Слияние кода завершено, страница обновится автоматически
Этот текст переведен с китайского с помощью JavaGuide от https://www.baeldung.com/java-performance-mapping-frameworks. При перепечатке указывайте исходный URL и имя переводчика.
Создание крупных Java-приложений, состоящих из нескольких слоев, требует использования различных моделей предметной области, таких как модели хранения, предметной области или так называемые DTO. Использование нескольких моделей для различных слоев приложения потребует от нас предоставления методов для отображения bean. Ручное выполнение этой задачи может быстро создать множество шаблонного кода и затратить много времени. К счастью, Java предлагает несколько объектных маппинговых фреймворков. В этом руководстве мы сравним производительность наиболее популярных Java-маппинговых фреймворков.
На основе повседневного использования и тестовых данных я считаю, что фреймворки маппинга bean MapStruct и ModelMapper являются лучшими выборами.
Dozer — это маппинговый фреймворк, который использует рекурсию для копирования данных из одного объекта в другой. Фреймворк не только копирует свойства между bean, но и автоматически преобразует между различными типами.
Чтобы использовать фреймворк Dozer, нам нужно добавить такую зависимость в наш проект:```xml net.sf.dozer dozer 5.5.1
Дополнительная информация о Dozer доступна в официальной документации: http://dozer.sourceforge.net/documentation/gettingstarted.html, или вы можете прочитать эту статью: https://www.baeldung.com/dozer.
### 2.2. Orika
Orika — это фреймворк для маппинга bean к bean, который использует рекурсию для копирования данных из одного объекта в другой.
Принцип работы Orika схож с Dozer, но основное различие заключается в использовании Orika байт-кодового генерирования. Это позволяет создавать более быстрые мапперы с минимальными затратами.
Чтобы использовать фреймворк Orika, нам нужно добавить такую зависимость в наш проект:
```xml
<dependency>
<groupId>ma.glasnost.orika</groupId>
<artifactId>orika-core</artifactId>
<version>1.5.2</version>
</dependency>
Дополнительная информация о Orika доступна в официальной документации: https://orika-mapper.github.io/orika-docs/, или вы можете прочитать эту статью: https://www.baeldung.com/orika-mapping.
MapStruct — это генератор кода для автоматического создания классов маппера bean. MapStruct также может выполнять преобразование между различными типами данных. Github: https://github.com/mapstruct/mapstruct. Для использования фреймворка MapStruct нам необходимо добавить следующую зависимость в наш проект:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.2.0.Final</version>
</dependency>
```Дополнительная информация о MapStruct доступна в официальной документации: https://mapstruct.org/, или вы можете прочитать эту статью: https://www.baeldung.com/mapstruct.
Для использования фреймворка MapStruct нам необходимо добавить следующую зависимость в наш проект:
```xml
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.2.0.Final</version>
</dependency>
ModelMapper — это фреймворк, предназначенный для упрощения объектного отображения. Он определяет способ отображения между объектами на основе соглашений. Он предоставляет безопасный по типам и безопасный при рефакторинге API.
Дополнительная информация о ModelMapper доступна в официальной документации: http://modelmapper.org/.
Для использования фреймворка ModelMapper нам необходимо добавить следующую зависимость в наш проект:
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>1.1.0</version>
</dependency>
JMapper — это фреймворк отображения, предназначенный для предоставления удобного и высокопроизводительного отображения между Java bean. Фреймворк предназначен для применения принципа DRY с использованием аннотаций и отношений отображения. Фреймворк позволяет различным способам конфигурации: на основе аннотаций, XML или на основе API.
Дополнительная информация о JMapper доступна в официальной документации: https://github.com/jmapper-framework/jmapper-core/wiki.Для использования фреймворка JMapper нам необходимо добавить следующую зависимость в наш проект:
<dependency>
<groupId>com.googlecode.jmapper-framework</groupId>
<artifactId>jmapper-core</artifactId>
<version>1.6.0.1</version>
</dependency>
Чтобы корректно тестировать отображение, нам необходимо иметь модель источника и модели цели. Мы уже создали две тестовые модели.
Первая — это простой POJO с одним строковым полем, который позволяет нам сравнивать фреймворки в более простых условиях и проверять, изменится ли что-либо, если мы будем использовать более сложные бины.
Простая модель источника выглядит следующим образом:
public class SourceCode {
String code;
// getter and setter
}
Его модель цели также очень похожа:
public class DestinationCode {
String code;
// getter and setter
}
Пример реального источника бина:
public class SourceOrder {
private String orderFinishDate;
private PaymentType paymentType;
private Discount discount;
private DeliveryData deliveryData;
private User orderingUser;
private List<Product> orderedProducts;
private Shop offeringShop;
private int orderId;
private OrderStatus status;
private LocalDate orderDate;
// стандартные getters и setters
}
Целевой класс представлен ниже:
public class Order {
private User orderingUser;
private List<Product> orderedProducts;
private OrderStatus orderStatus;
private LocalDate orderDate;
private LocalDate orderFinishDate;
private PaymentType paymentType;
private Discount discount;
private int shopId;
private DeliveryData deliveryData;
private Shop offeringShop;
// стандартные getters и setters
}
```Полная структура модели доступна по ссылке: https://github.com/eugenp/tutorials/tree/master/performance-tests/src/main/java/com/baeldung/performancetests/model/source.
## 4. Преобразователи
Чтобы упростить дизайн тестовых настроек, мы создали следующий интерфейс преобразователя:
```java
public interface Converter {
Order convert(SourceOrder sourceOrder);
DestinationCode convert(SourceCode sourceCode);
}
Все наши пользовательские мапперы будут реализовывать этот интерфейс.
Orika поддерживает полное API-реализацию, что значительно упрощает создание мапперов:
public class OrikaConverter implements Converter {
private MapperFacade mapperFacade;
public OrikaConverter() {
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(Order.class, SourceOrder.class)
.field("orderStatus", "status").byDefault().register();
mapperFacade = mapperFactory.getMapperFacade();
}
@Override
public Order convert(SourceOrder sourceOrder) {
return mapperFacade.map(sourceOrder, Order.class);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return mapperFacade.map(sourceCode, DestinationCode.class);
}
}
Dozer требует XML-файла сопоставления, который состоит из следующих частей:
<mappings xmlns="http://dozer.sourceforge.net"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozer.sourceforge.net
http://dozer.sourceforge.net/schema/beanmapping.xsd">
<mapping>
<class-a>com.baeldung.performancetests.model.source.SourceOrder</class-a>
<class-b>com.baeldung.performancetests.model.destination.Order</class-b>
<field>
<a>status</a>
<b>orderStatus</b>
</field>
</mapping>
<mapping>
<class-a>com.baeldung.performancetests.model.source.SourceCode</class-a>
<class-b>com.baeldung.performancetests.model.destination.DestinationCode</class-b>
</mapping>
</mappings>
```После определения XML-файла сопоставления, его можно использовать в коде:
```java
public class DozerConverter implements Converter {
private final Mapper mapper;
public DozerConverter() {
DozerBeanMapper mapper = new DozerBeanMapper();
mapper.addMapping(
DozerConverter.class.getResourceAsStream("/dozer-mapping.xml"));
this.mapper = mapper;
}
@Override
public Order convert(SourceOrder sourceOrder) {
return mapper.map(sourceOrder, Order.class);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return mapper.map(sourceCode, DestinationCode.class);
}
}
Определение MapStruct очень простое, так как оно полностью основано на генерации кода:
@Mapper
public interface MapStructConverter extends Converter {
MapStructConverter MAPPER = Mappers.getMapper(MapStructConverter.class);
@Mapping(source = "status", target = "orderStatus")
@Override
Order convert(SourceOrder sourceOrder);
@Override
DestinationCode convert(SourceCode sourceCode);
}
JMapperConverter требует больше работы. После реализации интерфейса:
public class JMapperConverter implements Converter {
JMapper realLifeMapper;
JMapper simpleMapper;
public JMapperConverter() {
JMapperAPI api = new JMapperAPI()
.add(JMapperAPI.mappedClass(Order.class));
realLifeMapper = new JMapper(Order.class, SourceOrder.class, api);
JMapperAPI simpleApi = new JMapperAPI()
.add(JMapperAPI.mappedClass(DestinationCode.class));
simpleMapper = new JMapper(
DestinationCode.class, SourceCode.class, simpleApi);
}
Для тестирования производительности мы можем использовать Java Microbenchmark Harness. Подробнее о том, как использовать этот инструмент, можно прочитать в этой статье.Для каждого конвертера мы создаем отдельный бенчмарк и задаем режим бенчмаркинга как Mode.All.
Для среднего времени выполнения JMH возвращает следующие результаты (чем меньше, тем лучше):
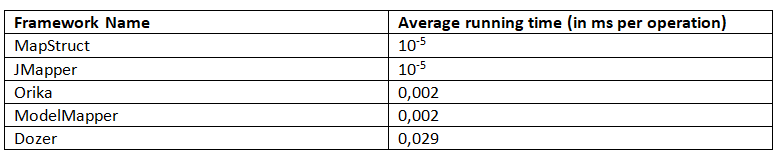
Этот бенчмарк четко показывает, что MapStruct и JMapper имеют наилучшее среднее время выполнения.
В этом режиме бенчмарк возвращает количество операций в секунду. Мы получаем следующие результаты (чем больше, тем лучше):

Эти результаты показывают, что ModelMapper имеет наилучшую пропускную способность, что делает его оптимальным выбором для задач, требующих высокой производительности.

В режиме пропускной способности MapStruct является самой быстрой библиотекой в тестовом фреймворке, за ней следует JMapper.
Этот режим позволяет измерять время выполнения от начала до конца для одного операционного действия. Бенчмарки показывают следующие результаты (чем меньше, тем лучше):
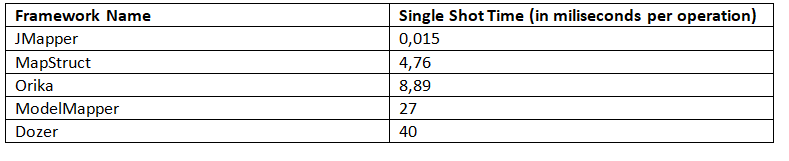
Здесь мы видим, что результаты, возвращаемые JMapper, значительно превосходят результаты MapStruct.### 5.4. Время выборки
Этот режим позволяет измерять время выполнения для каждого операционного действия. Результаты для трех различных процентилей представлены ниже:
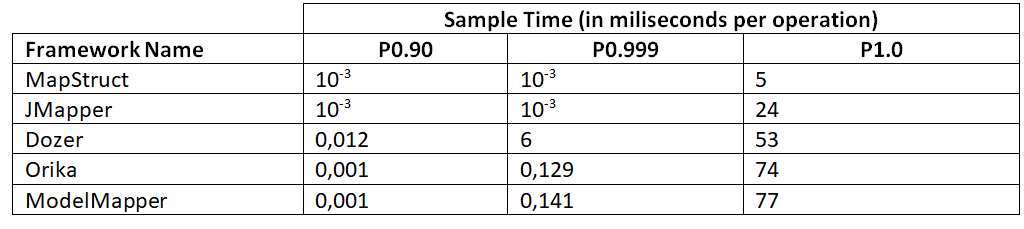
Все бенчмарки показывают, что в зависимости от сценария MapStruct и JMapper являются хорошими выборами, хотя результаты для режима SingleShotTime у MapStruct значительно хуже.
Для тестирования производительности можно использовать Java Microbenchmark Harness. Подробнее о том, как использовать этот инструмент, можно прочитать в этой статье: https://www.baeldung.com/java-microbenchmark-harness.
Мы создали отдельные бенчмарки для каждого конвертера и указали режим бенчмаркинга как Mode.All.
JMH возвращает следующие результаты среднего времени выполнения (чем меньше, тем лучше):

Эти бенчмарки четко показывают, что MapStruct и JMapper имеют наилучшее среднее время выполнения.
В этом режиме бенчмарки возвращают количество операций, выполненных за секунду. Мы получили следующие результаты (чем больше, тем лучше):

В режиме пропускной способности MapStruct является самой быстрой библиотекой в тестовом фреймворке, за ней следует JMapper.### 6.4. Время выборки
Этот режим позволяет измерять время выполнения для каждого операционного действия. Результаты для трех различных процентилей представлены ниже:
Хотя точные результаты для простых примеров и реальных моделей значительно различаются, их тенденции схожи. Оба примера показывают похожие результаты относительно того, какой алгоритм самый быстрый и какой самый медленный.
На основе проведённых нами тестов реальных моделей в данной секции можно сделать вывод, что лучшая производительность безусловно принадлежит MapStruct. В тех же тестах мы также видим, что Dozer всегда находится в самом низу результативной таблицы.
В данной статье мы провели тестирование производительности пяти популярных Java Bean маппинговых фреймворков: ModelMapper, MapStruct, Orika, Dozer, JMapper.
Примеры кода доступны по адресу: https://github.com/eugenp/tutorials/tree/master/performance-tests.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )