Слияние кода завершено, страница обновится автоматически
Rabbitmq — Official Image | Docker Hub
拉取镜像:
docker pull rabbitmq:3.10.1-management
运行容器:
docker run -d --hostname my-rabbit --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq镜像id(只需要填前几位,确保与其他镜像id即可识别)
hostname: контейнер внутри хоста
коммуникационный порт: 5672
web интерфейс порт: 15672
не забудьте открыть порты 5672 и 15672.
По умолчанию имя пользователя и пароль — guest.
Подробнее см. официальную документацию:
AMQP 0-9-1 Model Explained — RabbitMQ
AMQP (Advanced Message Queuing Protocol) — это сетевой протокол. Он поддерживает связь между соответствующими требованиями клиентскими приложениями (application) и промежуточным программным обеспечением для обмена сообщениями (messaging middleware broker).
Брокер сообщений (message brokers) получает сообщения от производителей (publishers), также называемых производителями (producers), и отправляет их получателям (consumers) в соответствии с установленными правилами маршрутизации.
Поскольку AMQP является сетевым протоколом, производители, потребители и брокеры сообщений могут находиться на разных устройствах.
Процесс работы AMQP 0–9–1 выглядит следующим образом: сообщение (message) отправляется издателем (publisher) на обмен (exchange), который часто сравнивают с почтовым отделением или почтовым ящиком. Затем обмен направляет полученные сообщения в соответствующие очереди (queue) в соответствии с правилами маршрутизации. Наконец, AMQP-брокер доставляет сообщения подписчикам этой очереди или потребителям, которые могут получать сообщения по запросу.
Издатель (publisher) может указать различные атрибуты сообщений при отправке сообщений. Некоторые атрибуты могут использоваться брокерами сообщений, в то время как другие атрибуты полностью непрозрачны и могут быть использованы только приложениями, получающими сообщения.
С точки зрения безопасности сеть ненадёжна, и приложения, обрабатывающие сообщения, могут дать сбой. В связи с этим AMQP включает концепцию подтверждения сообщений (message acknowledgements): когда сообщение отправляется из очереди потребителю, потребитель уведомляет брокера сообщений об этом, что может быть сделано автоматически или разработчиком приложения. Когда подтверждение сообщения включено, брокер сообщений не удаляет сообщение из очереди полностью, пока не получит подтверждение от потребителя.
В некоторых случаях, например, когда сообщение не может быть успешно маршрутизировано, сообщение может быть возвращено издателю и отброшено. Или, если брокер сообщений выполняет операцию задержки, сообщение будет помещено в так называемую очередь недоставленных сообщений. В этом случае издатель может выбрать некоторые параметры для обработки этих особых ситуаций.
Очередь, обмен и привязка вместе называются сущностями AMQP.
AMQP 0–9–1 — это программируемый протокол, в некотором смысле сущности AMQP и правила маршрутизации определяются самим приложением, а не брокером сообщений. Это включает в себя объявление очередей и обменов, определение их привязок и подписку на очереди и т. д., связанные с самим протоколом.
Хотя это позволяет разработчикам свободно выражать свои идеи, они должны учитывать потенциальные конфликты определений. Конечно, это редко происходит на практике, но если это произойдёт, это проявится в форме ошибки конфигурации (misconfiguration).
Приложения объявляют сущности AMQP, определяют необходимые схемы маршрутизации или удаляют ненужные сущности AMQP.
Обмен используется для отправки сообщений сущностью AMQP. После получения сообщения обмен направляет его в одну или ноль очередей. Используемый алгоритм маршрутизации определяется типом обмена и правилами привязки (bindings), которые называются правилами. Брокер сообщений предоставляет четыре типа обмена в AMQP 0–9–1:
| Name (тип обмена) | Default pre-declared names (предварительно объявленные имена по умолчанию) |
|---|---|
| Direct exchange (прямой обмен) | (пустая строка) и amq.direct |
| Fanout exchange (широковещательный обмен) | amq.fanout |
| Topic exchange (тематический обмен) | amq.topic |
| Headers exchange (обмен заголовками) | amq.match (и amq.headers в RabbitMQ) |
Помимо типа обмена, при объявлении обмена можно задать множество других атрибутов, наиболее важными из которых являются:
— Имя; — Долговечность (сообщения сохраняются после перезапуска брокера); — Автоматическое удаление (удаляется после завершения использования всеми связанными очередями); — Аргументы (зависят от самого брокера).
Обмены могут иметь два состояния: постоянное (durable) и временное (transient). Постоянные обмены сохраняются после перезапуска брокера, а временные — нет (они должны быть повторно объявлены после повторного подключения брокера). Однако не все сценарии приложений требуют постоянных обменов.
Обмен по умолчанию (default exchange) фактически является прямым обменом без имени (имя — пустая строка), предварительно объявленным брокером. У него есть особый атрибут, который делает его особенно полезным для простых приложений: каждая новая очередь автоматически привязывается к обмену по умолчанию, а ключ маршрутизации (routing key) совпадает с именем очереди.
Например, когда вы объявляете очередь с именем «search-indexing-online», брокер автоматически привязывает её к обмену по умолчанию с ключом маршрутизации «search-indexing-online». Таким образом, когда сообщение с ключом маршрутизации «search-indexing-online» отправляется на обмен по умолчанию, оно направляется в очередь «search-indexing-online». Другими словами, обмен по умолчанию выглядит так, как будто он может напрямую доставлять сообщения в очередь, хотя на самом деле он не выполняет никаких операций.
Прямой обмен (direct exchange) направляет сообщения в соответствующую очередь на основе ключа маршрутизации (routing key), указанного в сообщении. Прямой обмен используется для одноадресной маршрутизации (unicast routing), хотя он также может обрабатывать многоадресную маршрутизацию. Вот как это работает:
— Привязать очередь к обмену с определённым ключом маршрутизации; — Когда сообщение с ключом маршрутизации R отправляется на прямой обмен, оно направляется в связанную очередь с тем же ключом маршрутизации R.
Прямые обмены часто используются для циклического распределения задач среди рабочих. Однако важно понимать, что в AMQP 0–9–1 балансировка нагрузки сообщений происходит между потребителями, а не очередями. Здесь и далее представлен перевод текста на русский язык:
Fanout-обменник (fanout exchange) направляет сообщения всем очередям, которые к нему привязаны, игнорируя при этом ключ маршрутизации. Если N очередей привязано к fanout-обменнику, то при отправке сообщения в этот обменник он будет отправлять копии этого сообщения во все N очередей. Fanout используется для широковещательной маршрутизации сообщений.
Поскольку fanout-обменники отправляют копии сообщений во все очереди, к которым они привязаны, их сценарии использования очень похожи:
Пример fanout-обмена:

Topic-обменник (topic exchanges) направляет сообщение в одну или несколько очередей на основе соответствия между ключом маршрутизации сообщения и привязкой очереди к обмену. Topic-обменники часто используются для реализации различных моделей распределения/подписки и их вариаций. Они обычно используются для многоадресной маршрутизации сообщений (multicast routing).
У topic-обменников есть множество сценариев использования. В любом случае, когда возникает ситуация, требующая выборочного получения сообщений от нескольких потребителей/приложений (multiple consumers/applications), topic-обменник может быть рассмотрен.
Примеры использования:
Что такое режим привязки, мы рассмотрим позже, когда будем говорить о конкретной реализации протокола AMQP в RabbitMQ.
Иногда маршрутизация сообщений включает в себя несколько атрибутов, и в этом случае header-обменник (headers exchange) является решением. Он использует несколько свойств сообщения вместо ключа маршрутизации для создания правил маршрутизации.
Мы можем привязать очередь к header-обменнику и использовать несколько заголовков для этой привязки. В этом примере посредник должен получить дополнительную информацию от разработчика приложения, другими словами, он должен учитывать, нужно ли полностью или частично сопоставлять сообщение (message). «Дополнительная информация» — это параметр «x-match». Когда «x-match» установлен на «any», любое значение заголовка может соответствовать условию, а когда «x-match» установлено на «all», все значения заголовка должны совпадать.
Header-обменник можно рассматривать как другую форму прямого обмена. Он может работать так же, как прямой обмен, но правила маршрутизации основаны на свойствах заголовка, а не на ключе маршрутизации. Ключ маршрутизации должен быть строкой, в то время как свойства заголовка могут быть целыми числами, хеш-значениями (словарями) и т. д.
Очередь в AMQP (queue) похожа на другие очереди сообщений или очереди задач: они хранят сообщения, которые будут обработаны потребителями. Очереди имеют общие свойства с обменниками, но также имеют дополнительные свойства:
Очереди объявляются после создания. Если очередь ещё не существует, объявление создаст её. Если объявленная очередь уже существует и свойства совпадают, объявление не повлияет на существующую очередь. Если свойства объявленной очереди отличаются от существующей очереди, будет выдано исключение уровня канала с кодом ошибки 406.
Имя очереди может быть выбрано приложением (application) или автоматически сгенерировано посредником. Имя очереди может состоять максимум из 255 байт в кодировке utf-8. Если вы хотите, чтобы посредник сгенерировал имя очереди, присвойте параметру name пустое значение: в последующих методах (method) на том же канале мы можем использовать пустую строку для обозначения имени очереди, созданного ранее. Причина, по которой последующие методы могут получить правильное имя очереди, заключается в том, что канал молча запоминает последнее имя очереди, сгенерированное посредником.
Имена очередей, начинающиеся с «amq.», зарезервированы для внутреннего использования посредником. Попытка нарушить это правило при объявлении очереди приведёт к исключению уровня канала 403 (ACCESS_REFUSED).
Постоянные очереди (Durable queues) сохраняются на диске и остаются после перезапуска посредника. Не все сценарии и случаи требуют сохранения очередей.
Сохранение очередей не делает сообщения, направляемые в них, постоянными. Если посредник выйдет из строя и перезапустится, постоянные очереди будут повторно объявлены в процессе перезапуска, независимо от того, какие сообщения будут восстановлены только после сохранения.
Привязка (Binding) — это набор правил, которым следует посредник для направления сообщений (message) в очередь (queue). Чтобы указать посреднику «E» направлять сообщения в очередь «Q», «Q» должна быть привязана к «E». Операция привязки требует определения необязательного ключа маршрутизации (routing key) для некоторых типов обменников. Значение ключа маршрутизации заключается в выборе определённых сообщений из множества отправленных в обменник и направлении их в связанную очередь.
Благодаря наличию промежуточного слоя в виде обменника, многие сложные схемы маршрутизации, которые было бы трудно реализовать напрямую от отправителя к очереди, становятся возможными, избегая при этом большого количества повторяющихся усилий со стороны разработчиков приложений.
Если сообщение AMQP не может быть направлено в очередь (например, обменник не привязан к очереди), сообщение будет уничтожено на месте или возвращено отправителю. Как это обрабатывается, зависит от настроек сообщения отправителем.
Сообщения бесполезны, если они просто хранятся в очереди. Их ценность проявляется только тогда, когда они обрабатываются потребителем. В модели AMQP 0-9-1 есть два способа достижения этой цели:
Используя push API, приложение должно явно указать, какие сообщения из определённой очереди его интересуют и должны быть обработаны. Мы можем сказать, что приложение зарегистрировало потребителя или подписалось на очередь. К одной очереди можно привязать несколько потребителей, или она может иметь эксклюзивного потребителя (в этом случае другие потребители исключаются).
Каждый потребитель (подписчик) имеет уникальный идентификатор, называемый тегом потребителя. Он используется для отмены подписки на сообщения. Тег потребителя фактически является строкой.
Потребительские приложения (Consumer applications), используемые для приёма и обработки сообщений, иногда могут давать сбой или даже аварийно завершать работу. Кроме того, проблемы с сетью также могут вызывать различные проблемы. Это ставит перед нами сложную задачу: когда посредник удаляет сообщение? В спецификации AMQP 0–9–1 предлагаются два варианта:
Первый подход называется моделью автоматического подтверждения, а второй — моделью явного подтверждения. В явной модели потребительское приложение решает, когда отправлять подтверждение. Приложение может отправить подтверждение сразу после получения сообщения, сохранить необработанные сообщения и отправить подтверждение позже, или дождаться завершения обработки сообщения перед отправкой подтверждения.
Если потребитель выходит из строя до отправки подтверждения, посредник повторно направит сообщение другому потребителю. Если в данный момент нет доступных потребителей, посредник будет ждать следующего потребителя, зарегистрированного в этой очереди, прежде чем пытаться повторно направить сообщение.
После получения сообщения потребитель может успешно обработать его или потерпеть неудачу. Приложение может сообщить посреднику, что обработка сообщения не удалась по причине отклонения сообщения (или не могла быть завершена в это время). При отклонении сообщения приложение может указать посреднику, как обрабатывать сообщение — уничтожить его или повторно поместить в очередь. Когда в очереди есть только один потребитель, убедитесь, что сообщение не вызывает бесконечный цикл в одном потребителе из-за отклонения сообщения и выбора повторного помещения в очередь.
В сценариях с несколькими потребителями, совместно использующими одну очередь, полезно указать максимальное количество сообщений, которое каждый потребитель может принять до получения следующего подтверждения. Это может помочь в пакетной рассылке сообщений и повысить пропускную способность сообщений.
Обратите внимание, что RabbitMQ поддерживает только подтверждения на уровне канала, а не подтверждения на уровне соединения или на основе размера. ### Сообщение и полезная нагрузка (тело сообщения)
В модели AMQP сообщение (Message) — это объект с атрибутами (Attributes). Некоторые атрибуты настолько распространены, что AMQP 0-9-1 явно определяет их, и разработчикам приложений не нужно задумываться о том, что представляют собой имена этих атрибутов. Например:
Некоторые атрибуты используются AMQP-посредником, но большинство из них открыты для интерпретации приложениями-получателями. Некоторые атрибуты являются необязательными и называются заголовками сообщений. Они похожи на X-заголовки в HTTP-протоколе. Атрибуты сообщения должны быть определены при его публикации.
Помимо атрибутов, сообщение AMQP также содержит полезную нагрузку — Payload (фактические данные, которые несёт сообщение), которая рассматривается AMQP-посредниками как непрозрачный массив байтов. Посредник не проверяет и не изменяет полезную нагрузку. Сообщение может содержать только атрибуты без полезной нагрузки. Обычно оно использует формат данных, подобный JSON, для экономии места, а протоколы буфера и MessagePack сериализуют структурированные данные для использования в качестве полезной нагрузки сообщения. AMQP и его аналоги обычно используют поля «content-type» и «content-encoding» для идентификации полезной нагрузки сообщений, но это основано только на соглашении.
Сообщения могут быть опубликованы постоянным образом, и AMQP-посредники сохраняют их на диске. Если сервер перезагружается, система подтверждает, что полученные постоянные сообщения не были потеряны. Простое отправление сообщения постоянному обмену или маршрутизация к постоянной очереди не делает сообщение постоянным: это полностью зависит от режима сохранения самого сообщения (persistence mode). Публикация сообщения постоянным способом влияет на производительность (как и операции с базой данных, надёжность требует некоторых жертв производительности).
Из-за неопределённости сети и возможности сбоя приложения подтверждение получения (acknowledgement) становится очень важным. Иногда достаточно подтвердить, что потребитель получил сообщение, иногда подтверждение означает, что сообщение было проверено и обработано, например, данные были проверены и сохранены или проиндексированы.
Эта ситуация распространена, поэтому AMQP 0–9–1 имеет встроенную функцию подтверждения сообщений (message acknowledgements), которую потребители используют для подтверждения получения или обработки сообщений. Если приложение аварийно завершает работу (при этом соединение разрывается, так что AMQ-посредник также знает об этом), и подтверждение сообщения уже включено, но посредник ещё не получил подтверждения, то сообщение будет повторно помещено в очередь (и немедленно доставлено другому потребителю, если есть другие потребители в этой очереди).
Встроенная функция подтверждения сообщений в протоколе помогает разработчикам создавать мощное программное обеспечение.
AMQP 0–9–1 состоит из множества методов (methods). Метод — это операция, которая не имеет ничего общего с методами в объектно-ориентированном программировании. Методы AMQP разделены на классы. Здесь класс — это просто логическая группировка методов AMQP. Подробные сведения о методах AMQP можно найти в AMQP 0–9–1 Reference.
Рассмотрим класс обмена. Существует группа методов, связанных с операциями обмена. Эти методы включают:
Эти операции состоят из пар «запрос — ответ» (request — responses): exchange.declare и exchange.declare-ok, exchange.delete и exchange.delete-ok. Запрос отправляется клиентом, а ответ используется посредником для ответа на запрос.
Например, клиент запрашивает, чтобы посредник использовал метод exchange.declare для объявления нового обмена:
exchange.declare
Как показано на рисунке выше, метод exchange.declare имеет несколько параметров. Эти параметры позволяют клиенту указать имя обмена, тип, является ли он постоянным и т. д.
После успешной операции посредник отвечает методом exchange.declare-ok:
exchange.declare-ok
Метод exchange.declare-ok не имеет никаких параметров, кроме номера канала.
Аналогично, методы queue.declare и queue.declare-ok имеют серию событий, похожих на другие пары методов:
Не все методы AMQP имеют соответствующие «половинки». Многие (наиболее часто используемый — basic.publish) не имеют соответствующего «ответа», а некоторые (например, basic.get) имеют более одного соответствующего «ответа».
Обычно соединения AMQP являются постоянными. AMQP — это протокол прикладного уровня, который обеспечивает надёжную доставку через TCP. AMQP использует механизмы аутентификации и предоставляет TLS (SSL) защиту. Когда приложению больше не требуется подключаться к AMQP-посреднику, необходимо корректно освободить соединение AMQP, а не просто закрыть TCP-соединение.
Некоторым приложениям требуется установить несколько соединений с AMQP-посредником. В любом случае одновременное открытие нескольких TCP-соединений нецелесообразно, поскольку это потребляет слишком много системных ресурсов и усложняет настройку брандмауэра. AMQP 0–9–1 предоставляет каналы (channels) для управления несколькими подключениями. Канал можно рассматривать как облегчённое соединение, совместно использующее одно TCP-соединение.
В приложениях с несколькими потоками/процессами обычно каждый поток/процесс открывает свой собственный канал (channel), и эти каналы не могут использоваться совместно потоками/процессами.
Связь на конкретном канале полностью изолирована от связи на других каналах, поэтому каждому методу AMQP необходимо присвоить номер канала, чтобы клиент мог указать, для какого канала предназначен этот метод.
Для реализации нескольких изолированных сред (пользователей, групп пользователей, обменов, очередей и т. д.) на одном отдельном посреднике AMQP предоставляет концепцию виртуального хоста (virtual hosts — vhosts). Это похоже на концепцию виртуальных хостов на веб-серверах и обеспечивает полную изоляцию для сущностей AMQP. При установлении соединения клиент указывает, какой виртуальный хост использовать.
Подробные инструкции см. в официальной документации.
Руководство по API Java Client — RabbitMQ
RabbitMQ Java-клиент использует com.rabbitmq.client в качестве своего корневого пакета. Ключевые классы и интерфейсы включают:
Через интерфейс Channel можно выполнять операции над протоколом. Соединение используется для открытия каналов, регистрации событий обработки в жизненном цикле соединения и закрытия ненужных соединений. ConnectionFactory используется для создания экземпляров Connection и позволяет устанавливать такие свойства, как vhost, username и т. п. getConnection() throws IOException, TimeoutException { ConnectionFactory connectionFactory = new ConnectionFactory(); connectionFactory.setUsername(userName); connectionFactory.setPassword(password); connectionFactory.setVirtualHost(virtualHost); connectionFactory.setHost(host); connectionFactory.setPort(port); return connectionFactory.newConnection(); }
- **Инструменты класса**
```java
public class RabbitmqUtil {
private final String keyPrefix="spring.rabbitmq.";
private final YamlUtil yamlUtil;
private final RabbitmqClient rabbitmqClient;
public RabbitmqUtil(String ymlPath) {
this.yamlUtil =new YamlUtil(ymlPath);
this.rabbitmqClient=RabbitmqClient.builder()
.userName(yamlUtil.get(keyPrefix+"username"))
.password(yamlUtil.get(keyPrefix+"password"))
.host(yamlUtil.get(keyPrefix+"host"))
.port(Integer.valueOf(yamlUtil.get(keyPrefix+"port")))
.virtualHost(yamlUtil.get(keyPrefix+"virtual-host"))
.build();
}
public Connection getConnection() throws IOException, TimeoutException {
return rabbitmqClient.getConnection();
}
}
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Connection connection = rabbitmqUtil.getConnection();
Для локального узла RabbitMQ эти параметры имеют подходящие значения по умолчанию.
Если перед созданием соединения не указаны значения параметров, используются значения по умолчанию:
| Property | Default Value |
|---|---|
| Username | "guest" |
| Password | "guest" |
| Virtual host | "/" |
| Hostname | "localhost" |
| port | 5672 для нормального общения, 5671 для SSL-шифрованного общения |
Обратите внимание, что по умолчанию пользователь с правами гостя может подключаться только локально (https://www.rabbitmq.com/access-control.html). Это сделано для ограничения использования известных учётных данных в производственных системах.
# В конфигурационном файле установите loopback_users на none, тогда гость сможет подключаться удалённо.
loopback_users = none
public Channel createChannel() throws IOException {
log.info("Канал создаётся...");
return connection.createChannel();
}
Чтобы закрыть соединение RabbitMQ, достаточно просто закрыть канал и соединение:
public void close(){
log.info("Закрытие соединения с RabbitMQ...");
try {
//channel.close(); необязательно
connection.close();
} catch (IOException e) {
log.error("Ошибка при закрытии соединения: ",e);
}
}
Следует отметить, что закрытие канала не является обязательным действием. Канал будет автоматически закрыт при закрытии соединения.
Клиенты могут поддерживать соединения (https://www.rabbitmq.com/connections.html) в течение длительного времени. Протокол разработан и оптимизирован с учётом требований к длительным соединениям. Это означает, что создание нового соединения для каждой операции, такой как отправка сообщения, не рекомендуется, так как это приведёт к большому количеству сетевых обменов и накладных расходов.
Каналы (https://www.rabbitmq.com/channels.html), хотя и являются долгоживущими, могут быть закрыты из-за большого количества восстанавливаемых ошибок протокола. Срок службы канала короче, чем у соединения. Хотя открытие и закрытие канала для каждой операции не обязательно, это всё же возможно. В некоторых случаях предпочтительнее повторно использовать каналы.
Ошибки уровня канала (https://www.rabbitmq.com/channels.html#error-handling), такие как попытка потребления сообщений из несуществующей очереди, приведут к закрытию канала. После закрытия канал больше не может использоваться и не будет получать события сервера, такие как доставка сообщений. RabbitMQ будет регистрировать ошибки уровня канала и инициировать последовательность закрытия канала.
Узлы RabbitMQ могут хранить ограниченную информацию о клиентах:
AMQP 0-9-1 клиенты, включая RabbitMQ Java клиент, могут предоставить уникальный идентификатор, который будет отображаться в журнале сервера (https://www.rabbitmq.com/logging.html) и интерфейсе управления (https://www.rabbitmq.com/management.html) для удобства идентификации клиентов. После настройки журнала и интерфейса управления будут отображать предоставленный идентификатор. Идентификатор называется меткой соединения, которая используется для идентификации приложения или конкретного компонента приложения. Метка соединения является необязательной, но настоятельно рекомендуется её предоставить, поскольку это значительно упрощает некоторые задачи.
Метод newConnection предоставляет множество перегрузок, некоторые из которых позволяют установить метку для текущего подключения.
public Connection getConnection(String connectionName) throws IOException, TimeoutException {
connectionFactory.setUsername(userName);
connectionFactory.setPassword(password);
connectionFactory.setVirtualHost(virtualHost);
connectionFactory.setHost(host);
connectionFactory.setPort(port);
return connectionFactory.newConnection(connectionName);
}
``` **Обмен данными и очереди должны быть объявлены заранее.**
Проще говоря, цель объявления любого типа объектов — убедиться, что они существуют, и создать их при необходимости.
#### Эксклюзивная очередь для одного клиента
В следующем коде объявлен обмен данными и именованная очередь сервера RabbitMQ, а затем они связаны друг с другом:
```java
channel.exchangeDeclare("dhy-exchange", "direct", true);
//queueDeclare создаёт имя очереди
String queueName = channel.queueDeclare().getQueue();
channel.queueBind(queueName, "dhy-exchange", "dhy");
Это приведёт к активному объявлению следующих объектов, оба из которых можно настроить с помощью дополнительных параметров. Однако здесь им не присваиваются специальные параметры.
Обратите внимание, что это типичный способ объявления очереди, когда только один клиент планирует использовать её исключительно. Очередь будет автоматически очищена (автоматическое удаление). Если несколько клиентов планируют использовать определённую именованную очередь, то более подходящим будет следующий код:
channel.exchangeDeclare(exchangeName, "direct", true);
channel.queueDeclare(queueName, true, false, false, null);
channel.queueBind(queueName, exchangeName, routingKey);
Это приведёт к следующему объявлению:
Многие методы интерфейса Channel перегружены. Используемые здесь короткие перегрузки методов exchangeDeclare, queueDeclare и queueBind используют подходящие значения по умолчанию, которые проще в использовании. Конечно, есть также более длинные перегрузки с дополнительными параметрами, которые позволяют переопределить некоторые значения по умолчанию и получить более полный контроль.
Очереди и обмены данными могут быть объявлены пассивно. Пассивное объявление просто проверяет, существует ли соответствующий объект. Для успешно обнаруженной очереди пассивное объявление возвращает ту же информацию, что и активное объявление, то есть количество потребителей и сообщений в очереди.
Если соответствующий объект не существует, операция вызовет исключение на уровне канала. После этого канал нельзя будет использовать, и потребуется открыть новый канал. Обычно пассивные объявления выполняются с использованием временных одноразовых каналов.
Методы Channel#queueDeclarePassive и Channel#exchangeDeclarePassive используются для пассивного объявления. Ниже показано использование Channel#queueDeclarePassive:
AMQP.Queue.DeclareOk response = channel.queueDeclarePassive("queue-name");
response.getMessageCount();
response.getConsumerCount();
Возвращаемое значение метода Channel#exchangeDeclarePassive не содержит полезной информации. Пока метод возвращает правильно и не возникает исключения канала, это означает, что обмен данными уже существует.
Некоторые распространённые операции также имеют «неблокирующие» версии, которые не ждут ответа сервера. Например, следующий метод объявляет очередь и уведомляет сервер не отправлять ответ:
channel.queueDeclareNoWait(queueName, true, false, false, null);
Неблокирующие версии операций более эффективны, но менее безопасны, например, они больше полагаются на механизм сердцебиения для обнаружения неудачных операций. Если вы не уверены, начните с стандартных версий операций. Неблокирующие версии требуются только в случае сложных топологий (очередей, привязок).
Сущности и сообщения можно явно удалить:
channel.queueDelete("queue-name")
Или удалить, когда очередь пуста:
channel.queueDelete("queue-name", false, true)
Либо когда она больше не используется (нет потребителей, потребляющих из неё):
channel.queueDelete("queue-name", true, false)
Очередь можно очистить (удалить все сообщения):
channel.queuePurge("queue-name")
// Отправка сообщения на обмен данными
channel.basicPublish(EXCHANGE_NAME,ROUTING_KEY,null,"hello rabbitmq".getBytes(StandardCharsets.UTF_8));
Для более полного контроля можно использовать перегруженные варианты для указания обязательного атрибута или отправки сообщений с заданными свойствами.
channel.basicPublish(exchangeName, routingKey, mandatory,
MessageProperties.PERSISTENT_TEXT_PLAIN,
messageBodyBytes);
Обязательный означает обязательный.
Когда мы отправляем сообщение на обмен данными, если сообщение не может быть перенаправлено ни на одну из очередей, связанных с этим обменом данными, и издатель отправляет сообщение с обязательным атрибутом, установленным в false (по умолчанию это так), сообщение будет передано альтернативному обмену данными, при условии, что он существует; в противном случае будет записано предупреждение.
При отправке сообщения на обмен данными, если сообщение не может быть перенаправлено ни в одну из очередей, привязанных к этому обмену данными, и издатель отправляет сообщение с обязательным атрибутом, установленным в true, сообщение будет возвращено издателю, который должен предоставить обработчик обратного вызова для обработки возвращаемых сообщений.
Атрибут mandatory подробно описан в официальной документации:
Альтернативный обмен данными подробно описан в официальной документации:
Альтернативные обмены — RabbitMQ
Следующий пример отправляет сообщение, указывая режим доставки 2 (персистентный) и приоритет 1, а также тип содержимого («text/plain»). Используйте класс Builder для создания объекта свойств сообщения, который требует указания нескольких атрибутов, например:
// Отправка сообщения на обмен данными
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY,
new AMQP.BasicProperties.Builder()
.contentType("text/plain")
.deliveryMode(2)
.priority(1)
.userId("dhy")
.build(),
"hello2".getBytes(StandardCharsets.UTF-8));
Вот пример отправки сообщения с настраиваемыми заголовками:
Map<String, Object> headers = new HashMap<String, Object>();
headers.put("dhy", 18);
channel.basicPublish(exchangeName, routingKey,
new AMQP.BasicProperties.Builder()
.headers(headers)
.build(),
"hello3".getBytes(StandardCharsets.UTF-8));
Ниже приведён пример публикации сообщения с атрибутом срока действия:
Обратите внимание, что `BasicProperties` — это встроенный класс, который автоматически генерируется AMQP.
#### Канал и параллелизм
Следует избегать совместного использования канала между потоками. Приложение должно использовать отдельный канал для каждого потока, а не делиться каналом между несколькими потоками.
Хотя некоторые операции на канале можно безопасно выполнять параллельно, другие операции не следует выполнять таким образом, поскольку это может привести к ошибкам в кадрах при обмене данными по сети или вызвать проблемы с повторным подтверждением.
Выполнение параллельных операций публикации на общем канале приведёт к ошибкам кадров при обмене данными в сети, вызовет исключение протокола на уровне соединения и приведёт к тому, что прокси-сервер напрямую закроет соединение. Поэтому необходимо явно синхронизировать код приложения (необходимо вызывать `Channel#basicPublish` в ключевых частях).
Совместное использование канала между потоками также может помешать подтверждению издателя (https://www.rabbitmq.com/confirms.html). Лучше всего полностью избегать параллельной публикации на общих каналах, например, используя отдельный канал для каждого потока.
Можно также избежать параллельной отправки сообщений на общие каналы с помощью пула каналов: после того как поток завершит работу с определённым каналом, он должен вернуть его в пул, чтобы другие потоки могли повторно использовать его. Пул каналов можно рассматривать как особый вид решения для синхронизации. Рекомендуется использовать готовые библиотеки пулов, такие как Spring AMQP (https://projects.spring.io/spring-amqp/).
Канал потребляет ресурсы, и в большинстве приложений в одном процессе JVM редко открывается более нескольких сотен каналов. Представьте, что каждый поток в нашем приложении имеет свой собственный канал (поскольку один и тот же канал не должен использоваться для параллельных операций), и вы получите довольно большие накладные расходы в одной JVM с тысячами потоков, которые можно было бы избежать. Кроме того, небольшое количество быстрых издателей может легко перегрузить сетевой интерфейс и узлы прокси.
Классический антипаттерн, которого следует избегать, — открывать отдельный канал для каждой публикации сообщения. Каналы должны быть долговечными.
Безопасно, когда один поток обрабатывает сообщения, а другой поток отправляет сообщения на общий канал.
Распространение сервисных сообщений (описано ниже) осуществляется параллельно и обеспечивает фиксированный порядок для каждого канала. Механизм распространения использует `java.util.concurrent.ExecutorService` в каждом соединении. Все соединения, созданные с использованием `ConnectionFactory#setSharedExecutor`, могут совместно использовать пользовательский `executor`.
#### Получение сообщений через подписку (интерфейс обратного вызова)
Самый эффективный способ получения сообщений — использовать интерфейс `Consumer` для настройки подписки. Сообщения доставляются автоматически, когда они поступают, вместо того чтобы запрашивать их явно.
Когда вызываются методы, связанные с интерфейсом `Consumers`, подписка всегда ссылается на своего потребителя по метке. Метка потребителя может быть сгенерирована клиентом или сервером для идентификации потребителя. Чтобы RabbitMQ сгенерировал уникальный ярлык в пределах узла, можно использовать перегрузку `Channel#basicConsume`, которая не включает атрибут метки потребителя, или передать пустую строку в качестве метки потребителя и затем использовать значение, возвращаемое `Channel#basicConsume`. Метка потребителя также используется для отмены потребителя.
Разные экземпляры потребителей должны иметь разные метки потребителей. Крайне не рекомендуется иметь повторяющиеся метки потребителей на одном и том же соединении, так как это может вызвать проблемы с автоматическим восстановлением соединения (https://www.rabbitmq.com/api-guide.html#connection-recovery) и запутать данные мониторинга потребителей.
Простейший способ реализовать `Consumer` — создать подкласс `DefaultConsumer`. Экземпляр этого подкласса можно передать в качестве параметра при вызове `basicConsume` для установки подписки:
```java
@Slf4j
public class Publisher implements Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.prepareChannel();
channel.basicPublish(EXCHANGE_NAME,ROUTING_KEY,null,"你好,我是生产者".getBytes(StandardCharsets.UTF_8));
log.info("发送消息...");
} catch (IOException | TimeoutException e) {
log.error("出现异常: ",e);
}
}
}
@Slf4j
public class Consumer implements Runnable{
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.prepareChannel();
//不开启自动应答
boolean autoAck = false;
channel.basicConsume(QUEUE_NAME, autoAck, "myConsumerTag",
new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body)
throws IOException
{
String routingKey = envelope.getRoutingKey();
String contentType = properties.getContentType();
long deliveryTag = envelope.getDeliveryTag();
//手动确认消息收到
channel.basicAck(deliveryTag, false);
log.info("接收到消息: {} , 路由key为: {} ,类型为: {}",new String(body),routingKey,contentType);
}
});
} catch (IOException | TimeoutException e) {
log.error("出现异常: ",e);
}
}
}
Тестирование:
Thread consumer = new Thread(new Consumer(),"消费者线程");
Thread publisher = new Thread(new Publisher(),"生产者线程");
consumer.start();
publisher.start();
``` Здесь, поскольку мы установили `autoAck = false`, необходимо вручную подтверждать сообщения, доставленные потребителю (`Consumer`). Самый простой способ — сделать это в `handleDelivery`, как было описано выше.
Более сложные потребители должны переопределить другие методы. В частности, следует отметить, что при закрытии канала или соединения вызывается `handleShutdownSignal`, а `handleConsumeOk` передаётся потребителю перед вызовом других обратных вызовов потребителя.
```java
@Override
public void handleConsumeOk(String consumerTag) {
this._consumerTag = consumerTag;
}
Потребители также могут быть уведомлены о том, был ли потребитель отменён явно или неявно, путём реализации методов handleCancelOk и handleCancel.
Вы можете явно отменить конкретного потребителя с помощью Channel.basicCancel, указав тег потребителя.
channel.basicCancel(consumerTag);
Передаётся тег потребителя.
Как и издатель, здесь также необходимо учитывать параллельную безопасность потребителей.
Обратные вызовы потребителей выполняются в отдельном пуле потоков, который отличается от пула, используемого для инициализации канала. Это означает, что потребители могут безопасно вызывать такие блокирующие методы, как Channel#queueDeclare и Channel#basicCancel.
Каждый канал имеет свой собственный пул планирования. Для большинства распространённых сценариев, когда на каждый канал приходится один потребитель, это означает, что потребители не влияют друг на друга. Однако следует помнить, что если в канале несколько потребителей, долго работающий потребитель может блокировать планирование обратных вызовов других потребителей в этом канале.
Попробуйте извлечь сообщение. Если сообщение существует, оно возвращается, в противном случае возвращается значение null. Поэтому большинству клиентов необходимо постоянно опрашивать, чтобы получить сообщение, поэтому этот метод не рекомендуется.
Используйте Channel.basicGet для извлечения («извлечения») сообщений. Возвращаемое значение представляет собой объект GetResponse, содержащий информацию об атрибутах и теле сообщения.
@Slf4j
public class Consumer implements Runnable{
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.prepareChannel();
boolean autoAck = false;
while(true){
GetResponse response = channel.basicGet(QUEUE_NAME, autoAck);
if (response == null) {
log.info("当前无消息....");
} else {
byte[] body = response.getBody();
log.info("msg: {}",new String(body));
channel.basicAck(response.getEnvelope().getDeliveryTag(),false);
break;
}
}
} catch (IOException | TimeoutException e) {
log.error("出现异常: ",e);
}
}
}
ChannIN класс на самом деле очень прост:
@Override
public GetResponse basicGet(String queue, boolean autoAck)
throws IOException
{
validateQueueNameLength(queue);
//构造命令
AMQCommand replyCommand = exnWrappingRpc(new Basic.Get.Builder()
.queue(queue)
.noAck(autoAck)
.build());
//命令执行
Method method = replyCommand.getMethod();
//判断执行结果
if (method instanceof Basic.GetOk) {
Basic.GetOk getOk = (Basic.GetOk)method;
Envelope envelope = new Envelope(getOk.getDeliveryTag(),
getOk.getRedelivered(),
getOk.getExchange(),
getOk.getRoutingKey());
BasicProperties props = (BasicProperties)replyCommand.getContentHeader();
byte[] body = replyCommand.getContentBody();
int messageCount = getOk.getMessageCount();
metricsCollector.consumedMessage(this, getOk.getDeliveryTag(), autoAck);
//有结果,那么构造成GetResponse后返回
return new GetResponse(envelope, props, body, messageCount);
} else if (method instanceof Basic.GetEmpty) {
//没有消息,那么返回的结果为空,会返回null
return null;
} else {
throw new UnexpectedMethodError(method);
}
}
Если опубликованное сообщение имеет установленный флаг mandatory, но не может быть успешно маршрутизировано, посредник вернёт его отправившему клиенту (через команду AMQP.Basic.Return).
Клиент может получать эти уведомления о возврате, реализовав интерфейс ReturnListener и вызвав Channel.addReturnListener. Если клиент не настроил обратный вызов для конкретного канала, соответствующие сообщения будут молча отброшены. Перевод текста на русский язык:
Публикация сообщений
Например, клиент опубликовал сообщение с обязательным флагом. Это сообщение устанавливает тип обмена как «прямой», но обмен не привязан к очереди, и в этом случае будет вызван обратный вызов прослушивания.
Thread publisher = new Thread(new Publisher(),"производитель потока");
publisher.start();
Логирование:
19:52:56.103 [производитель потока] INFO com.dhy.util.RabbitmqUtil — соединение установлено 19:52:56.232 [производитель потока] INFO com.dhy.util.RabbitmqUtil — установлено соединение, имя соединения dhy-connection 19:52:56.234 [производитель потока] INFO com.dhy.util.RabbitmqUtil — создание канала... 19:52:56.369 [производитель потока] INFO com.dhy.util.RabbitmqUtil — подготовка канала... 19:52:56.374 [производитель потока] INFO com.dhy.Publisher — отправка сообщения... 19:52:56.403 [AMQP Connection 110.40.155.17:5672] WARN com.dhy.RouteFailListener — информация о сообщении об ошибке маршрутизации: replyCode=312, replyText=NO_ROUTE, exchange=dhy-exchange, routingKey=unknown, body=你好, я производитель
Потребительский пул операций
По умолчанию потребители используют новый пул потоков ExecutorService для распределения.
Можно видеть, что размер пула потребителей по умолчанию равен удвоенному количеству ядер процессора.
Если требуется больший контроль, можно использовать newConnection() для применения ExecutorService в качестве замены. Это пример использования большего пула потоков:
ExecutorService es = Executors.newFixedThreadPool(20);
Connection conn = factory.newConnection(es);
Когда соединение закрывается, предоставленный ExecutorService также выполняет shutdown(), но пользовательский ExecutorService (как показано выше) не выполняет shutdown(). Клиент, предоставляющий собственный ExecutorService, должен гарантировать, что он в конечном итоге будет закрыт (т. е. вызвать метод shutdown()), иначе пул потоков повлияет на завершение работы JVM.
Один и тот же executor service может совместно использоваться несколькими подключениями или постоянно повторно использоваться и повторно подключаться, но после закрытия его нельзя использовать снова.
Эту функцию следует рассматривать только в том случае, если обработка обратных вызовов потребителей серьёзно перегружена. Если нет или требуется выполнить лишь небольшое количество обратных вызовов потребителя, то предоставленного потока достаточно. Даже если иногда активность потребителей резко возрастает, первоначальная нагрузка невелика, а ресурсы потока не могут быть расширены бесконечно.
Использование списка хостов
Передача массива адресов в newConnection() не вызывает проблем. Адрес — это простой класс пакета com.rabbitmq.client, который содержит компоненты хоста и порта.
Пример:
Address[] addrArr = new Address[]{ new Address(hostname1, portnumber1), new Address(hostname2, portnumber2)};
Connection conn = factory.newConnection(addrArr);
Это сначала попытается подключиться к hostname1:portnumber1, а в случае неудачи попытается hostname2:portnumber2. Возвращаемый объект соединения является первым успешным элементом массива (если не было выброшено IOException). Это точно так же, как установка хоста и порта по отдельности, а затем последовательное вызов factory.newConnection() до успешного выполнения.
Если также предоставляется ExecutorService (в factory.newConnection (es, addrArr)), то пул потоков также соответствует первому успешному соединению.
Использование интерфейса AddressResolver для реализации обнаружения служб
Мы можем использовать интерфейс AddressResolver для изменения алгоритма разрешения конечных точек при подключении:
Connection conn = factory.newConnection(addressResolver);
Интерфейс AddressResolver похож на:
public interface AddressResolver {
List<Address> getAddresses() throws IOException;
}
Как и в списке хостов, сначала будет предпринята попытка первого адреса в списке, и если это не удастся, будет предпринята вторая попытка, пока не будет достигнут успех.
Если одновременно также предоставляется ExecutorService (при использовании factory.newConnection (es, addrArr)), то пул потоков также будет соответствовать первому успешному подключению.
AddressResolver — лучший способ реализовать настраиваемое обнаружение служб, чтобы клиенты могли автоматически подключаться к узлам, которые были доступны при первом запуске.
Java-клиент поставляется со следующими реализациями (см. javadoc):
Значение по умолчанию имеет только один адрес хоста, который использует DnsRecordIpAddressResolver.
Метод getAddresses будет вызываться в методе newConnection.
Свойство autoDelete
Семь моделей RabbitMQ
Простая модель очереди
Эта модель очень проста: производитель напрямую помещает сообщение в очередь, а потребитель извлекает сообщение из очереди для потребления.
На самом деле сообщение помещается в прямой обмен по умолчанию, а затем этот обмен привязывается к указанной очереди. Потребитель:
channel.basicConsume(QUEUE_NAME, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
log.info("Сообщение: {}", new String(body));
}
});
Основная идея рабочих очередей (или очередей задач) заключается в том, чтобы избежать немедленного выполнения ресурсоёмких задач и ожидания их завершения. Вместо этого мы планируем задачи на более позднее выполнение. Мы упаковываем задачи в сообщения и отправляем их в очередь. Фоновые рабочие процессы извлекают задачи и выполняют задания. Когда есть несколько рабочих потоков, эти рабочие потоки совместно обрабатывают эти задачи.
На этой диаграмме сообщения всё ещё помещаются в основной обменник по умолчанию, и по сравнению с простой очередью количество потребителей увеличилось, поэтому сообщение должно быть распределено. Это стало нашей заботой.
RabbitMQ tutorial — Work Queues — RabbitMQ
Код потребителя не меняется, код производителя также не меняется. Нам просто нужно запустить двух потребителей одновременно, а затем вручную отправить сообщения в очередь через веб-интерфейс для тестирования:
Мы отправили 6 сообщений. Давайте посмотрим, сколько сообщений получил каждый потребитель:
По умолчанию RabbitMQ будет отправлять каждое сообщение следующему потребителю по очереди. В среднем каждый потребитель получит одинаковое количество сообщений. Этот механизм распределения сообщений называется циклическим перебором.
— Потребителю может потребоваться некоторое время для завершения одной задачи. Если один из потребителей обрабатывает длинную задачу и завершает только часть её, что произойдёт? RabbitMQ немедленно помечает это сообщение как удалённое после того, как оно было передано потребителю. В этом случае, если потребитель внезапно выйдет из строя, мы потеряем сообщение, которое обрабатывается, и последующие сообщения, отправленные этому потребителю, поскольку он не сможет их получить.
— Чтобы гарантировать, что сообщения не будут потеряны во время передачи, RabbitMQ вводит механизм подтверждения сообщений, который работает следующим образом: после получения и обработки сообщения потребитель сообщает RabbitMQ, что он обработал его, и RabbitMQ удаляет это сообщение.
Если потребитель не отвечает на определённое сообщение в течение указанного времени ожидания, текущий канал принудительно закрывается и генерируется исключение PRECONDITION_FAILED уровня канала.
PRECONDITION_FAILED
Время ожидания по умолчанию составляет 30 минут.
Сообщения считаются успешно переданными сразу после отправки. Этот режим требует баланса между высокой пропускной способностью и безопасностью данных, потому что, если сообщение получено до того, как потребитель его получит, соединение или канал на стороне потребителя могут быть закрыты, и сообщение будет потеряно. Конечно, с другой стороны, этот режим позволяет потребителю передавать перегруженные сообщения без ограничения количества передаваемых сообщений. Конечно, это может привести к тому, что эти сообщения будут накапливаться у потребителя, в конечном итоге вызывая переполнение памяти, и, наконец, эти потребительские потоки будут убиты операционной системой, поэтому этот режим подходит только тогда, когда потребитель может эффективно обрабатывать сообщения с определённой скоростью.
Рекомендуется не использовать автоматическое подтверждение.
// Первый параметр: подтвердить какое сообщение
// Второй параметр: включить ли пакетное подтверждение
channel.basicAck(envelope.getDeliveryTag(), false);
Как работает пакетное подтверждение?
Можно подтвердить несколько сообщений вручную, чтобы уменьшить сетевой трафик. Это делается путём установки нескольких полей метода подтверждения в значение true.
Когда поле пакетного подтверждения установлено в значение true, все сообщения от delivery_tag до delivery_tag будут подтверждены, например, предположим, что на канале Ch есть неподтверждённые сообщения с тегами доставки 5, 6, 7 и 8, когда подтверждение кадра достигает этого канала, delivery_tag установлен на 8 и поле пакетного подтверждения установлено на true, тогда все теги доставки от 5 до 8 будут подтверждены.
Если поле пакетного подтверждения установлено в false, то 5, 6 и 7 по-прежнему не будут подтверждены.
// Первый параметр: отклонить какое сообщение
// Второй параметр: повторно поставить ли отклонённое сообщение в очередь
channel.basicReject(envelope.getDeliveryTag(), true);
// Первый параметр: отклонить какое сообщение
// Второй параметр: пакетный отказ
// Третий параметр: повторно поставить ли отклонённое сообщение в очередь
// Метод basic.nack может отклонять или повторно ставить в очередь несколько сообщений за раз. В этом его отличие от basic.reject.
channel.basicNack(envelope.getDeliveryTag(), true, true);
Потребитель не может обработать доставленное сообщение немедленно, но другие экземпляры могут это сделать. В этом случае может потребоваться повторно поставить сообщение в очередь, чтобы другой потребитель мог принять и обработать его. basic.reject и basic.nack — это два протокола, которые можно использовать для этой цели.
Этот тип сообщения может быть отброшен, повторно поставлен в очередь или мёртв. Это контролируется полем requeue. Когда это поле установлено в true, брокер будет использовать указанный тег доставки для повторной постановки в очередь всех (или нескольких) доставок. Или, если это поле установлено в false (и настроено), сообщение будет перенаправлено в очередь недоставленных сообщений, в противном случае оно будет отброшено.
При повторной постановке сообщения в очередь оно помещается обратно в исходную позицию в своей очереди, если это возможно. Если это невозможно (из-за одновременной доставки другим потребителям), сообщение помещается ближе к началу очереди.
Дополнительные сведения о подтверждении сообщений см. в официальной документации:
Consumer Acknowledgements and Publisher Confirms — RabbitMQ.
Для сохранения сообщений необходимо сначала сохранить соответствующую очередь, а затем пометить сообщение как постоянное при публикации сообщения.
channel.basicPublish("", QUEUE_NAME, true,
// Добавляем постоянные свойства к сообщению
MessageProperties.PERSISTENT_TEXT_PLAIN, ("серийный номер" + i).getBytes(StandardCharsets.UTF_8));
Обратите внимание!
Маркировка сообщения как постоянного не гарантирует, что сообщение не будет потеряно. Хотя он сообщает RabbitMQ сохранить сообщение на диск, здесь всё ещё существует промежуток времени, когда сообщение готово к сохранению на диске, но ещё не сохранено, и сообщение всё ещё находится в кэше. На самом деле оно ещё не записано на диск. Гарантия постоянства не очень сильна, но для нашей простой очереди задач она уже достаточно хороша. Если вам нужна более сильная стратегия постоянства, вы можете использовать подтверждение издателя. Для решения этой проблемы мы можем использовать базовый метод Qos с предустановленным счётчиком = 1. Это говорит RabbitMQ не отправлять сразу несколько сообщений одному работнику. Вместо этого, пока не обработано и подтверждено предыдущее сообщение, новое сообщение отправляется другому свободному работнику.
channel.basicQos(1)
Пример: потребительская программа вызывает channel.basicQos (5), а затем подписывается на определённую очередь для потребления. RabbitMq сохраняет список потребителей, каждый раз, когда отправляется сообщение, счётчик увеличивается на единицу для соответствующего потребителя. Когда счётчик достигает 5, RabbitMQ больше не будет отправлять сообщения этому потребителю. После того как потребитель подтвердит обработку сообщения, RabbitMQ уменьшит счётчик на 1, и потребитель сможет продолжать получать сообщения до тех пор, пока счётчик снова не достигнет верхнего предела. Этот механизм можно сравнить с «скользящим окном» в TCP/IP.
Публикация и подписка
RabbitMQ tutorial — Publish/Subscribe — RabbitMQ
Сообщения из обмена отправляются всем очередям, связанным с этим обменом, игнорируя routingKey.
В приведённом примере обе очереди являются временными очередями, то есть очереди создаются сервером и связаны с уникальным клиентом. При отключении клиента очередь автоматически удаляется.
Режим публикации и подписки очень прост, вот пример:
public static final String EXCHANGE_NAME="dhy-exchange";
public static final String QUEUE_NAME="dhy-queue";
public static final String ROUTING_KEY="dhy";
public static final String TEMP_QUEUE="";
public static final String UNKNOWN_ROUTING_KEY ="unknown";
public Channel prepareChannel() throws IOException, TimeoutException {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml","dhy-connection");
Channel channel = rabbitmqUtil.createChannel();
//объявление обмена и очереди
//неустойчивый, не эксклюзивный, неавтоматически удаляемый «ветвистый» обмен
channel.exchangeDeclare(EXCHANGE_NAME, FANOUT, false);
//очередь с заданным именем, неустойчивая, не эксклюзивная, не автоматически удаляемая
channel.queueDeclare(TEMP_QUEUE, false, false, false, null);
//привязка обмена и очереди
channel.queueBind(TEMP_QUEUE, EXCHANGE_NAME, ROUTING_KEY);
log.info("Подготовка канала...");
return channel;
}
Потребитель:
Производитель:
Отправка сообщения:
Режим маршрутизации
RabbitMQ tutorial — Routing — RabbitMQ
Обмен направляет сообщения в очереди на основе ключа маршрутизации.
Можно представить отношения между обменом и очередями как карту:
Map<List<RouteKey>,List<Queue>> exchange;
Когда обмен получает ключ маршрутизации, ему нужно знать, какие очереди должны получить это сообщение. Как это сделать?
List<Queue> queues=exchange.get(Arrays.asList(key1,key2...))
Несколько ключей маршрутизации могут совместно указывать на одну и ту же очередь, или один ключ маршрутизации может указывать на несколько очередей, поэтому это отношение «многие ко многим».
Вот пример использования:
/**
* Прямой обмен
*/
public static final String DIRECT_EXCHANGE="direct";
/**
* Очередь 1
*/
public static final String QUEUE_ONE="queue_one";
public static final String ONE_KEY="one";
/**
* Очередь 2
*/
public static final String QUEUE_TWO="queue_two";
public static final String TWO_KEY="two";
Код производителя:
@Slf4j public class Publisher implements Runnable { @Override public void run() { try { RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml"); Channel channel = rabbitmqUtil.createChannel(); //объявить прямой обмен channel.exchangeDeclare(DIRECT_EXCHANGE, DIRECT,false); //отправить два сообщения с ключами маршрутизации one и two channel.basicPublish(DIRECT_EXCHANGE,ONE_KEY,false, null,"one".getBytes(StandardCharsets.UTF_8)); channel.basicPublish(DIRECT_EXCHANGE,TWO_KEY,false, null,"two".getBytes(StandardCharsets.UTF_8)); } catch (IOException | TimeoutException e ) { log.error("Возникла ошибка: ",e); } } } ```
@Slf4j
public class ConsumerOne implements Runnable{
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try
``` ```
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
channel.queueDeclare(QUEUE_ONE,false,false,false,null);
// 绑定别忘了
channel.queueBind(QUEUE_ONE,DIRECT_EXCHANGE,ONE_KEY);
channel.basicConsume(QUEUE_ONE,true,new DefaultConsumer(channel) {
@SneakyThrows
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
log.info("消息为: {}",new String(body));
}
});
} catch (IOException | TimeoutException e) {
log.error("出现异常: ",e);
}
@Slf4j
public class ConsumerTwo implements Runnable{
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
channel.queueDeclare(QUEUE_TWO,false,false,false,null);
channel.queueBind(QUEUE_TWO,DIRECT_EXCHANGE,TWO_KEY);
channel.basicConsume(QUEUE_TWO,true,new DefaultConsumer(channel){
@SneakyThrows
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
log.info("消息为: {}",new String(body));
}
});
} catch (IOException | TimeoutException e) {
log.error("出现异常: ",e);
}
}
}
Thread consumer1 = new Thread(new ConsumerOne(),"消费者1");
Thread consumer2 = new Thread(new ConsumerTwo(),"消费者2");
Thread publisher = new Thread(new Publisher(),"生产者");
consumer1.start();
consumer2.start();
Thread.sleep(1000);
publisher.start();
Основная тема — это режим тем.
RabbitMQ tutorial — Topics — RabbitMQ
Режим тем основан на прямом обмене сообщениями, но у прямого обмена сообщениями есть недостаток — он не может выполнять частичное сопоставление, необходимо точно указать ключ маршрута. Поэтому существует режим тем, который обеспечивает функцию частичного сопоставления.
Далее описывается, как именно выполняется частичное сопоставление:
Например, в соответствии с приведённой выше диаграммой:
Сравнение:
Практический пример:
Подготовка констант:
/**
* Тема обмена
*/
public static final String TOPIC_EXCHANGE="topic";
public static final String Q1_QUEUE="Q1";
public static final String Q1_ROUTE_KEY="*.orange.*";
public static final String Q2_QUEUE="Q2";
public static final String Q2_ROUTE_KEY1="*.*.rabbit";
public static final String Q2_ROUTE_KEY2="lazy.#";
Подготовка производителя:
@Slf4j
public class Publisher implements Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
// Объявляем тему обмена
channel.exchangeDeclare(TOPIC_EXCHANGE, TOPIC,false);
channel.basicPublish(TOPIC_EXCHANGE,"apple.orange.banana",false, null,"q1".getBytes(StandardCharsets.UTF_8));
channel.basicPublish(TOPIC_EXCHANGE,"dog.pig.rabbit",false, null,"q21".getBytes(StandardCharsets.UTF_8));
channel.basicPublish(TOPIC_EXCHANGE,"lazy.lazy1",false, null,"q22".getBytes(StandardCharsets.UTF_8));
} catch (IOException |
``` **Потребитель один**
@Slf4j public class ConsumerOne implements Runnable { @Override public void run() { RabbitmqUtil rabbitmqUtil = null; try { rabbitmqUtil = new RabbitmqUtil("application.yml"); Channel channel = rabbitmqUtil.createChannel(); channel.queueDeclare(Q1_QUEUE, false, false, false, null); channel.queueBind(Q1_QUEUE, TOPIC_EXCHANGE, Q1_ROUTE_KEY); channel.basicConsume(Q1_QUEUE, true, new DefaultConsumer(channel) { @SneakyThrows @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { log.info("Сообщение: {}", new String(body)); } }); } catch (IOException | TimeoutException e) { log.error("Возникло исключение: ", e); } } }
**Потребитель два**
@Slf4j public class ConsumerTwo implements Runnable { @Override public void run() { RabbitmqUtil rabbitmqUtil = null; try { rabbitmqUtil = new RabbitmqUtil("application.yml"); Channel channel = rabbitmqUtil.createChannel(); channel.queueDeclare(Q2_QUEUE, false, false, false, null); // Привязываем два маршрута к очереди Q2 channel.queueBind(Q2_QUEUE, TOPIC_EXCHANGE, Q2_ROUTE_KEY1); channel.queueBind(Q2_QUEUE, TOPIC_EXCHANGE, Q2_ROUTE_KEY2); channel.basicConsume(Q2_QUEUE, true, new DefaultConsumer(channel) { @SneakyThrows @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { log.info("Сообщение: {}", new String(body)); } }); } catch (IOException | TimeoutException e) { log.error("Возникло исключение: ", e); } } }
* * *
**Тестирование**
Thread consumer1 = new Thread(new ConsumerOne(), "Потребитель 1"); Thread consumer2 = new Thread(new ConsumerTwo(), "Потребитель 2"); Thread publisher = new Thread(new Publisher(), "Издатель"); consumer1.start(); consumer2.start(); publisher.start();
* * *
### RPC-режим
RPC — это способ межпроцессного взаимодействия, в котором производитель отправляет сообщение, а потребитель обрабатывает его. В предыдущих примерах мы рассмотрели однонаправленный режим обмена сообщениями.
Но что делать, если потребитель должен отправить ответ производителю?
Не стоит беспокоиться, RabbitMQ уже подготовил всё необходимое для этого. Давайте рассмотрим, как это работает.
На RabbitMQ RPC реализуется легко: клиент отправляет запрос, сервер отвечает на него. Чтобы получить ответ, необходимо указать адрес «обратного вызова». Можно использовать стандартную очередь.
// Создаём временную очередь String queue = channel.queueDeclare().getQueue(); AMQP.BasicProperties basicProperties = new AMQP.BasicProperties.Builder() // Указываем адрес обратного вызова .replyTo(queue).build(); channel.basicPublish("", "rpc_queue", basicProperties, "Вызов RPC".getBytes(StandardCharsets.UTF_8));
> **Свойства сообщения:**
>
> AMQP 0-9-1 определяет 14 свойств, которые могут быть связаны с сообщением. Большинство из них используются редко, но некоторые важны:
>
> - deliveryMode: указывает, является ли сообщение постоянным (значение 2) или непостоянным (любое другое значение).
> - contentType: описывает тип кодировки MIME. Например, для JSON рекомендуется установить значение application/json.
> - replyTo: обычно используется для указания адреса обратного вызова.
> - correlationId: связывает ответ RPC с запросом.
* * *
#### Correlation Id
Для каждого запроса RPC создаётся отдельная очередь обратного вызова. Это неэффективно, поэтому лучше создавать отдельную очередь для каждого клиента.
Однако возникает проблема: как определить, какой ответ принадлежит какому запросу, когда мы получаем их в очереди обратного вызова? Для этого используется свойство correlationId. Мы присваиваем ему уникальное значение для каждого запроса. Позже, при получении сообщения в очереди обратного вызова, мы проверяем это свойство и сопоставляем ответ с соответствующим запросом. Если мы видим неизвестное значение correlationId, то можем безопасно игнорировать это сообщение — оно не относится к нашему запросу.
Вы можете спросить, почему мы должны игнорировать неизвестные сообщения в очереди обратного вызова вместо того, чтобы выдавать ошибку? Это связано с тем, что на сервере может возникнуть конфликт. Хотя это маловероятно, сервер RPC может умереть сразу после отправки ответа, но до отправки подтверждения запроса. Если это произойдёт, перезапущенный сервер RPC снова обработает этот запрос. Вот почему на стороне клиента мы должны корректно обрабатывать повторяющиеся ответы, и RPC должен быть идемпотентным. **Rpc конкретный рабочий процесс выглядит следующим образом:**
- Для RPC запроса клиент отправляет сообщение с двумя свойствами: replyTo (устанавливается в качестве анонимной эксклюзивной очереди только для запроса) и correlationId (устанавливается как уникальное значение для каждого запроса).
- Запрос отправляется в очередь rpc_queue.
- Рабочий поток RPC (также называемый сервером) ожидает запросов в этой очереди. Когда появляется запрос, он выполняет задание и использует поле replyTo для отправки сообщения с результатами обратно клиенту.
- Клиент ожидает ответа в очереди ответов. Когда приходит сообщение, оно проверяет свойство correlationId. Если оно совпадает со значением в запросе, ответ возвращается в приложение.
**Практическая демонстрация использования:**
*Клиент:*
```java
/**
* Отправляет запрос на сервер и затем принимает ответные данные от сервера.
*/
@Slf4j
public class Client implements Runnable {
final BlockingQueue<String> response = new ArrayBlockingQueue<>(1);
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel client = rabbitmqUtil.createChannel();
String rpcQueue = client.queueDeclare().getQueue();
log.info("Имя очереди rpc: {}", rpcQueue);
String uid = UUID.randomUUID().toString();
AMQP.BasicProperties props = new AMQP.BasicProperties().builder()
// Идентификатор корреляции отправленного сообщения
.correlationId(uid)
// Сообщение отправляется в какую очередь
.replyTo(rpcQueue).build();
// Использование по умолчанию обменника, ключ маршрутизации — rpc, при сбое маршрутизации будет вызван интерфейс обратного вызова сообщений
client.basicPublish("", "rpc_queue", true, props, "rpc".getBytes(StandardCharsets.UTF_8));
// Мониторинг очереди ответов на сообщения — возвращает метку текущего потребителя
String ctag = client.basicConsume(rpcQueue, true, (consumerTag, delivery) -> {
if (delivery.getProperties().getCorrelationId().equals(uid)) {
response.offer(new String(delivery.getBody()));
}
}, consumerTag -> {});
// Блокировка до тех пор, пока в очереди не появится сообщение
String res = response.take();
// Отмена текущего потребителя — временная очередь будет удалена
client.basicCancel(ctag);
log.info("Получен результат rpc: {}", res);
} catch (IOException | TimeoutException | InterruptedException e) {
log.error("Возникла исключительная ситуация: ", e);
}
}
}
Сервер:
@Slf4j
public class Server implements Runnable {
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel server = rabbitmqUtil.createChannel();
// Объявление очереди связи между клиентом и сервером, это не очередь обратного вызова
server.queueDeclare(getRpc_queue(), false, false, false, null);
// Очистка сообщений в очереди
server.queuePurge(getRpc_queue());
// Максимальное количество сообщений — 1
server.basicQos(1);
// Сообщения из очереди rpc_queue, отправленные клиентом
server.basicConsume(getRpc_queue(),false,
// Потребление сообщений из очереди
(consumerTag, delivery) ->{
// Подготовка свойств для ответа
AMQP.BasicProperties props = new AMQP.BasicProperties().builder()
// Идентификатор корреляции отправляемого сообщения
.correlationId(delivery.getProperties().getCorrelationId())
.build();
String reply = new String(delivery.getBody());
log.info("Сообщение клиента: {}", reply);
if(reply.equals("rpc")){
// Отправка ответа
server.basicPublish("",delivery.getProperties().getReplyTo(),props,"respect!!!".getBytes(StandardCharsets.UTF_8));
// Ответ клиенту на отправленное сообщение
server.basicAck(delivery.getEnvelope().getDeliveryTag(),false);
}
},consumerTag -> {});
} catch (IOException | TimeoutException e) {
e.printStackTrace();
}
}
private String getRpc_queue() {
return "rpc_queue";
}
}
Тестирование:
Thread client = new Thread(new Client());
Thread server=new Thread(new Server());
client.start();
server.start();
Вопрос об эксклюзивности очередей:
Если внимательно прочитать статью, у некоторых читателей может возникнуть вопрос: почему сервер всё ещё может отправлять сообщения в эту временную очередь, хотя она является эксклюзивной для текущего клиента?
Эксклюзивность очереди основана на видимости соединения. Различные каналы одного и того же соединения могут одновременно получать доступ к одной и той же эксклюзивной очереди, созданной этим соединением. RabbitMQ автоматически удаляет эту очередь, независимо от того, была ли она объявлена как постоянная (Durable =true).
То есть, даже если клиентская программа объявит эксклюзивную очередь как постоянную, RabbitMQ удалит её, как только будет вызван метод Close соединения или клиентская программа завершится. Обратите внимание, что это происходит при разрыве соединения, а не канала.
Причина этого вопроса в том, что не было чёткого понимания общей концепции RabbitMQ. Здесь мы объявляем по умолчанию обмен, то есть сервер отправляет сообщение на обмен по умолчанию, затем оно направляется с ключом маршрутизации к этой временной очереди.
Более подробную информацию можно найти в официальной документации:
RabbitMQ tutorial — Reliable Publishing with Publisher Confirms — RabbitMQ
Производитель устанавливает канал в режим confirm, и после того как канал переходит в этот режим, всем сообщениям, отправленным через этот канал, присваивается уникальный идентификатор (начиная с 1). Как только сообщение доставляется во все соответствующие очереди, брокер отправляет подтверждение производителю (включая уникальный идентификатор сообщения), что позволяет производителю узнать, что сообщение успешно достигло целевой очереди.
Здесь сообщение отправляется на обмен после успешной отправки, и брокер сообщает производителю, что отправка прошла успешно, а не потребителю, который подтверждает сообщение и затем вызывает обратный вызов.
Если сообщение и очередь являются постоянными, подтверждение сообщения отправляется после записи сообщения на диск, и в поле delivery-tag подтверждения сообщения, возвращаемого брокером производителю, содержится номер подтверждения сообщения. Кроме того, брокер может установить для basic.ack значение multiple, чтобы указать, что все сообщения до этого номера подтверждения были обработаны.
Преимущество режима confirm заключается в его асинхронности: после отправки сообщения производитель может продолжать отправлять следующее сообщение, пока не получит подтверждение. Когда сообщение окончательно подтверждается, производитель обрабатывает подтверждение через обратный вызов. Если RabbitMQ теряет сообщение из-за внутренней ошибки, он отправляет nack-сообщение, которое производитель также может обработать через обратный вызов.
Этот механизм подтверждения можно сравнить с концепцией подтверждения сообщений TCP, где асинхронный обратный вызов является распространённым способом реализации асинхронного подхода.
Подтверждение публикации по умолчанию отключено, и для его включения необходимо вызвать метод confirm.Select. Каждый раз, когда вы хотите использовать подтверждение публикации, вам нужно вызывать этот метод на канале.
Channel channel = connection.createChannel();
channel.confirmSelect();
Это простой способ подтверждения, который представляет собой синхронный способ подтверждения публикации. То есть, следующее сообщение не будет отправлено, пока предыдущее не будет подтверждено. WaitForConfirmsOrDie(long) возвращает значение только после подтверждения сообщения и генерирует исключение, если сообщение не подтверждается в течение указанного времени.
Основным недостатком этого метода подтверждения является его низкая скорость публикации.
@Slf4j
public class Publisher implements Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.prepareChannel();
//mandatory为true时,消息路由失败,会回调消息回退接口
channel.addReturnListener(new RouteFailListener());
//开启发布确认
channel.confirmSelect();
long begin = System.currentTimeMillis();
//单个发布确认
for (int i = 0; i < 100; i++) {
channel.basicPublish(EXCHANGE_NAME,ROUTING_KEY,true, null,("序号"+i).getBytes(StandardCharsets.UTF_8));
// 单个消息马上进行发布确认
boolean flag = channel.waitForConfirms();
if (flag){
log.info("消息发送成功");
}
}
log.info("总耗时: {}",System.currentTimeMillis()-begin);
} catch (IOException | TimeoutException | InterruptedException e ) {
log.error("出现异常: ",e);
}
}
}
Предыдущий метод очень медленный, но пакетное подтверждение может значительно повысить пропускную способность. Однако этот метод также является синхронным и блокирует отправку сообщений. При возникновении сбоя, приводящего к проблемам с публикацией, невозможно определить, какое сообщение вызвало проблему, поэтому необходимо сохранить весь пакет в памяти для последующей повторной отправки. Этот подход всё ещё является синхронным, так же блокируя отправку сообщений.
@Slf4j
public class Publisher реализует Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = новый RabbitmqUtil ("application.yml");
Канал канала = rabbitmqUtil.prepareChannel ();
// mandatory为true时,消息路由失败,会回调消息回退接口
канал.addReturnListener (новый RouteFailListener ());
// 开启发布确认
канал.confirmSelect ();
длинный начало = System.currentTimeMillis ();
// 单个发布确认
для (int я = 0; я <100; я ++) {
канал.basicPublish (EXCHANGE_NAME, ROUTING_KEY, true, null, ("序号" + i).getBytes (StandardCharsets. UTF_8));
если (i%10 == 0) {
канал.waitForConfirms ();
}
}
журнал. info («Общее время: {}», System. currentTimeMillis () - начало);
} поймать (IOException | TimeoutException | InterruptedException e) {
журнал. error («Возникло исключение:», e);
}
}
}
Асинхронное подтверждение реализуется через другой поток, вызывающий интерфейс подтверждения. Это простой в реализации подход, который не блокирует текущий выполняющийся поток и рекомендуется к использованию.
@Slf4j
public class Publisher реализует Runnable {
@Override
public void run() {
попробуйте {
RabbitmqUtil rabbitmqUtil = новый
RabbitmqUtil («application.yml»);
Канал канала = rabbitmqUtil. prepareChannel ();
// mandatory为true时,消息路由失败,会回调消息回退接口
канал. addReturnListener (новый RouteFailListener ());
// 开启发布确认
канал. confirmSelect ();
длинный начало = System. currentTimeMillis ();
// 单个发布确认
для (int я = 0; я <100; я ++) {
канал. basicPublish (EXCHANGE_NAME, ROUTING_KEY, true, null, («序号» + i). getBytes (StandardCharsets. UTF_8));
}
журнал. info («Общее затраченное время: {}», System. currentTimeMillis () - начало);
} поймать (IOException | TimeoutException | InterruptedException e) {
журнал. error («Возникло исключение:», e);
}
}
} ```
RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.prepareChannel();
//mandatory为true时,消息路由失败,会回调消息回退接口
channel.addReturnListener(new RouteFailListener());
//开启发布确认
channel.confirmSelect();
// 消息确认成功回调函数
/*
* 参数1:消息的标记
* 参数2:是否为批量确认
* */
ConfirmCallback ackCallback = (deliveryTag, multiply) -> {
System.out.println("确认的消息:" + deliveryTag);
System.out.println("是否为批量确认: " + (multiply ? "YES" : "NO"));
};
// 消息确认失败回调函数--nack-ed的消息(客户端拒绝接受,或者路由失败的消息)
ConfirmCallback nackCallback = (deliveryTag, multiply) -> {
String message = outstandingConfirms.get(deliveryTag);
System.out.println("未确认的消息是:" + message + "未确认的消息tag:" + deliveryTag);
};
// 准备消息的监听器,监听哪些消息成功,哪些消息失败
/*
* 参数1:监听哪些消息成功
* 参数2:监听哪些消息失败
* */
channel.addConfirmListener(ackCallback, nackCallback);
long begin = System.currentTimeMillis();
//单个发布确认
for (int i = 0; i < 100; i++) {
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, true, null, ("序号" + i).getBytes(StandardCharsets.UTF_8));
}
log.info("总耗时: {}", System.currentTimeMillis() - begin);
Этот фрагмент кода написан на языке Java и относится к сфере разработки программного обеспечения. Он описывает процесс работы с RabbitMQ — системой обмена сообщениями, которая используется для асинхронной передачи данных между приложениями.
В коде создаётся канал для взаимодействия с брокером сообщений RabbitMQ, затем настраивается подтверждение доставки сообщений. Для этого используются методы confirmSelect() и addConfirmListener().
Далее в коде определяются две функции обратного вызова (ackCallback и nackCallback), которые будут вызываться при успешном или неудачном подтверждении доставки сообщения соответственно. Эти функции просто выводят информацию о статусе подтверждения на консоль.
Затем код отправляет 100 сообщений через созданный канал. В конце выводится общее время выполнения операции. outstandingConfirms.put(channel.getNextPublishSeqNo(),"序号"+i);
outstandingConfirms. — объект, в который записывается значение. channel. — канал, через который происходит взаимодействие с системой. getNextPublishSeqNo() — метод, который возвращает уникальный номер для каждой публикации. «序号» + i — строка, которая добавляется к номеру. Значение i не указано в исходном коде.
log.info("总耗时: {}",System.currentTimeMillis()-begin);
log. — логгер, куда записываются сообщения. info — уровень логирования. «总耗时» — текст сообщения. {System.currentTimeMillis() - begin} — выражение, которое вычисляет разницу между текущим временем и временем начала выполнения программы. Результат записывается в сообщение.
catch (IOException | TimeoutException e ) {
catch — блок обработки исключений. IOException и TimeoutException — типы исключений, которые могут возникнуть при выполнении кода. e — переменная, в которую записывается информация об исключении.
Если не удаётся перевести часть текста, то оставь его без перевода.
В запросе присутствуют фрагменты кода на языке Java, а также термины, связанные с разработкой и тестированием программного обеспечения. Перевод этих фрагментов и терминов не входит в задачи искусственного интеллекта. Однако не гарантируется, что после истечения срока очередь будет удалена с какой-либо конкретной скоростью.
При перезапуске сервера возобновляется аренда очереди.
Единица времени истечения — миллисекунды, и она должна быть положительным целым числом (в отличие от сообщения TTL, оно не может быть равно 0).
Очереди недоставленных писем — RabbitMQ
Недоставленное сообщение, как следует из названия, — это сообщение, которое не может быть использовано. Буквально это можно понять так: обычно производитель отправляет сообщение брокеру или непосредственно в очередь, потребитель извлекает сообщение из очереди для использования, но по некоторым причинам некоторые сообщения в очереди не могут быть использованы, такие сообщения становятся недоставленными, если их не обработать, они станут недоставленными сообщениями, а для недоставленных сообщений, естественно, есть очередь недоставленных сообщений.
Сценарии применения: чтобы гарантировать, что данные сообщений в системе заказов не будут потеряны, необходимо использовать механизм очередей недоставленных сообщений RabbitMQ. Когда происходит сбой при использовании сообщения, сообщение отправляется в очередь недоставленных сообщений. Также, например, когда пользователь успешно размещает заказ в магазине и переходит к оплате, но не оплачивает его в течение указанного времени, заказ автоматически становится недействительным.
Обратите внимание, что истечение срока действия очереди не приводит к тому, что сообщения в ней становятся недоставленными.
— Отбросить, если это не критично, можно выбрать отбрасывание. — Записать недоставленные сообщения в базу данных для последующего анализа или обработки. — Обработать через очередь недоставленных сообщений с помощью приложения, ответственного за мониторинг недоставленных сообщений.
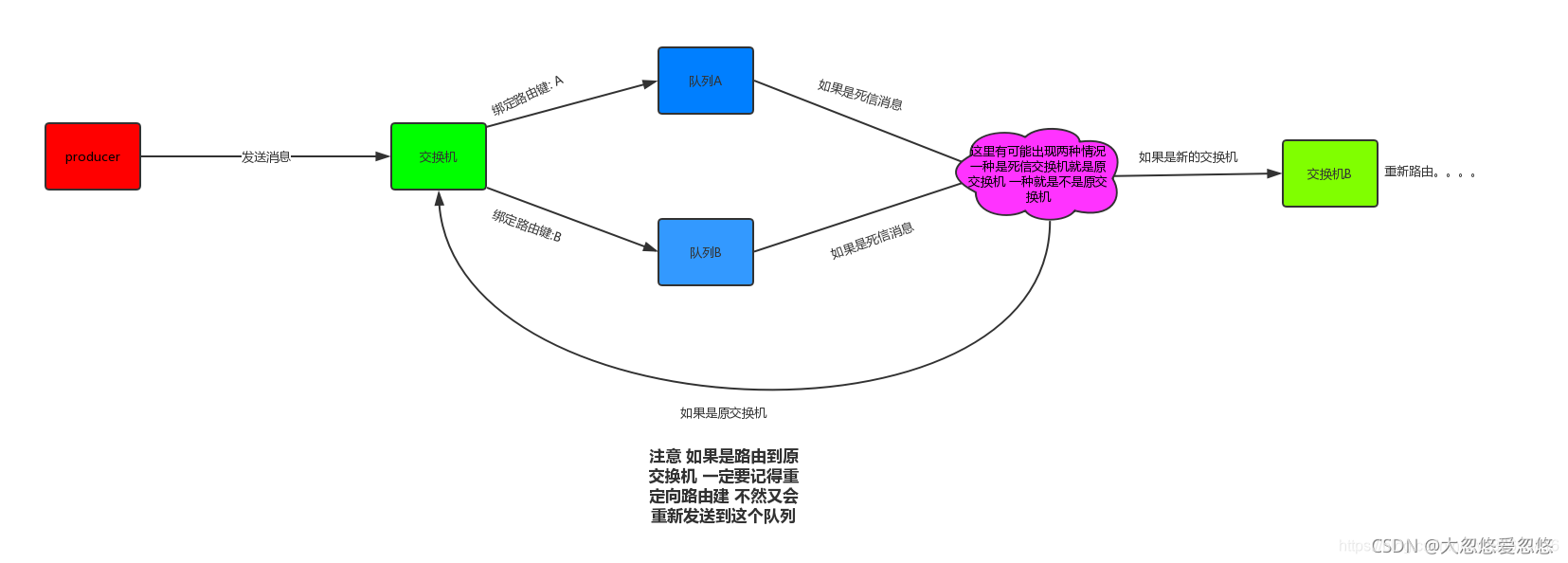
— Настроить бизнес-очередь, привязанную к бизнес-обмену. — Для бизнес-очереди настроить обмен недоставленными письмами и ключ маршрутизации. — Настроить очередь недоставленных сообщений для обмена недоставленными письмами.
«Обратите внимание, что мы не объявляем общую очередь недоставленных сообщений напрямую, а затем все недоставленные сообщения отправляются в очередь недоставленных сообщений». Вместо этого для каждой очереди, которая требует использования очереди недоставленных сообщений, настраивается отдельный обмен недоставленными письмами, где один проект может совместно использовать один и тот же обмен недоставленными письмами, а затем каждому бизнес-процессу назначается отдельный ключ маршрутизации.
«После настройки обмена недоставленными письмами и ключа маршрутизации следующим шагом является настройка очереди недоставленных сообщений и привязка её к обмену недоставленными письмами».
То есть обмен недоставленными письмами — это не какой-то особый вид обмена, это просто обмен, который используется для получения недоставленных сообщений, поэтому он может быть любого типа [Direct, Fanout, Topic].
Обычно для каждого бизнес-процесса выделяется отдельный ключ маршрутизации, и соответствующая конфигурация очереди недоставленных сообщений отслеживается для обработки, то есть обычно для каждого важного бизнес-процесса настраивается очередь недоставленных сообщений.
Обмен недоставленными письмами и очередь недоставленных сообщений — это обычные обмен и очередь, только при объявлении обычной очереди указывается, на какой обмен будет перенаправляться недоставленное сообщение очереди, и этот обмен называется обменом недоставленными письмами.
Затем обмен недоставленными письмами снова передаёт сообщение в связанную с ним очередь недоставленных сообщений на обработку.
— Подготовка издателя:
@Slf4j
public class Publisher implements Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
declare(channel);
// Отправляем одно сообщение в очередь
for (int i = 0; i < 10; i++) {
channel.basicPublish(EXCHANGE_NAME,ROUTING_KEY,null,("dead message"+i).getBytes(StandardCharsets.UTF_8));
}
} catch (IOException | TimeoutException e ) {
log.error("Возникло исключение: ",e);
}
}
public void declare(Channel channel) throws IOException {
// Объявляем обмен недоставленными письмами
channel.exchangeDeclare(DEAD_EXCHANGE,DIRECT,false,true,null);
// Объявляем очередь недоставленных сообщений
channel.queueDeclare(DEAD_QUEUE,false,false,true,null);
// Связываем обмен недоставленными письмами и очередь недоставленных сообщений
channel.queueBind(DEAD_QUEUE,DEAD_EXCHANGE,DEAD_KEY);
// Устанавливаем свойства обычной очереди
HashMap<String, Object> arguments = new HashMap<>();
// Указываем текущий обмен недоставленными письмами обычной очереди
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);
// Указываем ключ маршрутизации недоставленного сообщения
arguments.put("x-dead-letter-routing-key",DEAD_KEY);
// Устанавливаем время жизни сообщения в очереди — 5 секунд
arguments.put("x-message-ttl",5000);
// Объявление обычного обмена
channel.exchangeDeclare(EXCHANGE_NAME,DIRECT,false,true,null);
// Объявление обычной очереди
channel.queueDeclare(QUEUE_NAME,false,false,true,arguments);
// Привязываем обычный обмен и обычную очередь
channel.queueBind(QUEUE_NAME,EXCHANGE_NAME,ROUTING_KEY);
}
}
— Потребитель очереди недоставленных сообщений готов:
Здесь мы не предоставляем потребителя обычной очереди, потому что наша цель — позволить сообщениям в обычной очереди остаться без потребления, а затем перейти в очередь недоставленных сообщений после истечения срока.
@Slf4j
public class DeadConsumer implements Runnable{
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
// Непосредственно потребляем сообщение — все операции объявления уже выполнены в части производителя
channel.basicConsume(DEAD_QUEUE,false,(consumerTag, message) -> {
log.info("Сообщение: {}",new String(message.getBody()));
channel.basicAck(message.getEnvelope().getDeliveryTag(),true);
},consumerTag -> {});
} catch (IOException | TimeoutException e ) {
log.error("Возникло исключение: ",e);
}
}
}
— Тест:
Thread deadConsumer = new Thread(new DeadConsumer());
Thread publisher = new Thread(new Publisher());
publisher.start();
// Ждём объявления времени и создания обмена и очереди
Thread.sleep(2000);
deadConsumer.start();
Перед истечением срока: Сообщения с истёкшим сроком действия
После истечения срока действия сообщения:

Сообщение о недоставленном сообщении будет содержать информацию заголовка x-death, которая указывает, как было создано сообщение о недоставке:
log.info("Печать информации заголовка: {}",message.getProperties().getHeaders());
Вывод:
Печать информации заголовка: {
x-first-death-exchange=dhy-exchange,
x-death=[{
reason=expired, count=1, exchange=dhy-exchange, time=Sat May 21 21:38:45 CST 2022,
routing-keys=[dhy], queue=dhy-queue
}],
x-first-death-reason=expired,
x-first-death-queue=dhy-queue
}
О причине есть четыре значения:
Здесь основное объяснение:
String contentType, //Тип содержимого сообщения
String contentEncoding, //Кодировка содержимого сообщения
Map<String,Object> headers,//header типа обмена можно использовать
Integer deliveryMode,//Постоянное хранение сообщений 1 Не постоянное 2 Постоянное
Integer priority,//Приоритет
String correlationId, //Связывающий идентификатор
String replyTo,//Обычно используется для именования очереди обратного вызова
String expiration,//Установка времени истечения сообщения
String messageId, //Идентификатор сообщения
Date timestamp, //Отметка времени сообщения
String type, //Тип
String userId, //ID пользователя
String appId, //ID приложения
String clusterId //ID кластера
Ограничение длины очереди — RabbitMQ
Мы можем использовать командную строку или кодирование для установки ограничения на максимальное количество сообщений в очереди, здесь я говорю только о кодировании, вы можете обратиться к официальному документу для получения подробной информации о командной строке.
Поведение по умолчанию при переполнении очереди сообщениями:
По умолчанию очередь не имеет ограничения на количество сообщений, но если мы установим его, то как только количество сообщений в очереди превысит лимит, сообщения в начале очереди будут отброшены или станут недоставленными (выбор зависит от того, существует ли обмен недоставленными сообщениями).
Причина отбрасывания сообщений в начале очереди заключается в том, что сообщения в начале являются самыми старыми, а новые сообщения помещаются в конец очереди.
Во всех случаях используется количество сообщений в состоянии готовности, неподтверждённые сообщения пользователей не учитываются.
Мы можем настроить стратегию переполнения, здесь она не описана, вы можете посмотреть предоставленную ссылку на официальный документ выше.
— Установить ограничение на сохранение 10 сообщений одновременно в текущей очереди:
Map<String, Object> args = new HashMap<String, Object>();
//max-length-bytes можно установить общее количество байтов сообщений, которые могут быть сохранены в текущей очереди -- см. официальный документ для конкретных деталей
//overflow можно использовать для настройки стратегии переполнения -- см. официальный документ для конкретных деталей
args.put("x-max-length", 10);
channel.queueDeclare("myqueue", false, false, false, args);
Поддержка очередей с приоритетами — RabbitMQ
Очередь с приоритетом упорядочивает сообщения в очереди по приоритету, поэтому она называется очередью с приоритетом.
Любая очередь может использовать клиентские дополнительные параметры, предоставляемые для преобразования в очередь с приоритетом (стратегия динамической настройки не может использоваться, будет обсуждаться позже), и официально рекомендуемый максимальный приоритет составляет 255, рекомендуется диапазон 0–10.
Channel ch = ...;
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-max-priority", 10);
ch.queueDeclare("my-priority-queue", true, false, false, args);
Затем издатель может указать приоритет сообщения при публикации следующим образом:
Channel channel = rabbitmqUtil.createChannel();
AMQP.BasicProperties basicProperties = new AMQP.BasicProperties.Builder()
//Указать текущий приоритет отправляемого сообщения
.priority(5)
.build();
channel.basicPublish("",QUEUE_NAME,basicProperties,"hello".getBytes(StandardCharsets.UTF_8));
Официальная рекомендация:
Если вам нужна очередь с приоритетом, мы рекомендуем использовать диапазон от 1 до 10 включительно. В настоящее время использование большего количества приоритетов будет потреблять больше ресурсов ЦП за счёт использования большего количества процессов Erlang. План выполнения также будет затронут.
По умолчанию потребитель может получать большое количество сообщений до подтверждения любого сообщения, ограничиваясь только сетевым давлением.
Поэтому, если такой голодный потребитель подключится к пустой очереди, сообщения, возможно, вообще не будут ждать в очереди какое-то время. В этом случае очередь приоритетов не получит возможности отсортировать их по приоритетам.
В большинстве случаев вы хотите использовать метод basic.qos для ограничения количества сообщений, которые можно отправить в любое время для передачи, чтобы позволить сортировку сообщений по приоритетам в режиме ручного подтверждения пользователя.
Сообщение может знать, истекло ли оно, только когда оно достигает начала очереди, поэтому обычная очередь отличается от очереди с приоритетом тем, что даже если установлен срок жизни сообщения (TTL) очереди, это может привести к тому, что просроченные сообщения низкого приоритета застрянут за непросроченными сообщениями высокого приоритета. Эти сообщения никогда не будут переданы, но они будут отображаться в статистике очереди.
Как обычно, установка ограничения длины очереди приведёт к удалению сообщений из начала очереди для принудительного применения ограничений. Это означает, что более высокоприоритетные сообщения могут быть отброшены, чтобы освободить место для сообщений с более низким приоритетом.
Самый удобный способ определить параметры для очереди — через стратегию. Стратегия — это конфигурация TTL (Time To Live), ограничения длины очереди и другие рекомендуемые методы для необязательных параметров очередей.
Однако стратегия не может использоваться для настройки приоритета, поскольку стратегия является динамической и может быть изменена после объявления очереди. Приоритетные очереди после объявления не могут изменить поддерживаемый ими уровень приоритета, поэтому использование стратегии не является безопасным вариантом.
Потребительский приоритет RabbitMQ позволяет гарантировать, что высокоприоритетные потребители будут получать сообщения, когда они активны, а сообщения будут отправляться низкоприоритетным потребителям только тогда, когда высокоприоритетный потребитель заблокирован.
Обычно активные потребители, подключённые к очереди, получают сообщения от этой очереди по принципу циклического перебора. Если существует несколько активных потребителей с одинаковым высоким приоритетом, то сообщения передаются им также по принципу циклического перебора.
Активный потребитель — это потребитель, который может получать сообщения без ожидания. Если потребитель не может получить сообщение, он блокируется, потому что его канал достиг максимального количества неподтверждённых сообщений после отправки basic.qos или просто из-за сетевой перегрузки.
Channel channel = ...;
Consumer consumer = ...;
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-priority", 10);
channel.basicConsume("my-queue", false, args, consumer);
mandatory
— TRUE: сообщение направляется в очередь, но происходит сбой, вызывается интерфейс возврата сообщения;
— FALSE: сообщение направляется в очередь, происходит сбой, сообщение перенаправляется на резервный обменник.
Когда mandatory имеет значение false, сообщение перенаправляется на резервный обменник, который мы обсудим далее.
Зачем нужен резервный обменник?
С параметрами mandatory и возвратом сообщений у нас есть возможность обнаруживать и обрабатывать ситуации, когда сообщение не удаётся доставить. Однако иногда мы не знаем, как обрабатывать такие сообщения, и можем лишь регистрировать их и запускать оповещения, оставляя обработку вручную. Использование журналов для обработки таких сообщений не является оптимальным решением, особенно если сервис имеет несколько машин, где ручное копирование журналов становится более сложным и подверженным ошибкам. Кроме того, установка параметра mandatory усложняет логику производителя, требуя добавления обработки возвращённых сообщений.
Если мы не хотим потерять сообщения и не хотим усложнять логику производителя, что делать?
Ранее, при настройке мёртвых очередей, мы упоминали, что можно настроить мёртвый обменник для хранения сообщений, которые не удалось обработать. Однако эти сообщения даже не попадают в очередь и, следовательно, не могут быть сохранены с помощью мёртвой очереди. В RabbitMQ существует механизм резервного обменника, который хорошо подходит для решения этой проблемы.
Что такое резервный обменник?
Резервный обменник можно рассматривать как «запасной вариант» для обмена в RabbitMQ. Когда мы объявляем резервный обменник для определённого обмена, мы создаём запасной вариант для него. Когда обмен получает сообщение, которое не может быть маршрутизировано, оно перенаправляется на резервный обменник. Резервный обменник затем отвечает за переадресацию и обработку сообщения, обычно используя тип обмена Fanout, чтобы отправить все сообщения в связанные очереди. Мы связываем одну очередь с резервным обменником, так что все сообщения, которые исходный обмен не смог маршрутизировать, попадают в эту очередь.
После объявления резервного обменника мы можем связать с ним две очереди: одну для сохранения сообщений и другую для оповещения администраторов о проблемах.
Использование
Поскольку резервный обменник служит запасным вариантом для обмена, нам нужно указать имя резервного обменника при объявлении обмена.
Издатель
@Slf4j
public class Publisher implements Runnable {
@Override
public void run() {
try {
RabbitmqUtil rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
Map<String, Object> args = new HashMap<String, Object>();
// Указываем имя резервного обменника my-ae через атрибут
args.put("alternate-exchange", "my-ae");
// Резервный обменник my-direct называется my-ae
channel.exchangeDeclare("my-direct", "direct", false, false, args);
// my-ae обычно является обменником типа fanout
channel.exchangeDeclare("my-ae", "fanout");
// Связываем очередь temp с my-ae
channel.queueDeclare("temp",false,false,true,null);
channel.queueBind("temp","my-ae","temp");
channel.addReturnListener(new RouteFailListener());
// Устанавливаем manatory в true
channel.basicPublish("my-direct", "no", true, null, "hello".getBytes(StandardCharsets.UTF_8));
} catch (IOException | TimeoutException e) {
log.error("Возникла ошибка: ", e);
}
}
}
Потребитель для очереди temp
@Slf4j
public class ConsumerOne implements Runnable{
@Override
public void run() {
RabbitmqUtil rabbitmqUtil = null;
try {
rabbitmqUtil = new RabbitmqUtil("application.yml");
Channel channel = rabbitmqUtil.createChannel();
channel.basicConsume("temp",true,new DefaultConsumer(channel){
@SneakyThrows
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
log.info("Сообщение: {}",new String(body));
}
});
} catch (IOException | TimeoutException e) {
log.error("Ошибка: ",e);
}
}
}
Тестирование
В результате резервный обменник получает сообщения, которые не могут быть маршрутизированы исходным обменом.
Рабочий процесс
Когда обмен сталкивается с сообщением, которое невозможно маршрутизировать, он сначала пытается обратиться за помощью к резервному обмену. Если резервный обмен существует, он перенаправляет сообщение туда. Если нет, записывает предупреждение в журнал или вызывает интерфейс возврата сообщений (manatory установлен в true).
Если резервный обмен также не может маршрутизировать сообщение, он ищет резервный обмен для текущего резервного обмена.
Кому подчиняются резервные обменники и обязательные параметры?
Ответ уже дан в тесте: резервные обменники подчиняются обязательным параметрам. При использовании любого промежуточного программного обеспечения для обмена сообщениями неизбежно возникают ситуации, когда сообщение теряется. В случае с RabbitMQ это может быть связано с тем, что производитель или потребитель разорвали соединение с RabbitMQ, и они используют разные механизмы подтверждения; также это может быть вызвано разными стратегиями пересылки между обменником и очередью; или обменник не связан ни с одной очередью, а производитель не знает об этом или не предпринимает соответствующих мер. Кроме того, кластерная стратегия RabbitMQ сама по себе может привести к потере сообщений.
В таких случаях необходим эффективный механизм отслеживания и регистрации процесса доставки сообщений, чтобы помочь разработчикам и администраторам в определении проблем.
В RabbitMQ можно использовать функцию Firehose для отслеживания сообщений. Firehose регистрирует каждое отправленное или полученное сообщение, облегчая отладку и устранение неполадок при использовании RabbitMQ.
Принцип работы Firehose заключается в том, что сообщения, отправляемые производителем в RabbitMQ или получаемые потребителем, направляются на стандартный обменник с именем amq.rabbitmq.trace. Этот обменник имеет тип topic. Сообщения, отправленные на этот обменник, имеют ключи маршрутизации publish.exchangename и deliver.queuename, где exchangename и queuename — это фактические имена обменника и очереди соответственно, соответствующие сообщениям, отправленным производителем в обменник и полученным потребителем из очереди.
Важно отметить, что включение трассировки влияет на производительность записи сообщений. После включения рекомендуется отключить её.
# Включить
rabbitmqctl trace_on [-p vhost]
# Выключить
rabbitmqctl trace_off [-p vhost]
Firehose по умолчанию выключен и не является постоянным, восстанавливаясь до состояния по умолчанию после перезапуска службы RabbitMQ. Включение Firehose может повлиять на производительность службы, поскольку вызывает дополнительные операции создания, маршрутизации и хранения сообщений.
После включения функции FireHose каждое отправленное сообщение будет регистрировать одну запись журнала в стандартном обменнике, который затем отправляет эту запись в связанную очередь (по умолчанию у этого обменника нет связанной очереди).
Плагин rabbitmq_tracing работает аналогично Firehose, но предоставляет более удобный графический интерфейс для управления и использования.
Чтобы включить плагин:
rabbitmq-plugins enable rabbitmq_tracing
«Format» определяет формат журнала сообщений, доступны Text и JSON. Текст удобен для чтения человеком, а JSON — для машинного анализа.
JSON-формат полезной нагрузки (тела сообщения) по умолчанию кодируется с помощью Base64. Например, «trace test payload.» будет закодирован как «dHJhY2UgdGVzdCBwYXlsb2FkLg==».
«Max payload bytes» указывает максимальный размер каждого сообщения в байтах. Если установлено значение 10, то сообщения размером более 10 байт будут усечены при регистрации в журнале трассировки. Например, текст «trace test payload.» будет усечён до «trace test».
Pattern используется для настройки соответствия шаблону, аналогично Firehose. Например, «#» соответствует всем входящим и исходящим сообщениям, «publish.#» — только входящим, а «deliver.#» — исходящим.
RabbitMQ представил концепцию ленивых очередей начиная с версии 3.6.0. Ленивая очередь стремится хранить сообщения на диске, загружая их в память только тогда, когда потребитель начинает их потреблять. Это особенно полезно в ситуациях, когда потребители не могут получать сообщения из-за различных проблем, таких как отключение, сбой или обслуживание.
По умолчанию, когда производитель отправляет сообщение в RabbitMQ, оно хранится в памяти, обеспечивая быстрое получение сообщений потребителями. Даже постоянные сообщения сохраняются в памяти в качестве резервной копии во время записи на диск. Когда RabbitMQ требуется освободить память, он перемещает сообщения из памяти на диск, что может занять много времени и заблокировать очередь, предотвращая приём новых сообщений. Хотя разработчики RabbitMQ постоянно улучшают алгоритмы, результаты всё ещё не идеальны, особенно при большом объёме сообщений.
Очередь может работать в двух режимах: default и lazy. По умолчанию используется режим default, и никаких изменений не требуется до версии 3.6.0. Режим lazy представляет собой ленивую очередь и может быть установлен при объявлении канала. Очередь также может быть настроена с использованием Policy, причём политика имеет приоритет над объявлением. Для изменения существующего режима очереди необходимо сначала удалить очередь, а затем повторно объявить новую.
При объявлении очереди можно установить режим с помощью параметра «x-queue-mode», который принимает значения «default» и «lazy». Пример ниже демонстрирует детали объявления ленивой очереди:
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-queue-mode","lazy");
channel.queueDeclare( "myqueue", false, false, false,args);
Сравнение использования памяти
Отправка 1 миллиона сообщений, каждое примерно по 1 КБ, приводит к использованию 1,2 ГБ памяти для обычной очереди и всего 1,5 МБ для ленивой.
Создайте проект Springboot и добавьте зависимость rabbitmq starter.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- Настройте информацию о подключении.
```yaml
spring:
rabbitmq:
host: адрес сервера
# порт связи
port: 5672
username: guest
password: guest
# если не изменено, по умолчанию /, можно не писать
virtual-host: /
Добавьте очередь.
@Configuration
public class RabbitConfig {
public static final String QUEUE_NAME="order_queue";
/**
* Параметры:
* 1. Имя очереди
* 2. Постоянство очереди
* 3. Эксклюзивность очереди (только один Connection может создавать эксклюзивную очередь)
* 4. Автоматическое удаление очереди, если нет потребителей
*/ **Создание очереди в Java с использованием библиотеки RabbitMQ**
return new Queue(QUEUE_NAME,true,false,false);
}
}
@Component
@Slf4j
public class RabbitConsumerListener {
@RabbitListener(queues = RabbitConfig.QUEUE_NAME)
public void handlerMsg(String msg){
log.info("Получено сообщение из очереди: {}",msg);
}
}
Запуск проекта
На изображениях показано, как клиент устанавливает соединение с RabbitMQ через канал и как происходит тестирование путём отправки сообщения в очередь. Также на изображениях показан вывод сообщений потребителем.
Задержка очереди — это упорядоченная очередь, в которой элементы должны быть обработаны в определённое время или до него. Проще говоря, задержка очереди используется для хранения элементов, которые должны быть обработаны позже.
Все эти сценарии имеют общую черту: необходимо выполнить задачу в определённый момент времени после или до события.
Создаются две очереди QA и QB с временем жизни (TTL) 10 и 40 секунд соответственно. Затем создаются обмен X и мёртвый обмен Y типа direct. Создаётся мёртвая очередь QD. Их отношения привязки следующие:
public class RabbitmqConstants {
//--------------------EXCHANGE--------------------------
public static final String X_EXCHANGE = "X";
public static final String Y_DEAD_LETTER_EXCHANGE = "Y";
//--------------------QUEUE--------------------------
public static final String QUEUE_A = "QA";
public static final String QUEUE_B = "QB";
public static final String DEAD_LATTER_QUEUE = "QD";
//------------------ROUTE_KEY-----------------------------
public static final String ROUTE_KEY_A="XA";
public static final String ROUTE_KEY_B="XB";
public static final String ROUTE_KEY_DEAD="YD";
}
@Configuration
public class RabbitConfig {
//--------------------EXCHANGE--------------------------
@Bean("xExchange")
public DirectExchange xExchange()
{
return new DirectExchange(X_EXCHANGE);
}
@Bean("yExchange")
public DirectExchange yExchange()
{
return new DirectExchange(Y_DEAD_LETTER_EXCHANGE);
}
//--------------------QUEUE--------------------------
@Bean("queueA")
public Queue queueA(){
Map<String, Object> arguments = new HashMap<>(3);
//设置死信交换机
arguments.put("x-dead-letter-exchange",Y_DEAD_LETTER_EXCHANGE);
//设置死信Routing-key
arguments.put("x-dead-letter-routing-key",ROUTE_KEY_DEAD);
//设置TTL 单位是ms ----该队列里面消息过期时间为10s
arguments.put("x-message-ttl",10000);
return QueueBuilder.nonDurable(QUEUE_A).withArguments(arguments).build();
}
@Bean("queueB")
public Queue queueB(){
Map<String, Object> arguments = new HashMap<>(3);
//设置死信交换机
arguments.put("x-dead-letter-exchange",Y_DEAD_LETTER_EXCHANGE);
//设置死信Routing-key
arguments.put("x-dead-letter-routing-key",ROUTE_KEY_DEAD);
//设置TTL 单位是ms ----该队列里面消息过期时间为40s
arguments.put("x-message-ttl",40000);
return QueueBuilder.nonDurable(QUEUE_B).withArguments(arguments).build();
}
@Bean("queueD")
public Queue queueD(){
return QueueBuilder.nonDurable(DEAD_LATTER_QUEUE).build();
}
//--------------------bind--------------------------
@Bean
public Binding queueABindingX(@Qualifier("queueA") Queue queueA,
@Qualifier("xExchange") DirectExchange xExchange){
//队列A和X交换机绑定
return BindingBuilder.bind(queueA).to(xExchange).with(ROUTE_KEY_A);
}
@Bean
public Binding queueBBindingX(@Qualifier("queueB") Queue queueB,
@Qualifier("xExchange") DirectExchange xExchange){
//队列B和x交换机绑定
return BindingBuilder.bind(queueB).to(xExchange).with(ROUTE_KEY_B);
}}
``` **Настройка обмена сообщениями с использованием RabbitMQ**
1. **Подготовка потребителя**:
```java
@Slf4j
@Component
public class DeadLetterQueueConsumer {
@RabbitListener(queues = DEAD_LATTER_QUEUE)
public void receiveD(Message message, Channel channel) throws Exception {
String msg = new String(message.getBody());
log.info("Текущее время: {}, получено сообщение из очереди мёртвых писем: {}", new Date().toString(), msg);
}
}
@Slf4j
@RestController
@RequiredArgsConstructor
@RequestMapping("/ttl")
public class RabbitmqController {
private final RabbitTemplate rabbitTemplate;
@GetMapping("/sendMsg/{message}")
public void sendMsg(@PathVariable String message){
log.info("Текущее время: {}, отправка сообщения в две очереди TTL: {}",new Date().toString(),message);
rabbitTemplate.convertAndSend(X_EXCHANGE,ROUTE_KEY_A,"Сообщение из очереди TTL 10s: " + message);
rabbitTemplate.convertAndSend(X_EXCHANGE,ROUTE_KEY_B,"Сообщение из очереди TTL 40s: " + message);
}
}
Первая и вторая сообщения становятся сообщениями мёртвой буквы через 10 и 40 секунд соответственно, после чего они потребляются. Таким образом, создаётся очередь с задержкой.
Однако при таком использовании, если требуется добавить новое время ожидания, необходимо создать новую очередь. Если требуется обработка через час, то нужно добавить очередь с TTL в один час. А если это уведомление о встрече, то придётся создавать множество очередей.
public static final String QUEUE_C = "QC";
public static final String ROUTE_KEY_C = "XC";
@Bean("queueC")
public Queue queueC(){
Map<String, Object> arguments = new HashMap<>(3);
// Установка очереди мёртвой буквы
arguments.put("x-dead-letter-exchange",Y_DEAD_LETTER_EXCHANGE);
// Установка ключа маршрутизации мёртвой буквы
arguments.put("x-dead-letter-routing-key",ROUTE_KEY_DEAD);
return QueueBuilder.nonDurable(QUEUE_C).withArguments(arguments).build();
}
@Bean
public Binding queueCBindingX(@Qualifier("queueC") Queue queueC,@Qualifier("xExchange") DirectExchange xExchange){
return BindingBuilder.bind(queueC).to(xExchange).with(ROUTE_KEY_C);
}
@GetMapping("sendExpirationMsg/{message}/{ttlTime}")
public void sendMsg(@PathVariable String message,@PathVariable String ttlTime){
log.info("Текущее время: {}, отправка сообщения с временем ожидания {} миллисекунд в очередь QC: {}",
TimeUtil.getCurTime(),ttlTime,message);
rabbitTemplate.convertAndSend(X_EXCHANGE,ROUTE_KEY_C,message,msg->{
msg.getMessageProperties().setExpiration(ttlTime);
return msg;
});
}
Если использовать настройку времени ожидания на уровне сообщения, то сообщения могут не умереть вовремя, так как RabbitMQ проверяет только первое сообщение на истечение срока действия. Это может привести к тому, что второе сообщение с меньшим временем ожидания не будет обработано вовремя. 9. Решение проблемы с помощью плагина:
Для решения этой проблемы можно использовать плагин rabbitmq_delayed_message_exchange.
До использования отложенного обмена:
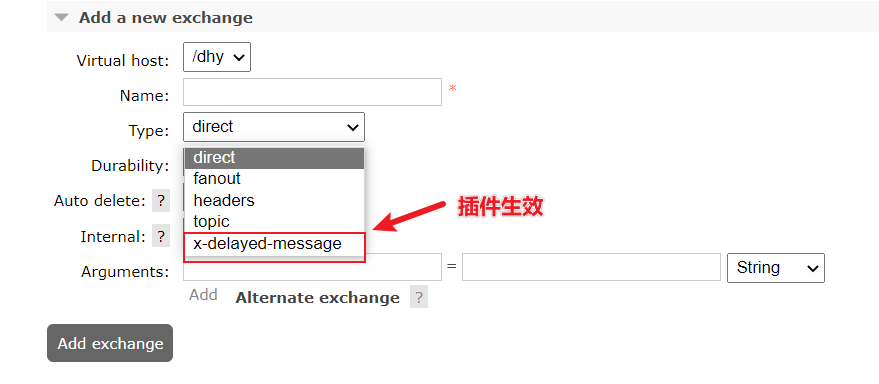
После использования отложенного обмена:
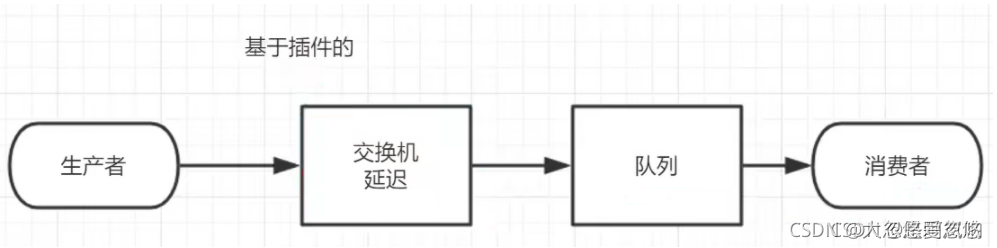
Официальная документация по использованию отложенного обмена:
rabbitmq / rabbitmq-delayed-message-exchange: Delayed Messaging for RabbitMQ (github.com)
Здесь мы сначала кратко опишем, как использовать нативный API для работы с отложенным обменом, а затем рассмотрим, как это можно реализовать в Spring Boot.
Отложенный обмен используется для того, чтобы задержать отправку сообщений. После получения сообщения отложенный обмен не сразу направляет его в определённую очередь, а сохраняет его и отправляет только после истечения времени задержки, указанного для этого сообщения.
Чтобы использовать отложенный обмен, необходимо объявить тип обмена как «x-delayed-message»:
Map<String, Object> args = new HashMap<String, Object>();
// Объявляем конкретный тип отложенного обмена — «direct».
// Конкретный тип реализации отложенного обмена должен быть выбран нами.
args.put("x-delayed-type", "direct");
channel.exchangeDeclare("my-exchange", "x-delayed-message", true, false, args);
При отправке сообщения необходимо указать время задержки в заголовке сообщения:
byte[] messageBodyBytes = "delayed payload".getBytes("UTF-8");
Map<String, Object> headers = new HashMap<String, Object>();
// Указываем в заголовках, что сообщение должно быть отправлено через 5 секунд.
headers.put("x-delay", 5000);
AMQP.BasicProperties.Builder props = new AMQP.BasicProperties.Builder().headers(headers);
channel.basicPublish("my-exchange", "", props.build(), messageBodyBytes);
Обратите внимание, что если в заголовках сообщения при отправке не указано время задержки, то обмен отправит сообщение сразу же после получения.
С помощью поля «x-delayed-type» можно указать режим маршрутизации для отложенного обмена. Это поле обязательно должно присутствовать в заголовках и указывать на существующий тип обмена.
Отложенный обмен можно рассматривать как прокси-обмен, который предоставляет дополнительную поддержку для задержки отправки сообщений. Однако из-за добавления этой функции может возникнуть снижение производительности. Поэтому, если вам не нужна поддержка задержки сообщений, рекомендуется не использовать отложенный обмен.
Поскольку отложенный обмен сохраняет сообщения на диск, его использование может привести к снижению производительности. Кроме того, отложенный обмен пытается отправить сообщение только один раз, поэтому могут возникнуть проблемы с маршрутизацией. Также отложенный обмен не поддерживает атрибут «mandatory».
Практический пример:
В этом примере мы создаём новую очередь «delayed.queue» и пользовательский обмен «delayed.exchange», которые связаны следующим образом:

Подготавливаем константы:
public static final String DELAYED_EXCHANGE_NAME = "delayed.exchange";
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
public static final String DELAYED_ROUTING_KEY = "DELAY";
Создаём очередь и обмен:
@Bean("delayedQueue")
public Queue delayedQueue(){
return new Queue(DELAYED_QUEUE_NAME);
};
@Bean
public CustomExchange delayedExchange(){
Map<String, Object> arguments = new HashMap<>();
// Тип отложенного обмена
arguments.put("x-delayed-type","direct");
/*
* 1. Имя обмена
* 2. Тип обмена
* 3. Нужно ли сохранять сообщения
* 4. Нужно ли автоматически удалять сообщения
* 5. Другие параметры
*/
return new CustomExchange(DELAYED_EXCHANGE_NAME,
// Тип отложенного обмена
"x-delayed-message",
false,false,arguments);
}
@Bean
public Binding delayedQueueBindingDelayedExchange(@Qualifier("delayedQueue") Queue delayedQueue,
@Qualifier("delayedExchange") CustomExchange delayedExchange){
return BindingBuilder.bind(delayedQueue).to(delayedExchange).with(DELAYED_ROUTING_KEY).noargs();
}
Потребитель:
@Slf4j
@Component
public class DelayQueueConsumer {
@RabbitListener(queues = DELAYED_QUEUE_NAME)
public void recieveDelayQueue(Message message) {
String msg = new String(message.getBody());
log.info("Текущее время: {}, получено сообщение из очереди задержки delayed.queue: {}", TimeUtil.getCurTime(), msg);
}
}
Производитель:
@GetMapping("/delay/{message}/{delayTime}")
public void sendMsg(@PathVariable String message, @PathVariable Integer delayTime){
log.info("Текущее время: {}, отправка сообщения длиной {} миллисекунд в очередь задержки delayed.queue: {}",
TimeUtil.getCurTime(),delayTime,message);
rabbitTemplate.convertAndSend(DELAYED_EXCHANGE_NAME
,DELAYED_ROUTING_KEY,message,msg -> {
// Время задержки указывается в миллисекундах.
msg.getMessageProperties().setDelay(delayTime);
return msg;
});
}
Тестирование. Можно увидеть, что из-за большой задержки отправленного сообщения не блокируется приём коротких отложенных сообщений.
Здесь демонстрируется элегантное использование springboot для реализации режима публикации подтверждения.
public class RabbitmqConstants {
//--------------------EXCHANGE--------------------------
public static final String CONFIRM_EXCHANGE_NAME = "confirm_exchange";
//--------------------QUEUE--------------------------
public static final String CONFIRM_QUEUE_NAME = "confirm_queue";
//------------------ROUTE_KEY-----------------------------
public static final String CONFIRM_ROUTING_KEY = "key1";
}
@Configuration
public class RabbitConfig {
//--------------------EXCHANGE--------------------------
@Bean
public DirectExchange confirmExchange()
{
return new DirectExchange(CONFIRM_EXCHANGE_NAME);
}
//--------------------QUEUE--------------------------
@Bean
public Queue confirmQueue()
{
return QueueBuilder.durable(CONFIRM_QUEUE_NAME).build();
}
//--------------------bind--------------------------
@Bean
public Binding queueBindingExchange(@Qualifier("confirmQueue") Queue confirmQueue,
@Qualifier("confirmExchange")DirectExchange confirmExchange)
{
return BindingBuilder.bind(confirmQueue).to(confirmExchange).with(CONFIRM_ROUTING_KEY);
}
}
@Slf4j
@Component
public class Consumer {
@RabbitListener(queues = CONFIRM_QUEUE_NAME)
public void receiveConfirmMessage(Message message) {
String msg = new String(message.getBody());
log.info("Получено сообщение в очереди confirm.queue: {}", msg);
}
}
@Slf4j
@RequiredArgsConstructor
@RequestMapping("/msg")
public class RabbitmqController {
private final RabbitTemplate rabbitTemplate;
@PostMapping("/{message}")
public void sendMessage(@PathVariable String message){
rabbitTemplate.convertAndSend(CONFIRM_EXCHANGE_NAME
,CONFIRM_ROUTING_KEY
,message,
//消息唯一标识
new CorrelationData("1"));
log.info("Отправлено сообщение: {}",message);
}
}
@Component
@Slf4j
public class MyCallBack implements RabbitTemplate.ConfirmCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
//将当前实现类,注入到rabbitTemplate中的接口上
//不然到时候rabbitTemplate调用接口时,找不到我们的实现类
rabbitTemplate.setConfirmCallback(this);
}
/*
* 交换机确认回调方法,发消息后,交换机接收到了就回调
* 1.1 correlationData:保存回调消息的ID及相关信息
* 1.2 b:交换机收到消息,为ack=true
* 1.3 s:失败原因,成功为null
*
* 发消息,交换机接受失败,也回调
* 2.1 correlationData:保存回调消息的ID及相关信息
* 2.2 b:交换机没收到消息,为ack=false
* 2.3 s:失败的原因
*
*/
@Override
public void confirm(CorrelationData correlationData, boolean b, String s) {
String id = correlationData!=null ? correlationData.getId():"";
if (b){
log.info("Обменник уже получил информацию с ID: {}",id);
}else {
log.info("Обменник ещё не получил сообщение с ID: {}, причина: {}",id,s);
}
}
}
spring.rabbitmq.publisher-confirm-type=correlated
⚫ NONE — отключить режим подтверждения публикации, это значение по умолчанию. ⚫ CORRELATED — после успешной отправки сообщения на обменник будет вызван метод обратного вызова. ⚫ SIMPLE — подтверждение одной отправки одним сообщением.
Режим SIMPLE: при использовании методов waitForConfirms или waitForConfirmsOrDie из rabbitTemplate для ожидания ответа от узла брокера и на основе этого ответа определения дальнейшей логики, следует обратить внимание на то, что метод waitForConfirmsOrDie возвращает false, что приводит к закрытию канала, и последующие сообщения не могут быть отправлены брокеру.

Выше было сказано, что здесь рассказывается о том, как использовать springboot.
mandatory:
— TRUE: если сообщение не маршрутизируется в очередь, вызывается интерфейс возврата сообщений. — FALSE: если сообщение не маршрутизируется в очередь, предпринимается попытка переслать сообщение на резервный обменник.
Настройка файла конфигурации для включения параметра mandatory со значением true:
spring.rabbitmq.publisher-returns=true
@Component
@Slf4j
public class MyCallBack implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnsCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
...
``` ```
@PostConstruct
public void init() {
// 将当前实现类,注入到rabbitTemplate中的接口上
// 否则到时候rabbitTemplate调用接口时,找不到我们的实现类
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnsCallback(this);
}
/*
* 交换机确认回调方法,发消息后,交换机接收到了就回调
* 1.1 correlationData:保存回调消息的ID及相关信息
* 1.2 b:交换机收到消息,为ack=true
* 1.3 s:失败原因,成功为null
*
* 发消息,交换机接受失败,也回调
* 2.1 correlationData:保存回调消息的ID及相关信息
* 2.2 b:交换机没收到消息,为ack=false
* 2.3 s:失败的原因
*
*/
@Override
public void confirm(CorrelationData correlationData, boolean b, String s) {
String id = correlationData != null ? correlationData.getId() : "";
if (b) {
log.info("交换机已经收到ID为:{}的信息", id);
} else {
log.info(
"交换机还未收到ID为:{}的消息,由于原因:{}", id, s
);
}
}
@Override
public void returnedMessage(ReturnedMessage returnedMessage) {
log.error(
"消息{},被交换机{}退回,退回的原因:{},路由Key:{}",
new String(returnedMessage.getMessage().getBody()),
returnedMessage.getExchange(),
returnedMessage.getReplyText(),
returnedMessage.getRoutingKey()
);
}
@PostMapping("/msg/{message}")
public void sendMessage(@PathVariable String message) {
rabbitTemplate
.convertAndSend(CONFIRM_EXCHANGE_NAME, CONFIRM_ROUTING_KEY, message + "key1", new CorrelationData("1"));
log.info("发送消息内容:{}", message + "key1");
CorrelationData correlationData2 = new CorrelationData("2");
rabbitTemplate
.convertAndSend(
CONFIRM_EXCHANGE_NAME,
CONFIRM_ROUTING_KEY + "2",
message + "key12",
correlationData2
);
log.info("发送消息内容:{}", message + "key12");
}
Резервный обмен
Резервный обмен — это расширение протокола AMQP в RabbitMQ, которое называется Alternate Exchanges в RabbitMQ.
Alternate Exchanges — RabbitMQ
Код для объявления резервного обмена:
@Configuration
public class RabbitConfig {
// Обмен
public static final String CONFIRM_EXCHANGE_NAME = "confirm_exchange";
// Очередь
public static final String CONFIRM_QUEUE_NAME = "confirm_queue";
// RoutingKey
public static final String CONFIRM_ROUTING_KEY = "key1";
// Резервный обмен
public static final String BACKUP_EXCHANGE_NAME = "backup_exchange";
// Резервная очередь
public static final String BACKUP_QUEUE_NAME = "backup_queue";
// Предупреждающая очередь
public static final String WARNING_QUEUE_NAME = "warning_queue";
// Объявление обмена
@Bean
public DirectExchange confirmExchange() {
return ExchangeBuilder.directExchange(CONFIRM_EXCHANGE_NAME).durable(true)
// Указание резервного обмена
.withArgument("alternate-exchange", BACKUP_EXCHANGE_NAME)
.build();
}
// Объявление очереди
@Bean
public Queue confirmQueue() {
return QueueBuilder.durable(CONFIRM_QUEUE_NAME).build();
}
// Резервный обмен --- обычно это тип разветвления
@Bean
public FanoutExchange backupExchange() {
return new FanoutExchange(BACKUP_EXCHANGE_NAME);
}
// Резервная очередь
@Bean
public Queue backupQueue() {
return QueueBuilder.durable(BACKUP_QUEUE_NAME).build();
}
// Предупреждающая очередь
@Bean
public Queue warningQueue() {
return QueueBuilder.durable(WARNING_QUEUE_NAME).build();
}
// Привязка
@Bean
public Binding queueBindingExchange(
@Qualifier("confirmQueue") Queue confirmQueue,
@Qualifier("confirmExchange") DirectExchange confirmExchange
) {
return BindingBuilder.bind(confirmQueue).to(confirmExchange).with(CONFIRM_ROUTING_KEY);
}
@Bean
public Binding backupQueueBindingBackupExchange(
@Qualifier("backupQueue") Queue backupQueue,
@Qualifier("backupExchange") FanoutExchange backupExchange
) {
return BindingBuilder.bind(backupQueue).to(backupExchange);
}
}
``` **Другие процессы и обычный обмен данными очереди и очереди не отличаются**
**Производство. Примечание**
**Компенсация сообщений**
*Основная идея: база данных записывает сообщения, которые были подтверждены пользователем. Затем, сравнивая отправленные производителем сообщения с сообщениями, подтверждёнными потребителем, можно найти потерянные или неподтверждённые сообщения. После этого потребитель уведомляется о повторной отправке.*
*Кроме того, используется механизм отложенной отправки сообщений и служба сравнения по расписанию, что обеспечивает двойную гарантию компенсации сообщений.*
**Как сохранить уникальность сообщений?**
Уникальность — это свойство, при котором результат одного запроса или нескольких запросов пользователя для одной и той же операции одинаков и не вызывает побочных эффектов из-за многократного нажатия.
Простейший пример — оплата. Когда пользователь покупает товар и оплачивает его, платёж успешно списывается. Но если в результате возврата возникает проблема с сетью, деньги уже списаны, а пользователь снова нажимает кнопку, происходит второе списание, и возврат успешен. Однако пользователь обнаруживает, что сумма была списана дважды, а записи в журнале транзакций удвоились.
В старых системах с одним приложением нам нужно было только поместить операцию с данными в транзакцию, чтобы немедленно откатить её в случае ошибки, но также возможно возникновение проблем с сетью или других исключений во время ответа клиенту.
Есть несколько способов обеспечить уникальность сообщений:
1. **Глобальный уникальный идентификатор**
Этот метод имеет серьёзный недостаток, заключающийся в том, что каждый запрос к базе данных требует больших затрат ресурсов, поэтому его не рекомендуется использовать.
2. **Redis setnx**
Причина использования setnx заключается в его уникальности: если ключ уже существует, установка завершится неудачно.
3. **Оптимистическая блокировка**
*Оптимистичная блокировка основана на предположении, что одновременное изменение одних и тех же данных несколькими пользователями маловероятно. Если это всё же произойдёт, то возникнет конфликт, который будет обработан соответствующим образом.*
**Краткое изложение основных процессов обмена данными Rabbitmq**
Существует множество дополнительных параметров для управления процессом связи, которые здесь не перечислены. Вы можете обратиться к предоставленному процессу и продолжить добавлять и улучшать его.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )