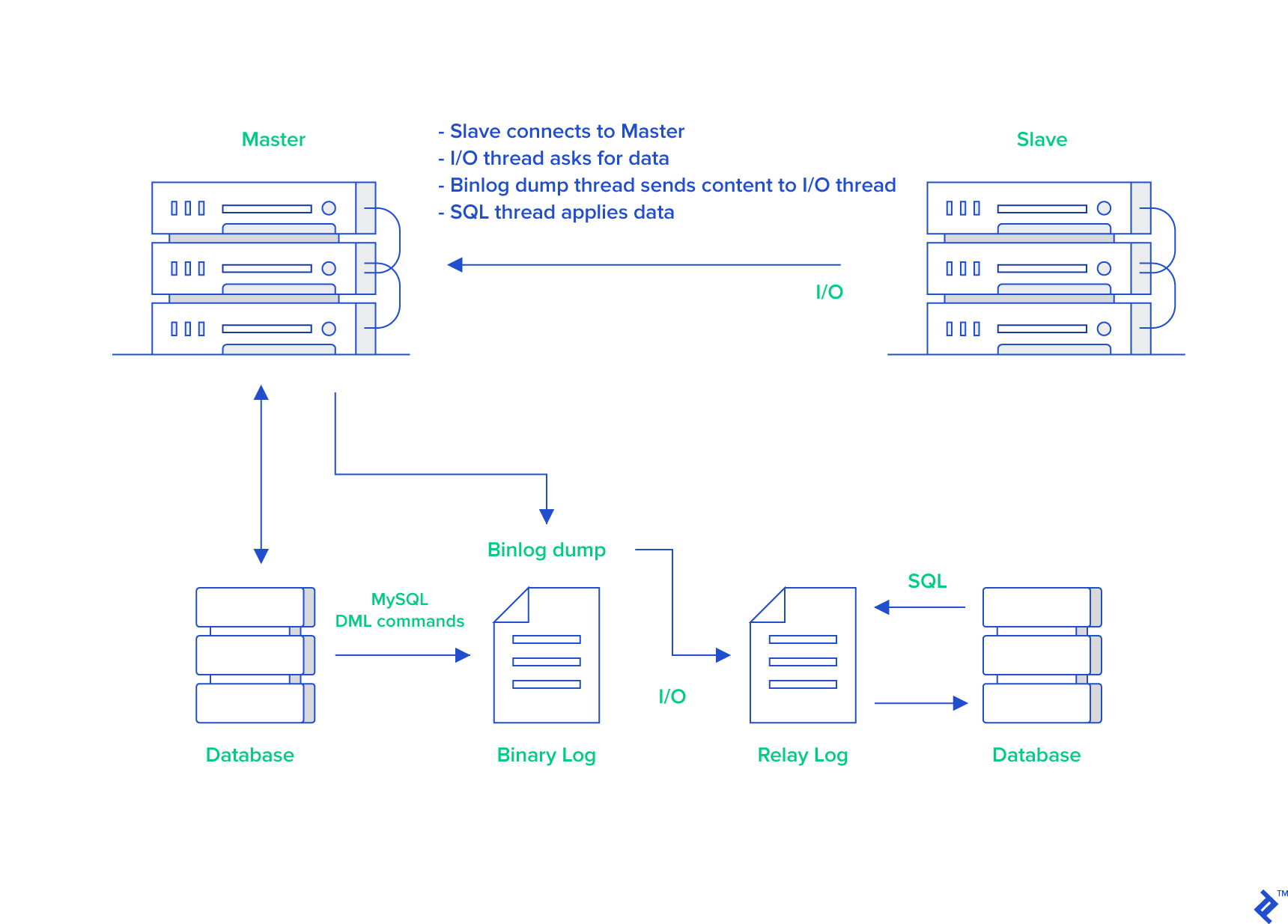
怎么样?看了我对主从复制这个过程的讲解,你应该搞明白了吧!
你一般看到 binlog 就要想到主从复制。当然,除了主从复制之外,binlog 还能帮助我们实现数据恢复。
🌈 拓展一下:
不知道大家有没有使用过阿里开源的一个叫做 canal 的工具。这个工具可以帮助我们实现 MySQL 和其他数据源比如 Elasticsearch 或者另外一台 MySQL 数据库之间的数据同步。很显然,这个工具的底层原理肯定也是依赖 binlog。canal 的原理就是模拟 MySQL 主从复制的过程,解析 binlog 将数据同步到其他的数据源。
另外,像咱们常用的分布式缓存组件 Redis 也是通过主从复制实现的读写分离。
🌕 简单总结一下:
MySQL 主从复制是依赖于 binlog 。另外,常见的一些同步 MySQL 数据到其他数据源的工具(比如 canal)的底层一般也是依赖 binlog 。
读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 主从同步延迟 。
如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢(注意:我这里说的是避免而不是减少延迟)?
这里提供两种我知道的方案(能力有限,欢迎补充),你可以根据自己的业务场景参考一下。
既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
比如 Sharding-JDBC 就是采用的这种方案。通过使用 Sharding-JDBC 的 HintManager 分片键值管理器,我们可以强制使用主库。
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
// 继续JDBC操作
对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
关于如何避免主从延迟,我们这里介绍了两种方案。实际上,延迟读取这种方案没办法完全避免主从延迟,只能说可以减少出现延迟的概率而已,实际项目中一般不会使用。
总的来说,要想不出现延迟问题,一般还是要强制将那些必须获取最新数据的读请求都交给主库处理。如果你的项目的大部分业务场景对数据准确性要求不是那么高的话,这种方案还是可以选择的。
我们在上面的内容中也提到了主从延迟以及避免主从延迟的方法,这里我们再来详细分析一下主从延迟出现的原因以及应该如何尽量减少主从延迟。
要搞懂什么情况下会出现主从延迟,我们需要先搞懂什么是主从延迟。
MySQL 主从同步延时是指从库的数据落后于主库的数据,这种情况可能由以下两个原因造成:
与主从同步有关的时间点主要有 3 个:
结合我们上面讲到的主从复制原理,可以得出:
那什么情况下会出现出从延迟呢?这里列举几种常见的情况:
《MySQL 实战 45 讲》这个专栏中的读写分离有哪些坑?这篇文章也有对主从延迟解决方案这一话题进行探讨,感兴趣的可以阅读学习一下。
读写分离主要应对的是数据库读并发,没有解决数据库存储问题。试想一下:如果 MySQL 一张表的数据量过大怎么办?
换言之,我们该如何解决 MySQL 的存储压力呢?
答案之一就是 分库分表。
分库 就是将数据库中的数据分散到不同的数据库上,可以垂直分库,也可以水平分库。
垂直分库 就是把单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。
举个例子:说你将数据库中的用户表、订单表和商品表分别单独拆分为用户数据库、订单数据库和商品数据库。

水平分库 是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,这样就实现了水平扩展,解决了单表的存储和性能瓶颈的问题。
举个例子:订单表数据量太大,你对订单表进行了水平切分(水平分表),然后将切分后的 2 张订单表分别放在两个不同的数据库。

分表 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
垂直分表 是对数据表列的拆分,把一张列比较多的表拆分为多张表。
举个例子:我们可以将用户信息表中的一些列单独抽出来作为一个表。
水平分表 是对数据表行的拆分,把一张行比较多的表拆分为多张表,可以解决单一表数据量过大的问题。
举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水平拆分只能解决单表数据量大的问题,为了提升性能,我们通常会选择将拆分后的多张表放在不同的数据库中。也就是说,水平分表通常和水平分库同时出现。

遇到下面几种场景可以考虑分库分表:
不过,分库分表的成本太高,如非必要尽量不要采用。而且,并不一定是单表千万级数据量就要分表,毕竟每张表包含的字段不同,它们在不错的性能下能够存放的数据量也不同,还是要具体情况具体分析。
之前看过一篇文章分析 “InnoDB 中高度为 3 的 B+ 树最多可以存多少数据”,写的挺不错,感兴趣的可以看看。
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
常见的分片算法有:
id 为 1~299999 的记录分到第一个表, 300000~599999 的分到第二个表。范围分片适合需要经常进行范围查找且数据分布均匀的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。分片键(Sharding Key)是数据分片的关键字段。分片键的选择非常重要,它关系着数据的分布和查询效率。一般来说,分片键应该具备以下特点:
实际项目中,分片键很难满足上面提到的所有特点,需要权衡一下。并且,分片键可以是表中多个字段的组合,例如取用户 ID 后四位作为订单 ID 后缀。
记住,你在公司做的任何技术决策,不光是要考虑这个技术能不能满足我们的要求,是否适合当前业务场景,还要重点考虑其带来的成本。
引入分库分表之后,会给系统带来什么挑战呢?
另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理、影子库、数据加密和脱敏等功能。
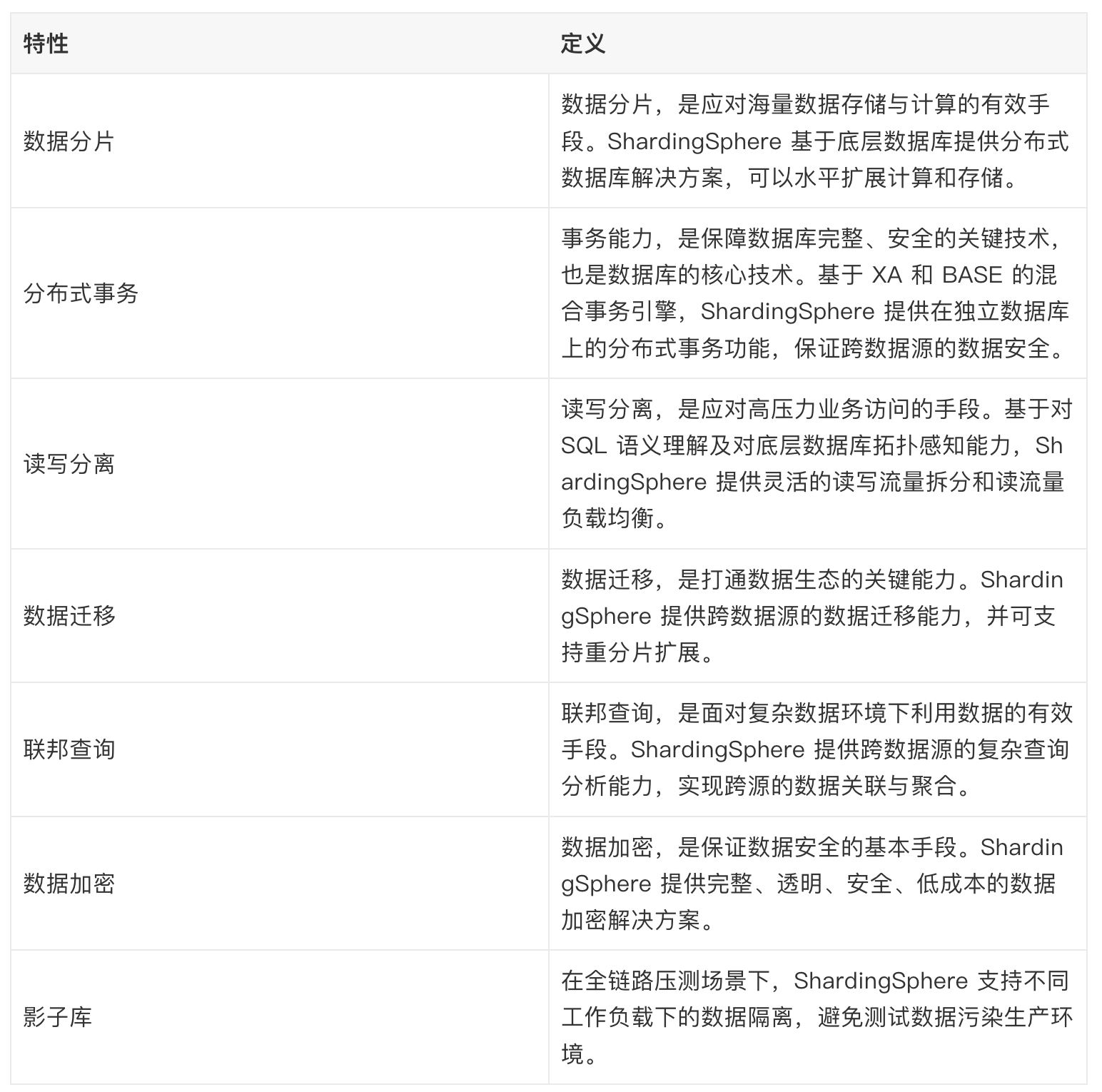
ShardingSphere 提供的功能如下:
ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:https://shardingsphere.apache.org/document/current/cn/overview/):
另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
不过,还是要多提一句:现在很多公司都是用的类似于 TiDB 这种分布式关系型数据库,不需要我们手动进行分库分表(数据库层面已经帮我们做了),也不需要解决手动分库分表引入的各种问题,直接一步到位,内置很多实用的功能(如无感扩容和缩容、冷热存储分离)!如果公司条件允许的话,个人也是比较推荐这种方式!
分库分表之后,我们如何将老库(单库单表)的数据迁移到新库(分库分表后的数据库系统)呢?
比较简单同时也是非常常用的方案就是停机迁移,写个脚本老库的数据写到新库中。比如你在凌晨 2 点,系统使用的人数非常少的时候,挂一个公告说系统要维护升级预计 1 小时。然后,你写一个脚本将老库的数据都同步到新库中。
如果你不想停机迁移数据的话,也可以考虑双写方案。双写方案是针对那种不能停机迁移的场景,实现起来要稍微麻烦一些。具体原理是这样的:
想要在项目中实施双写还是比较麻烦的,很容易会出现问题。我们可以借助上面提到的数据库同步工具 Canal 做增量数据迁移(还是依赖 binlog,开发和维护成本较低)。
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )