Слияние кода завершено, страница обновится автоматически
Сбор данных с сайта Лагу, их анализ, визуализация и анализ того, какой город и какая должность наиболее востребованы.
Если вы впервые читаете этот учебник, можете начать с самого начала: Сканер, от основ до продвинутого уровня (1) Подписывайтесь на официальный аккаунт WeChat: Экстремально простой XksA WeChat ID: xksnh888 Перепечатка, пожалуйста, свяжитесь с WeChat ID: zs820553471 Обмен и обучение
pip install requests
pip install cvs
pip install pandas
pip install numpy
pip install jieba
pip install re
pip install pyecharts
pip install os
Зачем собирать данные с Лагу? Ха-ха, конечно, потому что это просто, вуаля, причины следующие: (1) Динамическая веб-страница, сложнее для сбора данных, более содержательно при объяснении; (2) В отличие от обычных ситуаций, мы не можем получить нужные нам данные через запросы get, нам нужно проанализировать страницу.
# Мы обычно используем процесс: скопируйте URL-адрес веб-страницы -> отправьте запрос get -> распечатайте содержимое страницы -> проанализируйте сбор данных
# 1. Получить URL-адрес Лагу
req_url = 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput='
# 2. Отправить запрос get
req_result = requests.get(req_url)
# 3. Распечатайте результат запроса
print(req_result.text)
Из этого процесса выводится следующий результат:
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta name="renderer" content="webkit">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<script type="text/javascript" src="https://www.lagou.com/utrack/trackMid.js?version=1.0.0.3&t=1529144464"></script>
<body>
<input type="hidden" id="KEY" value="VAfyhYrvroX6vLr5S9WNrP16ruYI6aYOZIwLSgdqTWc"/>
<script type="text/javascript">HZRxWevI();</script>
é?μé?¢?? è????-...
<script type="text/javascript" src="https://www.lagou.com/upload/oss.js"></script>
</body>
</html>
Можно видеть, что ситуация сильно отличается от ожидаемой. Почему это происходит? Это очень просто, потому что это не простая статическая страница. Мы знаем, что есть два основных различия между запросами get и post:
(1) Get — это тип запроса, который запрашивает данные у сервера; Post — это тип запроса, который отправляет данные на сервер, и данные находятся в теле сообщения после.
GET и POST — это только разные способы отправки, а не один получает, другой отправляет.
(2) Запрос get отправляет информацию в виде открытого текста в URL-адресе, параметры сохраняются в истории браузера или на сервере веб-сайта,
а post не будет (это также причина, по которой мы обнаруживаем, что URL-адрес страницы не меняется при переходе на следующую страницу на Лагу).
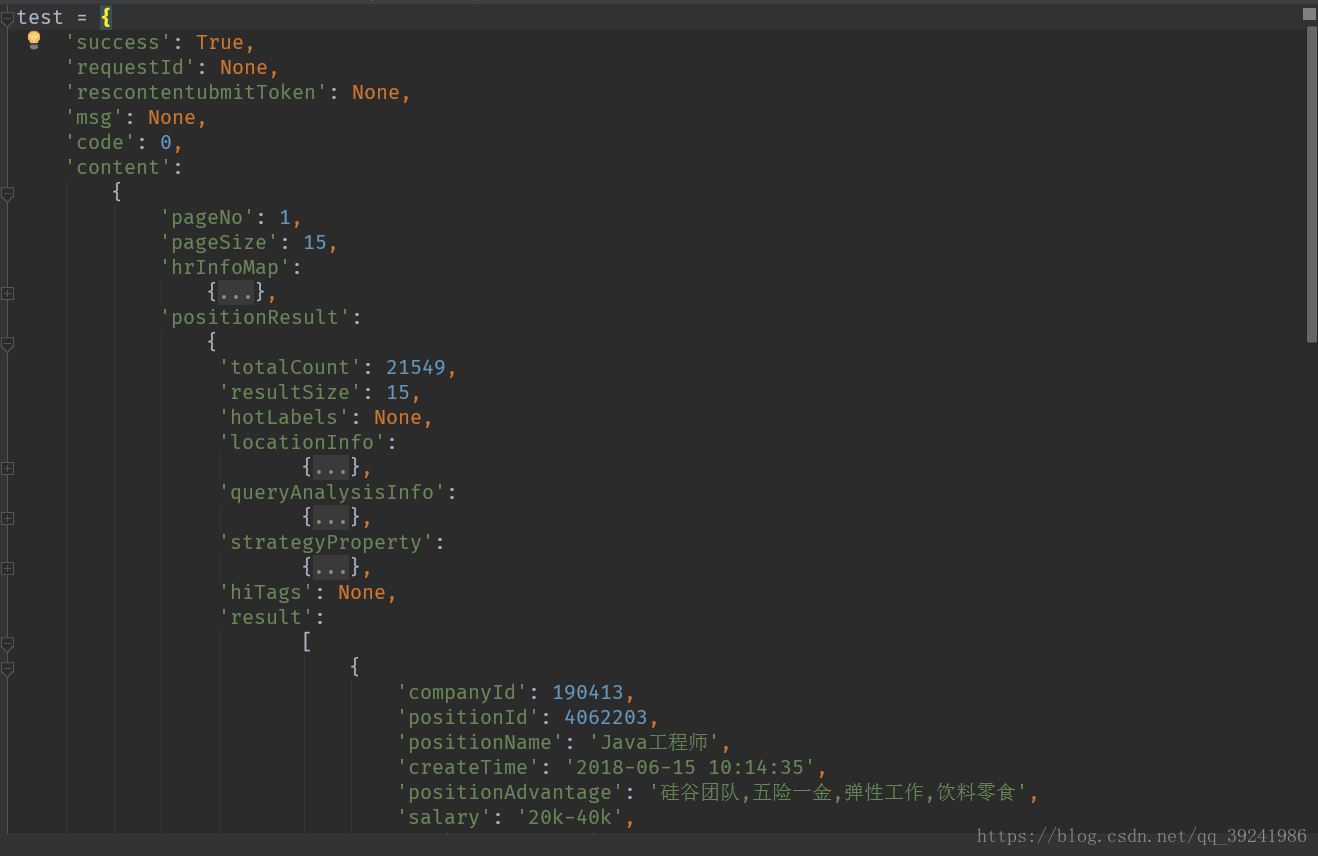
json данные организованы следующим образом: Я организовал данные, полученные из json, следующим образом:
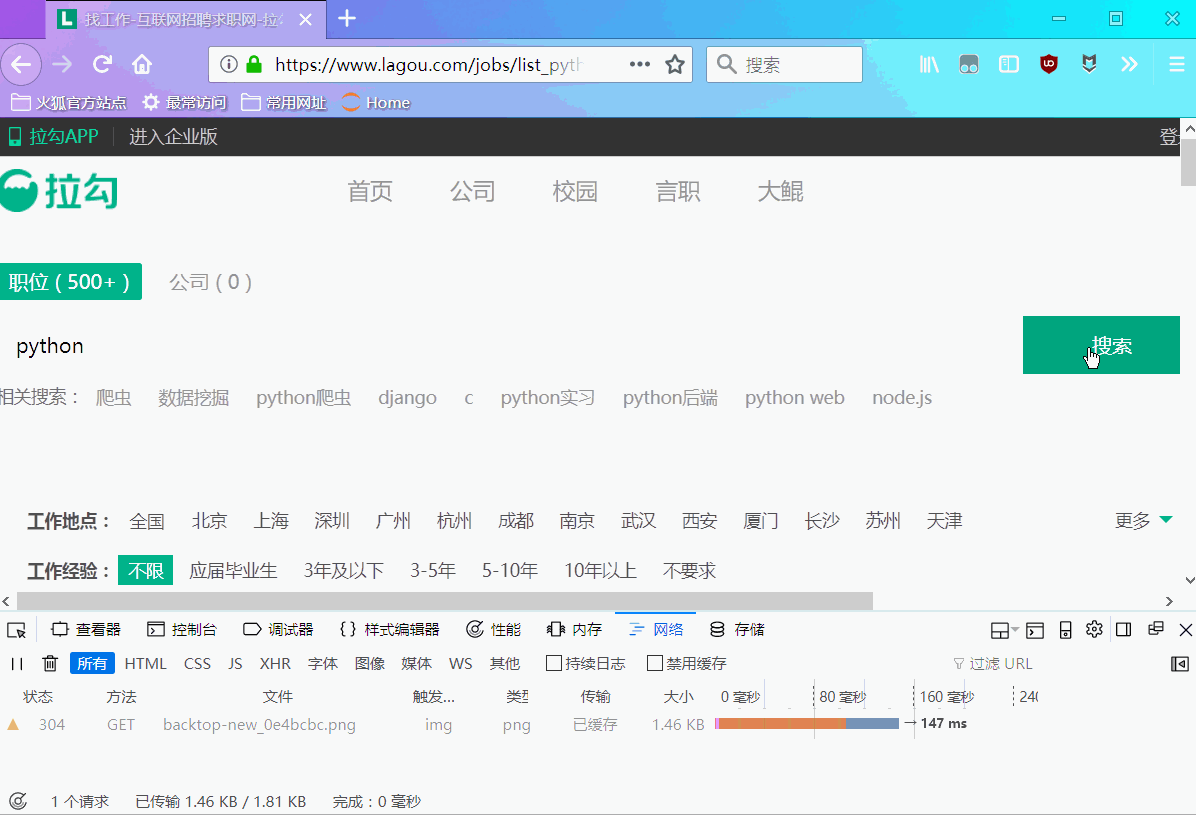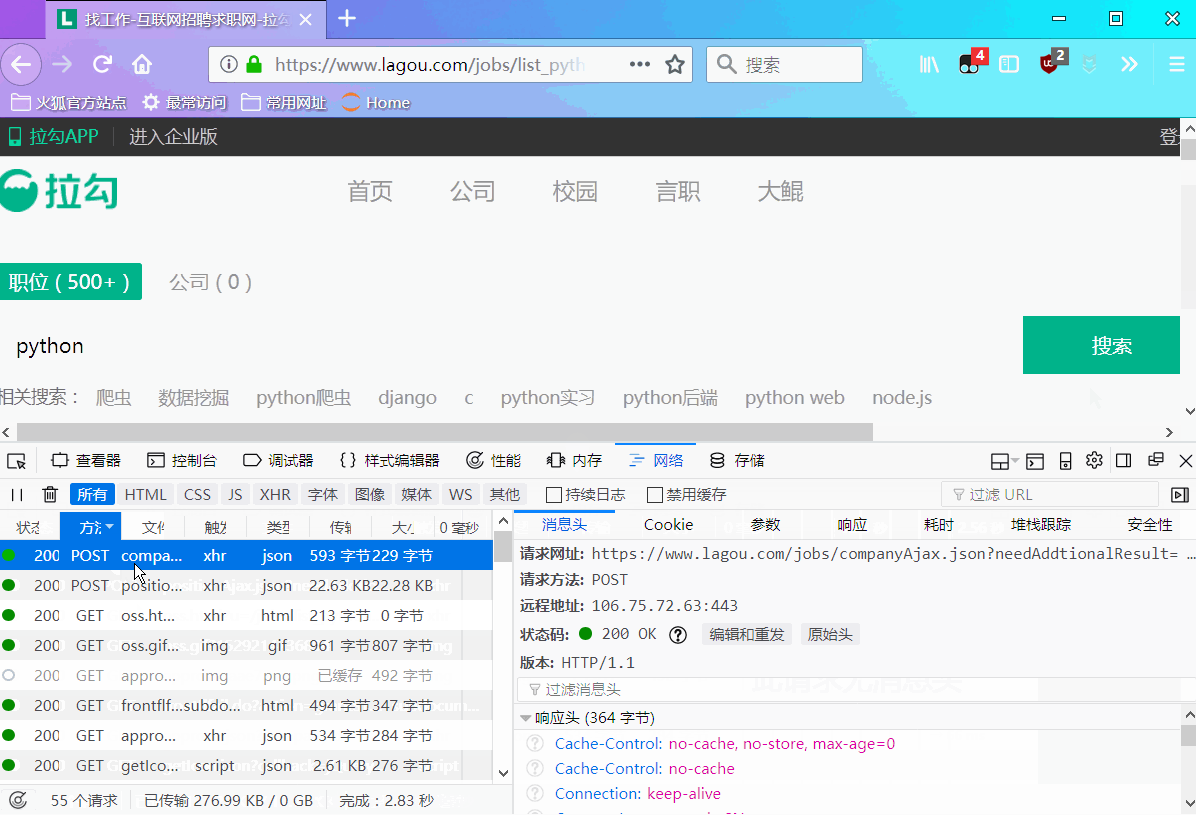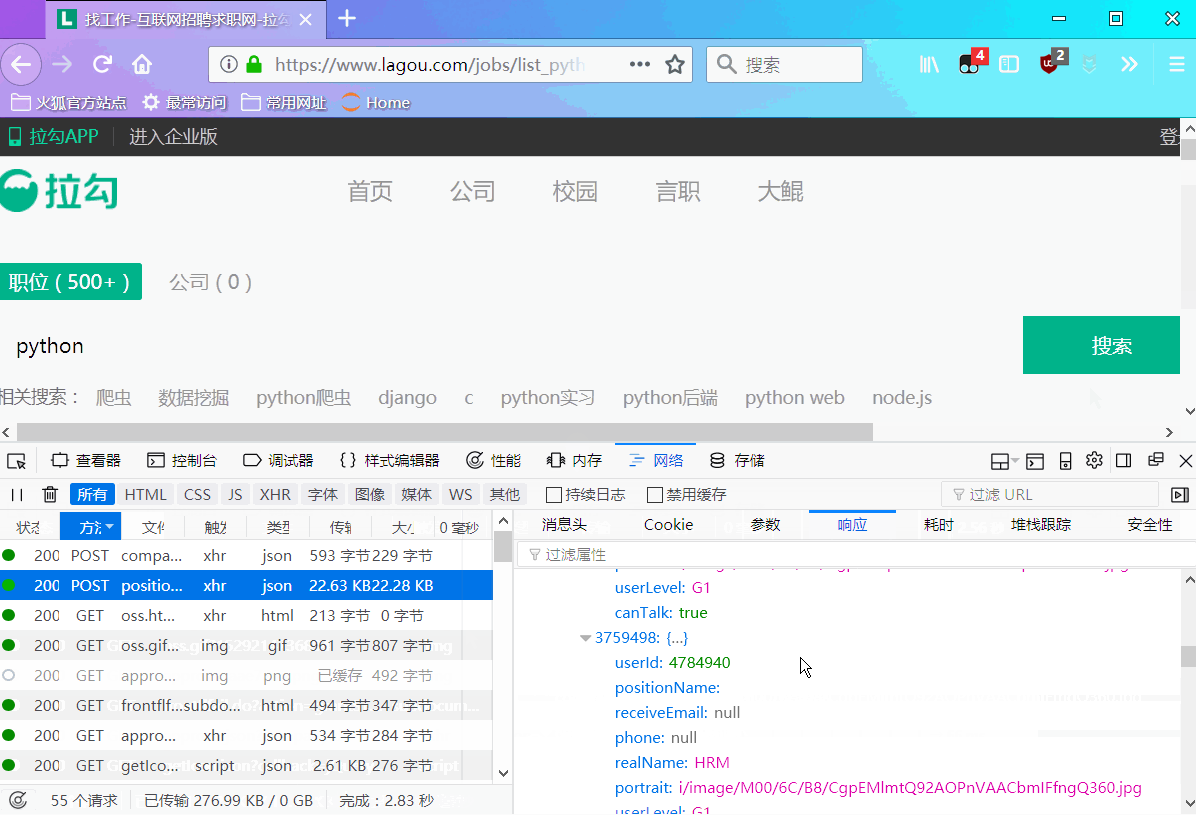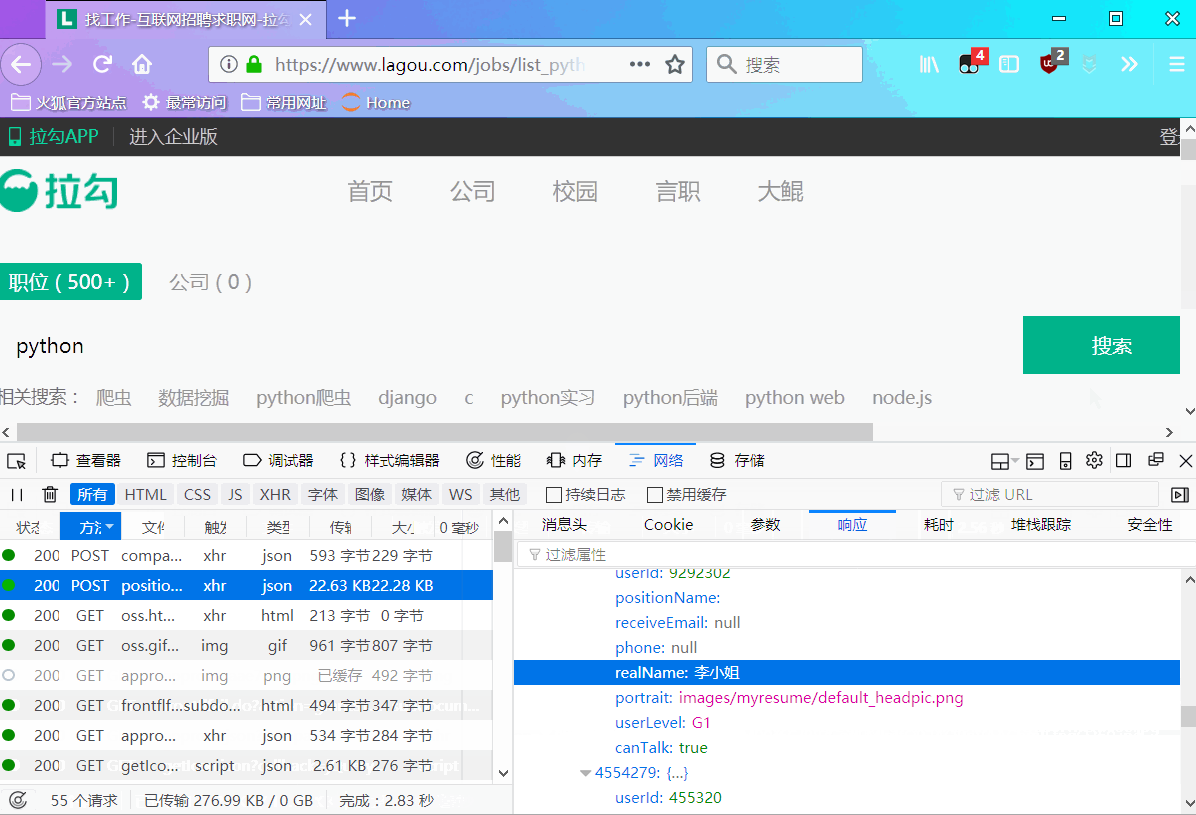
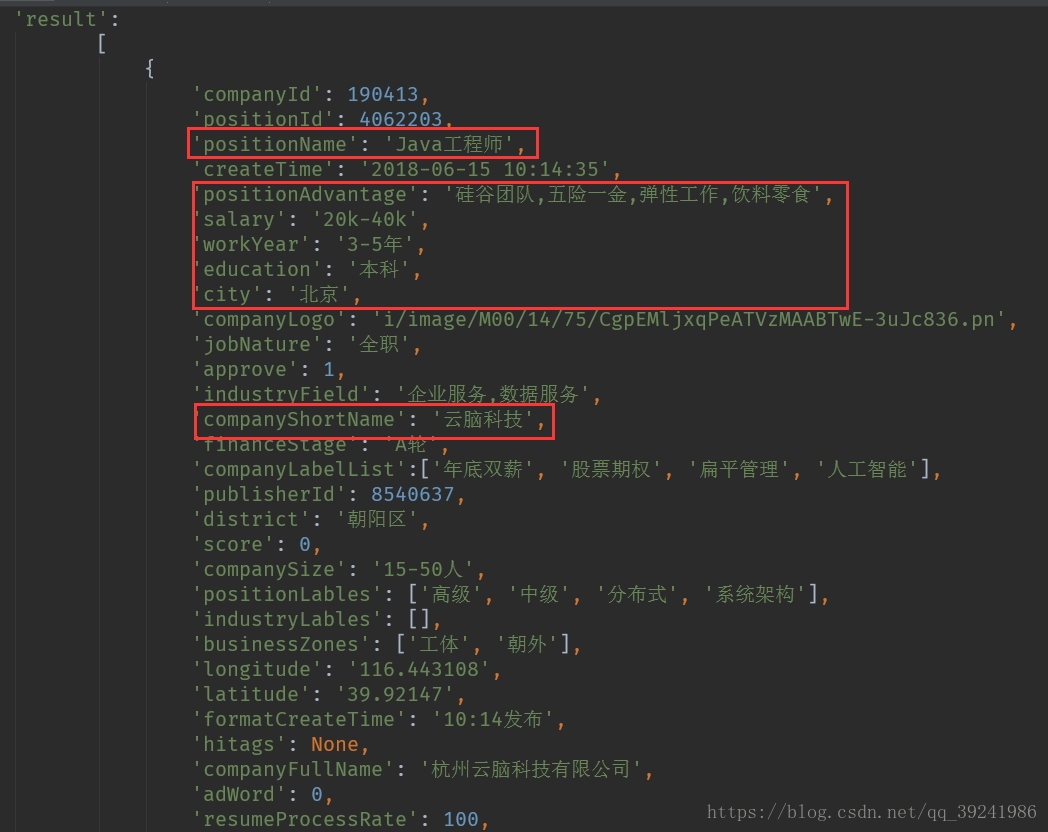
Мы увидим, что нужные нам данные находятся внутри: req_info['content']['positionResult']['result'], который представляет собой список, и в нём также содержится много других данных. В этом случае нас не интересуют другие данные. Данные, которые нам нужны, показаны на следующем рисунке:
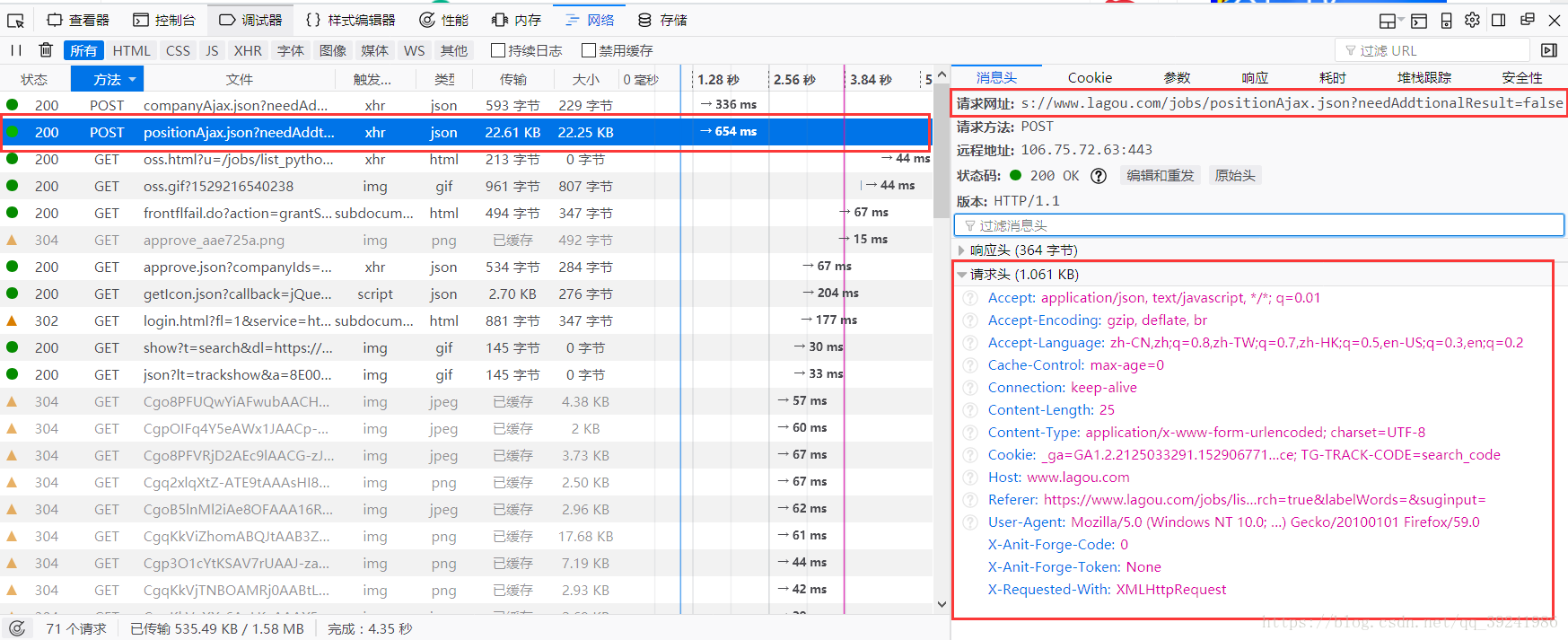
Из анализа запроса мы можем найти URL-адрес запроса post как: https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false, если мы отправим запрос post напрямую, мы получим следующее сообщение об ошибке:
{'success': False, 'msg': 'Вы слишком часто выполняете операции, пожалуйста, подождите некоторое время и повторите попытку', 'clientIp': '122.xxx.xxx.xxx'}
Причина этой ошибки заключается в том, что мы непосредственно отправляем запрос post, и сервер ошибочно принимает нас за «робота», это своего рода анти-сканирование, решение простое, добавьте заголовок запроса, чтобы полностью имитировать запрос браузера, информация заголовка запроса показана на следующем рисунке:
first, kd, pn, через диаграмму мы можем легко догадаться об их значении: ```
first: true, # Является ли страница первой, false означает, что не является, true означает, что является
kd: Python, # Ключевое слово поиска
pn: 1 # Номер страницы
}
**Код на Python для поиска вакансий на сайте Lagou.com:**
```Python
import requests
# 1. URL запроса POST
req_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 2. Заголовок запроса headers
headers = {'Ваш заголовок запроса'}
# 3. Цикл запроса for
for i in range(1, 31):
data = {
'first': 'false',
'kd': 'Python',
'pn': i
}
# 3.1 Запрос requests.post
req_result = requests.post(req_url, headers=headers, data=data)
req_result.encoding = 'utf-8'
# 3.2 Получение данных
req_info = req_result.json()
# Вывод полученных данных на экран
print(req_info)
Функция для сохранения данных в CSV-файл:
def file_do(list_info):
# Получение размера файла
file_size = os.path.getsize(r'G:\lagou_test.csv')
if file_size == 0:
# Заголовок таблицы
name = ['Компания', 'Город', 'Должность', 'Зарплата', 'Требования к образованию', 'Опыт работы', 'Преимущества должности']
# Создание объекта DataFrame
file_test = pd.DataFrame(columns=name, data=list_info)
# Запись данных в файл
file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk', index=False)
else:
with open(r'G:\lagou_test.csv','a+',newline='') as file_test :
# Добавление данных в конец файла
writer = csv.writer(file_test)
# Запись данных в файл
writer.writerows(list_info)
Простой пример данных, полученных с помощью функции:
Здесь будет изображение.
Анализ данных и визуализация с использованием Pyechart:
Здесь будет изображение.
Мы можем видеть, что зарплата в сфере Python обычно начинается от 10 тысяч и находится в диапазоне от 10 до 40 тысяч. Поэтому не стоит бояться, что работа программистом на Python не принесёт достаточного дохода.
Здесь будет изображение.
Из диаграммы мы видим, что большинство компаний, ищущих программистов на Python, находятся в Пекине, Шанхае и Шэньчжэне. Следующим по популярности является город Гуанчжоу.
Здесь будет изображение.
Согласно диаграмме, требования к уровню образования для программистов на Python невысоки, и большинство вакансий требуют наличия высшего образования.
Здесь будет изображение.
В основном требуются кандидаты с опытом работы от 3 до 5 лет. Это говорит о том, что компании ищут опытных специалистов, которые могут быстро адаптироваться к новым задачам.
Здесь будет изображение.
Основным направлением является разработка, без уточнения конкретных областей.
Здесь будет изображение.
Преимуществом работы является возможность развития в области разработки.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.

Комментарии ( 0 )