Слияние кода завершено, страница обновится автоматически
Этот проект использует ESP32-S3 для реализации кастомного AI-ассистента для голосового общения (например, в роли врача). Проект позволяет ознакомиться с разработкой на ESP32-S3 с использованием Arduino, API для распознавания и синтеза речи от Baidu, API Baidu APPBuilder для создания кастомных ролей, обучением кастомных слов для пробуждения, чтением и записью на SD-карте, использованием сенсорного экрана, настройкой Wi-Fi (методом smartconfig). Все программное и аппаратное обеспечение проекта открыто, и к нему прилагаются подробные руководства и видео-уроки, что делает его особенно полезным для начинающих. Надеемся, что этот проект поможет вам.
https://gitee.com/chging/esp32s3-ai-chat
【Пространство автора - Bilibili】 https://b23.tv/AsFNSeJ
Я использую сервис Quark для размещения файла «ESP32-S3-AI-Chat-V2.docx». Нажмите ссылку для загрузки. Откройте приложение Quark для просмотра, поддерживает различные форматы документов.# Ссылки на покупку AI-интеграционного пакета

Ссылка на покупку: https://h5.m.taobao.com/awp/core/detail.htm?ft=t&id=833542085705



Дважды щелкните скачанный установочный файл и следуйте инструкциям на следующем рисунке:




Подождите немного, установка завершена.


Для этого проекта необходимо установить пакет для микросхемы ESP32. Можно сначала попробовать установить его через онлайн-установку, если это не удастся, можно использовать офлайн-установку.
Откройте Arduino IDE, выберите Файл -> Параметры -> Установка.
Вставьте следующую ссылку в поле адреса менеджера плат:
https://raw.githubusercontent.com/espressif/arduino-esp32/gh-pages/package_esp32_dev_index.json
Затем нажмите ОК, Сохранить.



Если установка не удалась из-за постоянных ошибок загрузки, можно использовать офлайн-установку.
Прямая загрузка установочного пакета:Я разместил файл «esp32.rar» на Quark Cloud, нажав на ссылку можно сохранить файл. Ссылка:https://pan.quark.cn/s/61d4a28219bb
Выберите путь для разархивации. Разместите его в соответствующую папку пакета устройств Arduino для пользователя. Ниже приведены пути установки для различных версий Arduino:C:\Users\Имя_пользователя\AppData\Local\Arduino15\packages


Внимание: AppData — скрытая папка, для просмотра которой необходимо настроить опции просмотра папок, чтобы увидеть скрытые папки. В данном случае имя пользователя — Administrator.

Для данного проекта необходимо установить следующие онлайн-библиотеки и оффлайн-библиотеки.
Arduino позволяет искать и устанавливать необходимые библиотеки непосредственно через менеджер библиотек.
| Название библиотеки | Версия |
|---|---|
| ArduinoJson | 7.1.0 |
| base64 | 1.3.0 |
| UrlEncode | 1.0.1 |
| lvgl | 8.5.10 |
| TFT_eSPI | 2.5.43 |
| bb_captouch | 1.2.2 |

Установка завершена, как показано на следующем рисунке. Если требуется удалить библиотеку, нажмите Удалить.
Установите base64, используя ту же процедуру.



Измените User_Setup_Select.h. В папке установки библиотек Arduino.







Откройте файл lv_conf.h и замените #if 0 на #if 1 в начале файла.
Замените #define LV_TICK_CUSTOM 0 на #define LV_TICK_CUSTOM 1 на строке 88 (важно! Это активирует собственный таймер, иначе анимации не будут работать, а FPS будет равен 1).


Переместите папку \lvgl\demos\ в \lvgl\src\demos.

Я разместил файл test_ui.zip на Quake Cloud, перейдя по ссылке можно скачать.
Ссылка: https://pan.quark.cn/s/fd4657269252
Скачайте архив, распакуйте его и скопируйте в папку lvgl\src.

 ### Установка оффлайн-библиотек
Arduino может напрямую импортировать оффлайн-библиотеки для установки. В данном проекте требуется установить оффлайн-библиотеку для обучения активирующего слова. Ниже представлены библиотеки, которые я сам обучил. Если у вас нет обученной библиотеки, вы можете использовать мою активирующую библиотеку для импорта. Если вы хотите обучить свою собственную активирующую библиотеку, подробная инструкция находится в разделе 6.#### Необходимые для установки оффлайн-библиотеки
### Установка оффлайн-библиотек
Arduino может напрямую импортировать оффлайн-библиотеки для установки. В данном проекте требуется установить оффлайн-библиотеку для обучения активирующего слова. Ниже представлены библиотеки, которые я сам обучил. Если у вас нет обученной библиотеки, вы можете использовать мою активирующую библиотеку для импорта. Если вы хотите обучить свою собственную активирующую библиотеку, подробная инструкция находится в разделе 6.#### Необходимые для установки оффлайн-библиотеки
| Название библиотеки |
|---|
| wakeup_detect_houguoxiong_inferencing |



Перед использованием API Baidu, необходимо запросить ключ API на платформе Baidu Cloud. После получения ключа и активации соответствующего API, можно начать его использование.
Ссылка на платформу Baidu Cloud: https://cloud.baidu.com/

Сначала необходимо создать ключ API для распознавания речи.

Нажмите Начать использование, откроется страница входа в аккаунт Baidu. Войдите или зарегистрируйтесь с помощью номера телефона.
После регистрации необходимо пройти процедуру верификации личности, следуйте инструкциям ниже.

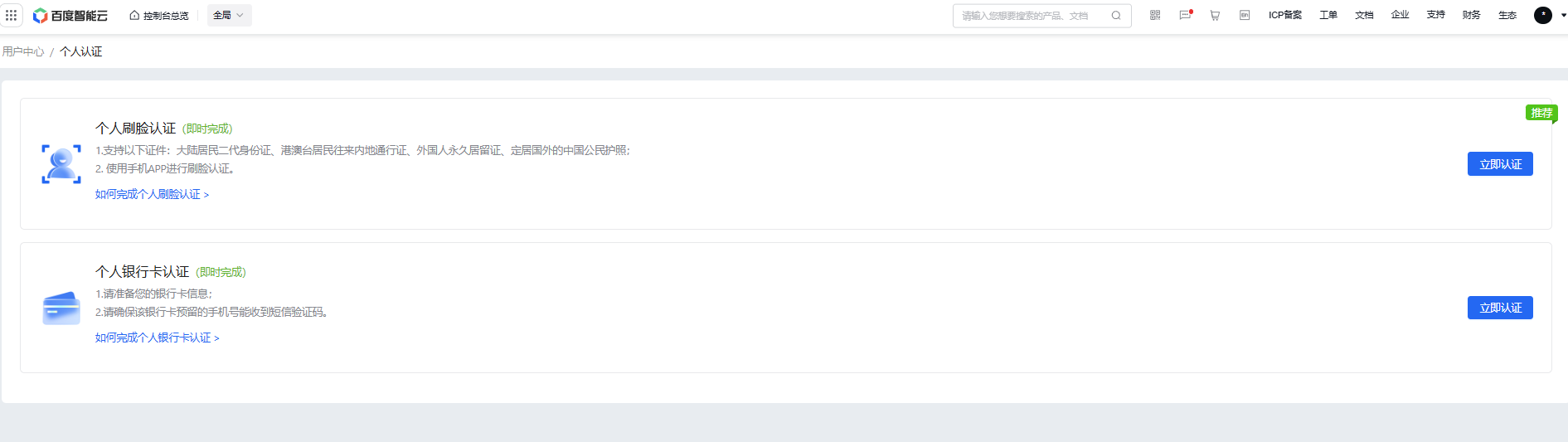








В списке приложений вы увидите созданное вами приложение, а также сможете получить доступ к API Key и Secret Key. Эти ключи вам потребуются для доступа к API распознавания речи.
Далее вам потребуется активировать услугу распознавания речи. Нажмите на Обзор -> Распознавание речи -> Краткосрочное распознавание речи -> Активировать.


В результате API key для распознавания речи успешно получен, а также услуга активирована.В тексте отсутствуют строки для перевода. Пожалуйста, предоставьте текст для перевода.БaiduXuesinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьsinьПерейдите на главную страницу платформы Baidu Intelligent Cloud, нажмите на выбор Qianfan Large Model Application Development Platform AppBuilder.
Нажмите на Начать использование.






После активации вышеуказанных API-сервисов, вы можете провести онлайн-тестирование, чтобы убедиться, что сервисы успешно активированы.

 3. Перейдите на страницу тестирования API и примеры кода, на этой странице вы можете протестировать распознавание речи Baidu, синтез речи и модели Wenxin Yiyan.
3. Перейдите на страницу тестирования API и примеры кода, на этой странице вы можете протестировать распознавание речи Baidu, синтез речи и модели Wenxin Yiyan.
Здесь вы можете сначала протестировать вызов API синтеза речи, потому что этот вызов API можно напрямую заполнить текстом в качестве входных данных, а распознавание речи требует передачи аудиоданных в качестве входных данных. Поэтому сначала протестируйте синтез речи, а затем сохраните сгенерированный аудиофайл для последующего тестирования распознавания речи.



 5. Затем проверьте, успешно ли активирован API-сервис для синтеза речи. Нажмите Speech Synthesis -> Synthesize Short Text Online, затем введите текст для синтеза аудио, выберите голос, настройте скорость, тональность и громкость, выберите формат аудиофайла wav, и нажмите Synthesize.
5. Затем проверьте, успешно ли активирован API-сервис для синтеза речи. Нажмите Speech Synthesis -> Synthesize Short Text Online, затем введите текст для синтеза аудио, выберите голос, настройте скорость, тональность и громкость, выберите формат аудиофайла wav, и нажмите Synthesize.




Нажмите Отладка, если выполнение прошло успешно, просмотрите результаты отладки, чтобы проверить правильность распознавания речи в ответных данных. Таким образом, мы можем проверить, успешно ли активирован API-сервис для распознавания речи.
Также нажмите Примеры кода, здесь представлены реализации вызова API на различных языках программирования.

Для тестирования API-сервисов существует универсальный инструмент, который широко используется и позволяет проверять, работают ли API-сервисы корректно.


Нажмите Пример кода -> Curl -> Копировать код.





Основная программа AI Agent находится в esp32s3-ai-chat\ai-all\esp32s3_ai_chat_all\esp32s3_ai_chat_all.ino, откроем проект, внесем изменения в настройки Wi-Fi и ключ API, скомпилируем код и загрузим его на плату для тестирования.


Нажмите на поле выбора разработки, выберите разработку и порт, разработка ESP32S3 Dev Module, порт соответствует последнему отображаемому порту после подключения USB typeC (можно проверить через диспетчер устройств).


Используйте "houguoxiong" для пробуждения ESP32-S3 для диалога. Или просто коснитесь экрана (непрерывное касание для записи, отпускание для завершения записи, система начинает процесс распознавания речи и обращения к модели), чтобы пробудить ESP32-S3 для диалога.
 ## Реализация основных модулей и анализ кода
## Реализация основных модулей и анализ кода
Этот модуль реализует функцию пробуждения по ключевому слову, обученному самостоятельно. esp32s3-ai-chat/example/wake_detect этот проект в основном реализует функцию пробуждения по ключевому слову. На основе этого проекта можно разрабатывать AI голосовые чаты.
Основная реализация кода:
#include <wakeup_detect_houguoxiong_inferencing.h>
/* Edge Impulse Arduino examples
* Copyright (c) 2022 EdgeImpulse Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
// Если ваша целевая система ограничена по памяти, удалите этот макрос, чтобы сэкономить OnClickListener 10КБ ОЗУ
#define EIDSP_QUANTIZE_FILTERBANK 0
```/*
** ЗАМЕЧАНИЕ: Если вы столкнулись с проблемой выделения памяти для TFLite.
**
** Это может быть связано с динамическим фрагментированием памяти.
** Попробуйте определить "-DEI_CLASSIFIER_ALLOCATION_STATIC" в boards.local.txt (создайте, если он не существует) и скопируйте этот файл в
** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.
**
** См. (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)
** чтобы найти, где Arduino устанавливает ядра на вашем компьютере.
**
** Если проблема сохраняется, то у вас недостаточно памяти для этой модели и приложения.
*/
```/* Включение библиотек ---------------------------------------------------------------- */
#include <driver/i2s.h>```c
#define Частота_выборки 16000U
#define LED_встроенного 21
// Конфигурация INMP441
#define I2S_IN_ПОРТ I2S_NUM_0
#define I2S_IN_BCLK 4
#define I2S_IN_LRC 5
#define I2S_IN_DIN 6
/** Буферы аудио, указатели и селекторы */
typedef struct {
int16_t *буфер;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static const uint32_t sample_buffer_size = 2048;
static signed short sampleBuffer[sample_buffer_size];
static bool debug_nn = false; // Установите это значение в true, чтобы увидеть, например, характеристики, сгенерированные из исходного сигнала
static bool record_status = true;
/**
* @brief Функция настройки Arduino
*/
void setup() {
// поместите ваш код настройки здесь, чтобы выполнить его один раз:
Serial.begin(115200);
// закомментируйте нижеприведенную строку, чтобы отменить ожидание подключения USB (необходимо для нативного USB)
while (!Serial)
;
Serial.println("Edge Impulse Inferencing Demo");
pinMode(LED_встроенного, OUTPUT); // Установите пин как выход
digitalWrite(LED_встроенного, HIGH); // Выключить
// Инициализация I2S для входного аудио
i2s_config_t i2s_config_in = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = Частота_выборки,
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, // Обратите внимание: INMP441 выдает 32-битные данные
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = i2s_comm_format_t(I2S_COMM_FORMAT_STAND_I2S),
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 1024,
};
i2s_pin_config_t pin_config_in = {
.bck_io_num = I2S_IN_BCLK,
.ws_io_num = I2S_IN_LRC,
.data_out_num = -1,
.data_in_num = I2S_IN_DIN
};
i2s_driver_install(I2S_IN_ПОРТ, &i2s_config_in, 0, NULL);
i2s_set_pin(I2S_IN_ПОРТ, &pin_config_in);
}
``` // Обзор настроек инференса (из model_metadata.h)
ei_printf("Настройки инференса:\n");
ei_printf("\tИнтервал: ");
ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf(" мс.\n");
ei_printf("\tРазмер кадра: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tДлина выборки: %d мс.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tКоличество классов: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));```markdown
ei_printf("\nНачинается непрерывное инференсирование через 2 секунды...\n");
ei_sleep(2000);
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ERR: Не удалось выделить буфер аудио (размер %d), это может быть связано с длиной окна вашего модели\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
ei_printf("Запись...\n");
}
/**
* @brief Основная функция Arduino. Запускает цикл инференсирования.
*/
void loop() {
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Не удалось записать аудио...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Не удалось запустить классификатор (%d)\n", r);
return;
}
int pred_index = 0; // Инициализация pred_index
float pred_value = 0; // Инициализация pred_value
// вывод предсказаний
ei_printf("Предсказания ");
ei_printf("(DSP: %d мс., Классификация: %d мс., Аномалия: %d мс.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");```md
if (result.classification[ix].value > pred_value) {
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// Отображение результата инференсирования
if (pred_index == 3) {
digitalWrite(LED_BUILT_IN, LOW); // Включение
} else {
digitalWrite(LED_BUILT_IN, HIGH); // Выключение
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
static void audio_inference_callback(uint32_t n_bytes) {
for (int i = 0; i < n_bytes >> 1; i++) {
inference.buffer[inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
static void capture_samples(void *arg) {
const int32_t i2s_bytes_to_read = (uint32_t)arg;
size_t bytes_read = i2s_bytes_to_read;
}
``` while (record_status) {
/* Чтение данных за один раз из i2s - Модифицировано для XIAO ESP2S3 Sense и библиотеки I2S.h */
i2s_read(I2S_IN_PORT, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
// esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void *)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
if (bytes_read <= 0) {
ei_printf("Ошибка при чтении I2S: %d", bytes_read);
} else {
if (bytes_read < i2s_bytes_to_read) {
ei_printf("Частичное чтение I2S");
}
// масштабирование данных (иначе звук будет слишком тихим)
for (int x = 0; x < i2s_bytes_to_read / 2; x++) {
sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;
}
if (record_status) {
audio_inference_callback(i2s_bytes_to_read);
} else {
break;
}
}
}
vTaskDelete(NULL);
}
/**
* @brief Инициализация структуры инференса и настройка/запуск PDM
*
* @param[in] n_samples количество образцов
*
* @return true если инициализация успешна, иначе false
*/
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
}
``````markdown
```cpp
if (inference.buffer == NULL) {
return false;
}
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// if (i2s_init(EI_CLASSIFIER_FREQUENCY)) {
// ei_printf("Не удалось запустить I2S!");
// }
ei_sleep(100);
record_status = true;
xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void *)sample_buffer_size, 10, NULL);
return true;
}
/**
* @brief Ожидание новых данных
*
* @return true если завершено, иначе false
*/
static bool microphone_inference_record(void) {
bool ret = true;
while (inference.buf_ready == 0) {
delay(10);
}
inference.buf_ready = 0;
return ret;
}
/**
* Получение данных аудиосигнала
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
/**
* @brief Остановка PDM и освобождение буферов
*/
static void microphone_inference_end(void) {
free(sampleBuffer);
ei_free(inference.buffer);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Недопустимая модель для текущего датчика."
#endif
// Инициализация I2S для аудиовхода
i2s_config_t i2s_config_in = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, // Обратите внимание: INMP441 выдает 32-битные данные
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = i2s_comm_format_t(I2S_COMM_FORMAT_STAND_I2S),
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 1024,
};
i2s_pin_config_t pin_config_in = {
.bck_io_num = I2S_IN_BCLK,
.ws_io_num = I2S_IN_LRC,
.data_out_num = -1,
.data_in_num = I2S_IN_DIN
};
i2s_driver_install(I2S_IN_PORT, &i2s_config_in, 0, NULL);
i2s_set_pin(I2S_IN_PORT, &pin_config_in);
```3. Инициализация интерфейса для обнаружения слов-вызывателей.
```cpp
// Обзор настроек для инференса (из model_metadata.h)
ei_printf("Настройки для инференса:\n");
ei_printf("\tИнтервал: ");
ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf(" мс.\n");
ei_printf("\tРазмер кадра: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tДлина образца: %d мс.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tКоличество классов: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
ei_printf("\nЗапуск непрерывного инференса через 2 секунды...\n");
ei_sleep(2000);
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ОШИБКА: Не удалось выделить буфер для аудио (размер %d), это может быть связано с длиной окна модели\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
```
4. Эта функция инициализации создает задачу FreeRTOS, которая предназначена для реального времени сбора аудиоданных.
```cpp
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if (inference.buffer == NULL) {
return false;
}
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
ei_sleep(100);
record_status = true;
xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void *)sample_buffer_size, 10, NULL);
return true;
}
```
5. Задача по реальному времени для сбора аудиоданных, которая сохраняет собранные данные в глобальную переменную данных sampleBuffer.
```cpp
static void capture_samples(void *arg) {
const int32_t i2s_bytes_to_read = (uint32_t)arg;
size_t bytes_read = i2s_bytes_to_read;
while (record_status) {
``` /* Чтение данных из i2s за один раз - Модифицировано для XIAO ESP2S3 Sense и библиотеки I2S.h */
i2s_read(I2S_IN_PORT, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
// esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void *)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);```markdown
if (bytes_read <= 0) {
ei_printf("Ошибка при чтении I2S : %d", bytes_read);
} else {
if (bytes_read < i2s_bytes_to_read) {
ei_printf("Частичное чтение I2S");
}
// масштабирование данных (иначе звук будет слишком тихим)
for (int x = 0; x < i2s_bytes_to_read / 2; x++) {
sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;
}
if (record_status) {
audio_inference_callback(i2s_bytes_to_read);
} else {
break;
}
}
}
vTaskDelete(NULL);
}
```
6. Копирование данных из переменной `sampleBuffer` в структуру данных `inference`, которая используется как входные параметры для функции классификации. Таким образом, код для подготовки аудиоданных завершен.
```cpp
static void audio_inference_callback(uint32_t n_bytes) {
for (int i = 0; i < n_bytes >> 1; i++) {
inference.buffer[inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
```
7. Далее рассмотрим конкретную классификацию.
```cpp
void loop() {
bool m = microphone_inference_record();
if (!m) {
ei_printf("Ошибка: Не удалось записать аудио...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("Ошибка: Не удалось запустить классификатор (%d)\n", r);
return;
}
}
```
```cpp
int pred_index = 0; // Инициализация pred_index
float pred_value = 0; // Инициализация pred_value
``` # вывод предсказаний
ei_printf("Предсказания ");
ei_printf("(DSP: %d мс., Классификация: %d мс., Аномалия: %d мс.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");} if (result.classification[ix].value > pred_value) {
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
# Отображение результата инференса
if (pred_index == 3) {
digitalWrite(LED_BUILT_IN, LOW); # Включение
} else {
digitalWrite(LED_BUILT_IN, HIGH); # Выключение
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
```
8. В основной цикл `loop` входит код, который выполняет классификацию полученных аудиоданных. Функция `microphone_audio_signal_get_data` получает ранее сохраненные аудиоданные, после чего вызывается функция `run_classifier(&signal, &result, debug_nn)`, которая вычисляет предсказания классификации. В процессе обучения модели, она обучается на данных с несколькими метками, и в результате `result` возвращает предсказания для каждого из этих меток.
9. Значение `result.classification[ix].value` предсказания, которое ближе к 1.0, соответствует текущему распознанному метке. Когда произносится обученная фраза-вызов, соответствующее значение предсказания также приближается к 1.0, что позволяет активировать систему.
10. Можно установить пороговое значение для сравнения с `result.classification[ix].value`, чтобы определить, был ли успешным вызов. Управление этим пороговым значением позволяет контролировать чувствительность распознавания. Таким образом, весь процесс активации завершен.### Получение access_token для доступа к API Baidu
При обращении к API для распознавания речи, синтеза речи и модели ERNIE от Baidu требуется предоставление access_token. В ESP32-S3 это достигается путем создания HTTP-запроса, построения запроса в соответствии с форматом API для получения access_token, отправки запроса через HTTP и получения ответа, из которого извлекается access_token.```cpp
// Получение access_token для API Baidu
String getAccessToken(const char* api_key, const char* secret_key) {
String access_token = "";
HTTPClient http;
``````markdown
## Создание HTTP-запроса
```http.begin("https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + String(api_key) + "&client_secret=" + String(secret_key));
int httpCode = http.POST("");
if (httpCode == HTTP_CODE_OK) {
String response = http.getString();
DynamicJsonDocument doc(1024);
deserializeJson(doc, response);
access_token = doc["access_token"].as<String>();
Serial.printf("[HTTP] GET access_token: %s\n", access_token);
} else {
Serial.printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());
}
http.end();
return access_token;
```
В этом коде создается HTTP-запрос для получения `access_token` с использованием ключей `api_key` и `secret_key`. Если запрос успешен, `access_token` извлекается из ответа и выводится в консоль. В случае неудачи выводится сообщение об ошибке.
## Обращение к API распознавания речи Baidu
После сбора аудиоданных с помощью ESP32-S3 и микрофона INMP441, необходимо отправить эти данные на сервер для их распознавания в текстовом формате. Для этого используется API распознавания речи от Baidu.
Основной код реализации представлен ниже:
```cpp
String baiduSTT_Send(String access_token, uint8_t* audioData, int audioDataSize) {
String recognizedText = "";
if (access_token == "") {
Serial.println("access_token is null");
return recognizedText;
}
// Аудиоданные необходимо закодировать в Base64, что увеличит объем данных на 1/3
int audio_data_len = audioDataSize * sizeof(char) * 1.4;
unsigned char* audioDataBase64 = (unsigned char*)ps_malloc(audio_data_len);
if (!audioDataBase64) {
Serial.println("Не удалось выделить память для audioDataBase64");
return recognizedText;
}
``````markdown
// Размер JSON-пакета, поскольку аудиоданные закодированы в Base64, объем данных увеличивается на 1/3
int data_json_len = audioDataSize * sizeof(char) * 1.4;
char* data_json = (char*)ps_malloc(data_json_len);
if (!data_json) {
Serial.println("Не удалось выделить память для data_json");
return recognizedText;
}
// Кодирование аудиоданных в Base64
encode_base64(audioData, audioDataSize, audioDataBase64);
memset(data_json, '\0', data_json_len);
strcat(data_json, "{");
strcat(data_json, "\"format\":\"pcm\",");
strcat(data_json, "\"rate\":16000,");
strcat(data_json, "\"dev_pid\":1537,");
strcat(data_json, "\"channel\":1,");
strcat(data_json, "\"cuid\":\"57722200\",");
strcat(data_json, "\"token\":\"");
strcat(data_json, access_token.c_str());
strcat(data_json, "\",");
sprintf(data_json + strlen(data_json), "\"len\":%d,", audioDataSize);
strcat(data_json, "\"speech\":\"");
strcat(data_json, (const char*)audioDataBase64);
strcat(data_json, "\"");
strcat(data_json, "}");
// Создаем HTTP-запрос
HTTPClient http_client;
http_client.begin("http://vop.baidu.com/server_api");
http_client.addHeader("Content-Type", "application/json");
int httpCode = http_client.POST(data_json);
if (httpCode > 0) {
if (httpCode == HTTP_CODE_OK) {
// Получаем ответ
String response = http_client.getString();
Serial.println(response);
// Извлекаем соответствующий result из JSON
DynamicJsonDocument responseDoc(2048);
deserializeJson(responseDoc, response);
recognizedText = responseDoc["result"].as<String>();
}
} else {
Serial.printf("[HTTP] POST failed, error: %s\n", http_client.errorToString(httpCode).c_str());
}
// Освобождаем память
if (audioDataBase64) {
free(audioDataBase64);
}
if (data_json) {
free(data_json);
}
http_client.end();
return recognizedText;
}
```
Вот анализ ключевых моментов кода:
```markdown
- **Расчет размера JSON-пакета**: Размер JSON-пакета рассчитывается с учетом увеличения объема данных на 1/3 из-за кодирования в Base64.
- **Выделение памяти**: Память выделяется для JSON-пакета с использованием функции `ps_malloc`. Если память не может быть выделена, выводится сообщение об ошибке, и возвращается `recognizedText`.
- **Кодирование аудиоданных**: Аудиоданные кодируются в Base64 с помощью функции `encode_base64`.
- **Формирование JSON-пакета**: JSON-пакет формируется с использованием функций `strcat` и `sprintf`. В него включаются параметры формата, скорости, устройства, уникального идентификатора, токена доступа, размера данных и закодированных аудиоданных.
- **Создание HTTP-запроса**: HTTP-запрос создается с использованием библиотеки `HTTPClient`. Запрос отправляется на сервер `http://vop.baidu.com/server_api` с заголовком `Content-Type: application/json`.
- **Обработка ответа**: Если запрос успешно выполнен (код ответа `HTTP_CODE_OK`), ответ извлекается из JSON-документа, и результат сохраняется в переменной `recognizedText`.
- **Обработка ошибок**: Если запрос не выполнен успешно, выводится сообщение об ошибке.
- **Освобождение памяти**: После выполнения запроса, память, выделенная для JSON-пакета и закодированных аудиоданных, освобождается с помощью функции `free`.
```1. В этом месте создается буфер для JSON-пакета, который должен быть примерно в 1,4 раза больше исходных данных, так как данные будут закодированы в Base64. В данном случае выделяется достаточно большое количество памяти, поэтому она должна быть выделена из PSRAM.```cpp
// Аудио-данные будут закодированы в Base64, что увеличит объем данных примерно на 1/3
int audio_data_len = audioDataSize * sizeof(char) * 1.4;
unsigned char* audioDataBase64 = (unsigned char*)ps_malloc(audio_data_len);
if (!audioDataBase64) {
Serial.println("Не удалось выделить память для audioDataBase64");
return recognizedText;
}
// Размер JSON-пакета, учитывая, что аудио-данные будут закодированы в Base64, что увеличит объем данных примерно на 1/3
int data_json_len = audioDataSize * sizeof(char) * 1.4;
char* data_json = (char*)ps_malloc(data_json_len);
if (!data_json) {
Serial.println("Не удалось выделить память для data_json");
return recognizedText;
}
```
2. В этом месте данные аудио-данных упаковываются в формат, соответствующий документации API. Важно отметить, что `len` представляет собой размер исходных данных, а не размер данных после кодирования в Base64.
```cpp
// Кодируем аудио-данные в Base64
encode_base64(audioData, audioDataSize, audioDataBase64);
```
```cpp
memset(data_json, '\0', data_json_len);
strcat(data_json, "{");
strcat(data_json, "\"format\":\"pcm\",");
strcat(data_json, "\"rate\":16000,");
strcat(data_json, "\"dev_pid\":1537,");
strcat(data_json, "\"channel\":1,");
strcat(data_json, "\"cuid\":\"57722200\",");
strcat(data_json, "\"token\":\"");
strcat(data_json, access_token.c_str());
strcat(data_json, "\",");
sprintf(data_json + strlen(data_json), "\"len\":%d,", audioDataSize);
strcat(data_json, "\"speech\":\"");
strcat(data_json, (const char*)audioDataBase64);
strcat(data_json, "\"");
strcat(data_json, "}");
```
3. Здесь, JSON-документ с ответными данными должен быть достаточно большим, чтобы вместить размер возвращаемых данных.
```cpp
// Парсинг соответствующего результата из JSON
DynamicJsonDocument responseDoc(2048);
deserializeJson(responseDoc, response);
recognizedText = responseDoc["result"].as<String>();
```### Определение роли API для агента Бaidu
Результат распознавания голоса возвращается в формате текста, который затем можно использовать как входные данные для API агента большого моделирования Бaidu. Реализация вызова API большого моделирования представлена ниже:
```cpp
// Получение идентификатора разговора API Baidu
String getConversation_id(const char* api_key, const char* app_id) {
String conversation_id = "";
// Создание HTTP-запроса
HTTPClient http;
http.begin("https://qianfan.baidubce.com/v2/app/conversation");
http.addHeader("Content-Type", "application/json");
http.addHeader("X-Appbuilder-Authorization", "Bearer " + String(api_key));
// Создание JSON-документа
DynamicJsonDocument requestJson(1024);
requestJson["app_id"] = app_id;
// Сериализация JSON-данных в строку
String requestBody;
serializeJson(requestJson, requestBody);
// Отправка HTTP-запроса
int httpCode = http.POST(requestBody);
if (httpCode == HTTP_CODE_OK) {
String response = http.getString();
DynamicJsonDocument doc( Yöntem: JSON, емкость: 1024 );
deserializeJson(doc, response);
conversation_id = doc["conversation_id"].as<String>();
ei_printf("[HTTP] GET conversation_id: %s\n", conversation_id.c_str());
} else {
ei_printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());
}
http.end();
return conversation_id;
}
```
### Вызов API синтеза речи Бaidu
Для воспроизведения текстовых данных, полученных от API Baidu, необходимо преобразовать их в аудио-данные. Это достигается путем вызова API синтеза речи Baidu. Реализация представлена ниже:
```cpp
void baiduTTS_Send(String access_token, String text) {
if (access_token == "") {
Serial.println("access_token is null");
return;
}
if (text.length() == 0) {
Serial.println("text is null");
return;
}
``` const int per = 1;
const int spd = 5;
const int pit = 5;
const int vol = 10;
const int aue = 6;
// URL-кодирование текста
String encodedText = urlEncode(urlEncode(text));
// URL HTTP-запрос данных
String url = "https://tsn.baidu.com/text2audio";
const char* header[] = { "Content-Type", "Content-Length" };
url += "?tok=" + access_token;
url += "&tex=" + encodedText;
url += "&per=" + String(per);
url += "&spd=" + String(spd);
url += "&pit=" + String(pit);
url += "&vol=" + String(vol);
url += "&aue=" + String(aue);
url += "&cuid=esp32s3";
url += "&lan=zh";
url += "&ctp=1";
// Создание HTTP-запроса
HTTPClient http;
http.begin(url);
http.collectHeaders(header, 2);
// Выполнение HTTP-запроса
int httpResponseCode = http.GET();
if (httpResponseCode > 0) {
if (httpResponseCode == HTTP_CODE_OK) {
String contentType = http.header("Content-Type");
Serial.println(contentType);
if (contentType.startsWith("audio")) {
Serial.println("Синтезирование успешно");
// Получение возвращенного аудиоданных
Stream* stream = http.getStreamPtr();
uint8_t buffer[512];
size_t bytesRead = 0;
// Установка timeout в 200ms для предотвращения появления шума в конце
stream->setTimeout(200);
while (http.connected() && (bytesRead = stream->readBytes(buffer, sizeof(buffer))) > 0) {
// Воспроизведение аудио
playAudio(buffer, bytesRead);
delay(1);
}
// Очистка буфера I2S DMA
clearAudio();
} else if (contentType.equals("application/json")) {
Serial.println("Ошибка синтезирования");
} else {
Serial.println("Неизвестный Content-Type");
}
} else {
Serial.println("Не удалось получить аудиофайл");
}
} else {
Serial.print("Код ошибки: ");
Serial.println(httpResponseCode);
}
http.end();
}// Воспроизведение аудио данных с помощью MAX98357A
void playAudio(uint8_t* audioData, size_t audioDataSize) {
if (audioDataSize > 0) {
// Передача данных
size_t bytes_written = 0;
i2s_write(I2S_OUT_PORT, (int16_t*)audioData, audioDataSize, &bytes_written, portMAX_DELAY);
}
}```cpp
void clearAudio(void) {
// Очистка буфера I2S DMA
i2s_zero_dma_buffer(I2S_OUT_PORT);
Serial.print("Очистка буфера");
}
// Упаковка URL для HTTP-запроса
String url = "https://tsn.baidu.com/text2audio";
const char* header[] = { "Content-Type", "Content-Length" };
url += "?tok=" + access_token;
url += "&tex=" + encodedText;
url += "&per=" + String(per);
url += "&spd=" + String(spd);
url += "&pit=" + String(pit);
url += "&vol=" + String(vol);
url += "&aue=" + String(aue);
url += "&cuid=esp32s3";
url += "&lan=zh";
url += "&ctp=1";
// Создание HTTP-запроса
HTTPClient http;
http.begin(url);
http.collectHeaders(header, 2);
// Установка времени ожидания в 200 миллисекунд, чтобы избежать появления шумов
stream->setTimeout(200);
// Здесь происходит получение HTTP-аудиопотока. В цикле while необходимо добавить задержку, чтобы не заблокировать систему. Если этого не сделать, другие задачи, такие как запись аудио или активация, не смогут выполняться, что приведет к невозможности активации во время воспроизведения аудио. Поэтому здесь добавляется обработка для освобождения процессора.
while (http.connected() && (bytesRead = stream->readBytes(buffer, sizeof(buffer))) > 0) {
// Воспроизведение аудио
playAudio(buffer, bytesRead);
delay(1);
}
```5. Это очистка буфера DMA I2S, чтобы избавиться от шумов.
```cpp
void clearAudio(void) {
// Очистка буфера DMA I2S
i2s_zero_dma_buffer(I2S_OUT_PORT);
Serial.print("clearAudio");
}
```
# Обучение собственного слова активации (продвинутое)
## Запись аудио
### Подготовка оборудования
Необходимо подготовить следующее оборудование:
+ Комплект AI
+ microSD-карта (не более 32 ГБ)
+ microSD-читатель карт
### Форматирование microSD-карты
1. Вставьте microSD-карту в читатель карт и подключите его к компьютеру. Форматируйте microSD-карту **<font style="color:#DF2A3F;">в формат FAT32</font>**. Пример:

2. После форматирования вставьте microSD-карту в слот комплекта AI.
### Начало записи аудио
Мы записываем аудио данные, загружая программу записи аудио на ESP32-S3. Записанные аудио данные сохраняются на microSD-карте, а затем их можно прочитать с помощью компьютера.
#### Запись аудио-регистрационного ПО на ESP32-S3
Проект аудио-регистрационного ПО расположен в **<font style="color:#DF2A3F;">esp32s3-ai-chat/example/capture_audio_data</font>**. Откройте проект и перед компиляцией включите **<font style="color:#DF2A3F;">поддержку PSRAM</font>**, как показано на следующем рисунке. После настройки скомпилируйте и загрузите проект на ESP32-S3.

#### Метка отправки по последовательному порту для записи аудио
1. После запуска программы, нормальный лог последовательного порта выглядит следующим образом.
2. После успешного запуска программы, можно открыть утилиту для работы с последовательным портом и отправить соответствующие команды управления для записи аудио. Отправьте метку "**hgx**".

3. Отправьте команду записи "**rec**", чтобы начать запись.

4. После отправки метки (например, "**hgx**"), программа будет ждать команду "**rec**". При каждом отправлении команды "**rec**", программа начнет запись нового образца (запись продолжается в течение 10 секунд и автоматически завершается), файлы будут сохранены как hgx.1.wav, hgx.2.wav, hgx.3.wav и т.д.
5. Программа начнет запись нового образца метки, когда будет отправлена новая метка (например, "**noise**"). При каждом отправлении команды "**rec**" для нового образца метки, программа начнет запись и сохранит её как noise.1.wav, noise.2.wav, noise.3.wav и т.д.
6. В конечном итоге, все записанные образцы меток будут сохранены на SD-карте, и их можно будет прочитать через картридер на компьютере. Пример:
#### Методы записи аудио для различных меток
Необходимо записать как минимум **<font style="color:#DF2A3F;">3 метки</font>** образцов данных: образцы данных для меток пробуждения, шума и неизвестных меток. Каждый образец данных для меток должен быть записан как минимум в **<font style="color:#DF2A3F;">10 группах</font>**. Чем больше данных, тем лучше будет распознавание модели после обучения.1. Образцы данных для меток пробуждения: в течение 10 секунд повторно произносите слово "пробуждение" в микрофон, меняя скорость и тон голоса. Чем больше различных образцов, тем лучше будет обобщенное распознавание.
2. Образцы данных для меток шума: просто записывайте окружающий шум, не произнося слова в микрофон.
3. Образцы данных для меток неизвестных: в течение 10 секунд произносите в микрофон любые слова, кроме слов "пробуждение".
## Обучение записанных аудиоданных
### Создание проекта на Edge Impulse
Войдите на Edge Impulse, [https://edgeimpulse.com/](https://edgeimpulse.com/), зарегистрируйтесь и создайте проект.

### Загрузка записанных аудиоданных
После создания проекта выберите инструмент "Загрузить существующие данные" в разделе Data Acquisition. Выберите файлы для загрузки.

После завершения загрузки данных система автоматически разделит их на обучающую (Training) и тестовую (Test) выборки (в соотношении 80% и 20%).
### Разделение данных
Для обучения системы требуется, чтобы все данные имели длину 1 секунду. Однако, в предыдущем разделе были загружены записи длиной 10 секунд, которые необходимо разбить на отдельные 1-секундные фрагменты. Поэтому необходимо выполнить операцию разделения каждого образца данных.1. Нажмите на три точки рядом с названием образца и выберите **Разделить образец**.

2. После входа в этот инструмент данные будут разделены на 1-секундные фрагменты. Каждый прямоугольный блок представляет собой один из разделенных фрагментов. Если необходимо, можно переместить прямоугольник, чтобы он полностью покрывал зону с голосом, или добавить или удалить фрагменты.

3. Обрезанные аудиоданные выглядят следующим образом:

4. Все образцы данных должны быть разделены до тех пор, пока все образцы данных (обучающие, тестовые) не будут иметь длину 1 секунду.
### Создание импульсного сигнала (предварительная обработка/определение модели)
Создайте импульсный сигнал, выполните предварительную обработку данных и выберите модель, как показано на следующем рисунке:

Шаги выполнения:
1. Нажмите на **Create impulse** слева, затем нажмите **Add a processing block** и добавьте **Audio(MFCC)**. Используйте MFCC, который извлекает характеристики из аудиосигнала с помощью мел-частотных обертона, что очень полезно для человеческого голоса.

2. Затем нажмите **Add a learning block** и добавьте **Classification** модуль. Этот модуль строит нашу модель с нуля, используя сверточную нейронную сеть для классификации изображений.
3. Наконец, нажмите **Save impulse**, чтобы сохранить конфигурацию.
### Предварительная обработка (MFCC)
Следующим шагом является создание изображений для обучения на следующем этапе.
1. Нажмите на **MFCC**, вы можете оставить параметры по умолчанию и нажать на **Save parameters**.

2. Нажмите на **Generate features**, чтобы сгенерировать характеристики для трех меток данных.

### Проектирование и обучение модели (Classifier)
Далее нам нужно спроектировать структуру модели и начать обучение, следуя следующим шагам:
1. Нажмите на **Classifier** слева, структура модели уже настроена, затем нажмите на **Save & Train**, чтобы начать обучение модели.

2. После завершения обучения, вы увидите результаты классификации, как показано на рисунке выше.

### Тестирование модели
После обучения модели, вы можете протестировать её точность на тестовом наборе данных.
1. Нажмите на **Model testing** слева, затем нажмите на **Classify all**, чтобы начать классификацию всех тестовых данных.
2. Подождите немного, результаты классификации всех тестовых данных будут вычислены, как показано на рисунке выше. На основе этих результатов можно сделать вывод о том, удовлетворяет ли точность распознавания модели требованиям.
## Развертывание модели на ESP32-S3
### Генерация библиотеки модели
После обучения модели нам нужно сгенерировать библиотеку для работы на платформе Arduino ESP32.
1. Перед генерацией библиотеки, настройте вашу платформу, нажав на **Target** справа, выберите **Target device** как **ESP-EYE**, затем нажмите на **Save**.

2. Нажмите на **Deployment** слева, настройте параметры, как показано на рисунке выше, затем нажмите на **Build**, чтобы начать генерацию библиотеки.

3. После завершения генерации, сохраните библиотеку .zip в вашем каталоге проекта.

### Тестирование модели активации на ESP32-S3
После обучения библиотеки активации, вам нужно протестировать ее на ESP32-S3. Откройте каталог проекта и **<font style="color:#DF2A3F;">esp32s3-ai-chat/example/wake_detect</font>** проект для тестирования функции пробуждения.
1. Выберите проект, импортируйте библиотеку, добавьте ZIP-файл библиотеки, выберите обученную нами библиотеку пробуждения.

2. После успешного импорта нам нужно будет сослаться на этот файл библиотеки, поэтому снова выберите проект, импортируйте библиотеку и выберите только что импортированный файл библиотеки.
3. После импорта заголовочный файл будет включен, и наш собственный обученный файл модели пробуждения будет успешно импортирован.

4. Скомпилируйте проект, загрузите программу на разработочный модуль ESP32-S3. После запуска программы она будет в реальном времени отслеживать пробуждающие слова и давать предсказания по трём меткам, которые были обучены ранее. Чем ближе значение предсказания к 1.0, тем более надёжным является результат.

5. Когда я произношу "houguoxiong", значение предсказания метки "hgx" стремится к 1.0, что подтверждает успешное пробуждение.

### Замена модели пробуждения
Когда в проекте Arduino требуется заменить новую модель пробуждения, можно удалить предыдущую библиотеку модели, удалить заголовочные файлы, которые были ранее импортированы, и затем повторить процедуру импорта модели и её использования, описанную в разделе **7.3.2**.

Удаление библиотеки происходит путём удаления папки библиотеки в соответствующем каталоге, после чего закройте программу Arduino и снова откройте проект Arduino.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )