Слияние кода завершено, страница обновится автоматически
(简体中文|English)
PP-VPR 是一个 提供声纹特征提取,检索功能的工具。提供了多种准工业化的方案,轻松搞定复杂场景中的难题,支持使用命令行的方式进行模型的推理。 PP-VPR 也支持界面化的操作,容器化的部署。
VPR 的基本流程如下图所示:
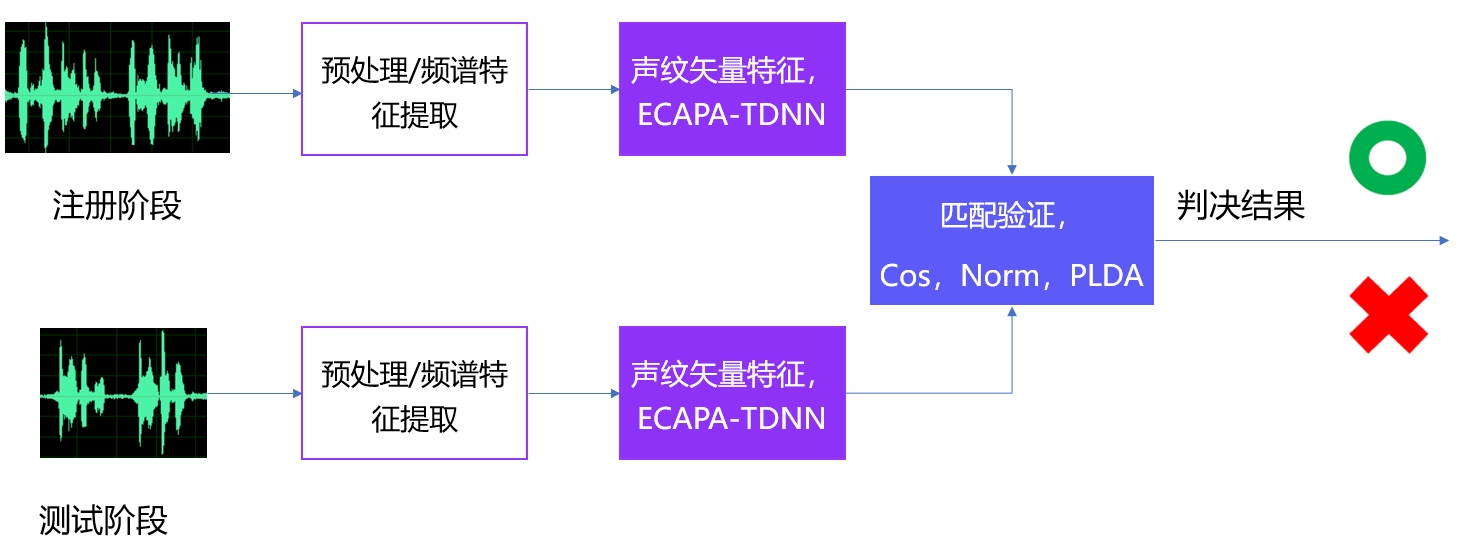
PP-VPR 的主要特点如下:
paddlespeech vector --task spk --input xxx.wav 方式调用预训练模型进行推理。支持的预训练模型列表:released_model。 更多关于模型设计的部分,可以参考 AIStudio 教程:
模型的训练的参考脚本存放在 examples 中,并按照 examples/数据集/模型 存放,数据集主要支持 VoxCeleb,模型支持 ecapa-tdnn 模型。
具体的执行脚本的步骤记录在 run.sh 当中。具体可参考: sv0
PP-VPR 支持在使用pip install paddlespeech后 使用命令行的方式来使用预训练模型进行推理。
具体支持的功能包括:
具体的使用方式可以参考: speaker_verification
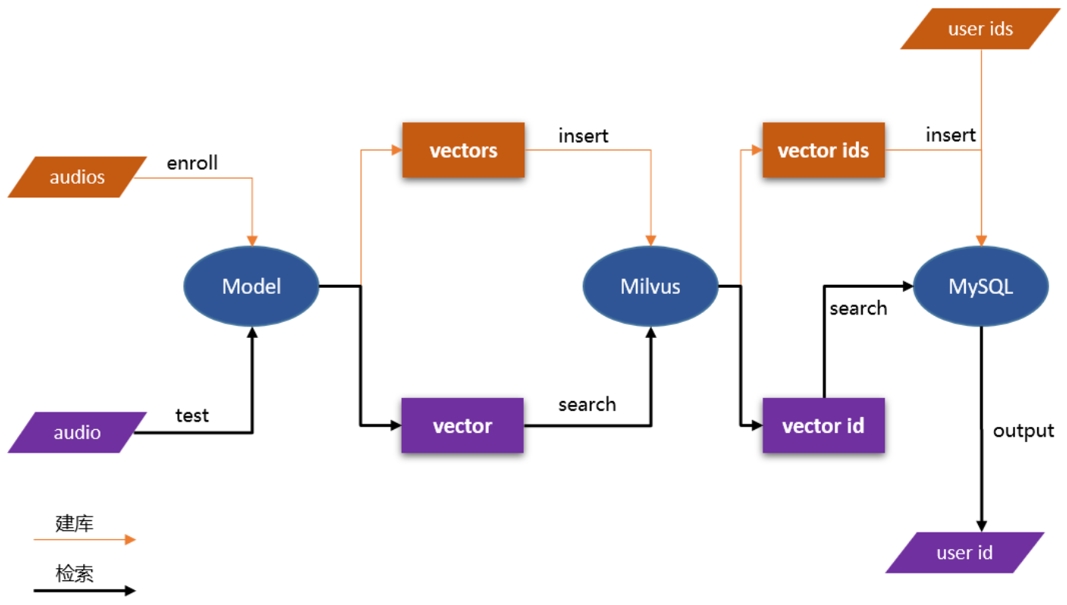
PP-VPR 支持 Docker 容器化服务部署。通过 Milvus, MySQL 进行高性能建库检索。
server 的 demo: audio_searching
关于服务部署方面的更多资料,可以参考 AIStudio 教程:
关于如何使用 PP-VPR,可以看这里的 install,其中提供了 简单、中等、困难 三种安装方式。如果想体验 paddlespeech 的推理功能,可以用 简单 安装方式。
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )