Слияние кода завершено, страница обновится автоматически
NEOCrawler (русское название: НейоКраулер) — это система пауков, реализованная с использованием Node.js, Redis и PhantomJS. Код полностью открытый и предназначен для сбора данных в вертикальных областях и последующей доработки.### [Основные характеристики]
Общая архитектура
 На этом рисунке желтым цветом показаны различные подсистемы системы пауков. SuperScheduler — центральный распорядчик, который помещает собранные веб-сайты в соответствующие базы данных сайтов. SuperScheduler извлекает соответствующее количество сайтов из различных баз данных сайтов согласно правилам распределения и помещает их в очередь для парсинга.
На этом рисунке желтым цветом показаны различные подсистемы системы пауков. SuperScheduler — центральный распорядчик, который помещает собранные веб-сайты в соответствующие базы данных сайтов. SuperScheduler извлекает соответствующее количество сайтов из различных баз данных сайтов согласно правилам распределения и помещает их в очередь для парсинга.
Spider — это распределенная программа-паук, которая извлекает задачи из очереди для парсинга, подготовленной распорядчиком, выполняет парсинг, помещает найденные сайты в базу данных сайтов, а также сохраняет извлеченные данные. Программу-паука можно разделить на ядро (core) и четыре промежуточных компонента (download, extract, pipeline), чтобы было легче переопределить отдельные функции в экземплярах пауков.
ProxyRouter — это маршрутизатор, который умело направляет запросы пауков к доступным прокси-серверам при использовании прокси-IP адресов. * Webconfig — это конфигурационный интерфейс для настроек пауков web.
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>'data',VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>'binary',VERSIONS=>3}
./hbase-daemon.sh start rest
instance, скопируйте example и переименуйте её в abc. Далее все примеры будут использовать имя abc.instance/abc/settings.json
{
/* Обратите внимание: здесь представлены объяснения для каждого параметра, реальное settings.json не должно содержать комментарии */
"driller_info_redis_db": ["127.0.0.1", 6379, 0], /* Расположение информации о правилах сайта, последнее число указывает номер базы данных Redis */
"url_info_redis_db": ["127.0.0.1", 6379, 1], /* Расположение информации о сайте */
"url_report_redis_db": ["127.0.0.1", 6379,```
```markdown
## [Запуск]
* Основные шаги запуска пауков:
+ Конфигурирование правил сбора в веб-интерфейсе
+ Отладка отдельной страницы для проверки корректности сбора данных
+ Запуск планировщика (необходимо запустить один экземпляр)
+ При использовании прокси-IP для сбора данных следует запустить маршрутизацию прокси
+ Запуск пауков (пауки могут быть запущены распределённо)
Следующие команды показывают конкретные способы запуска.
* Запуск конфигурации веб-интерфейса (правила конфигурации см. в следующей главе):
> node run.js -i abc -a config -p 8888
Откройте браузер и перейдите по адресу **http://localhost:8888**, чтобы настроить правила сбора данных через веб-интерфейс
* Тестирование отдельной страницы:
> node run.js -i abc -a test -l "http://domain/page/"
```* Запуск планировщика:
> node run.js -i abc -a schedule
-i указывает имя экземпляра, а -a указывает действие планировщика; аналогично ниже
node run.js -i abc -a proxy -p 2013 Здесь, -p указывает порт прокси-роутера. При запуске на локальной машине, в файле setting.json должны быть установлены значения proxy_router и port как 127.0.0.1:2013
node run.js -i abc -a crawl Вы можете просмотреть выходные отладочные журналы в
instance/example/logs/debug-result.jsonРекомендуется использовать Node.js' PM2 или Python's Supervisor для управления процессами в рабочей среде.
Откройте веб-интерфейс, например, http://localhost:8888/, перейдите в раздел "Rules for Drilling", добавьте правила. Это JSON-редактор, который позволяет переключаться между режимом кода и визуальным режимом. Ниже представлены объяснения конфигурационных опций. Для конкретной конфигурации приложений обратитесь к примерам в следующем разделе.```javascript { /* Примечание: Ниже приведено объяснение каждого параметра конфигурации. Реальная конфигурация не может содержать комментарии / "domain": "", / Верхнеуровневый домен, например, 163.com (без имени хоста, www.163.com неверно) / "url_pattern": "", / Шаблон URL, регулярное выражение, например, ^http://domain/\d+.html. Чем более точные ограничения, тем лучше / "alias": "", / Альтернативное имя для этого правила / "id_parameter": [], / Допустимые параметры для данного URL. Если первое значение равно "#", то все параметры будут отфильтрованы / "encoding": "auto", / Кодировка страницы, "auto" означает автоматическое определение. Можно указывать значения, такие как gbk, utf-8 / "type": "node", / Тип страницы, ветка или узел / "save_page": true, / Сохранять ли HTML исходный код / "format": "html", / Формат страницы, html/json/binary / "jshandle": false, / Обрабатывать ли JavaScript, определяет, будет ли паук использовать PhantomJS для загрузки страниц / "extract_rule": { / Правила извлечения, подробно объясняются позже / "category": "crawled", "rule": { / Должно быть пустым, если данные не извлекаются / "title": { / Единица извлечения, подробно объясняется позже / "base": "content", "mode": "css", "expression": "title", "pick": "text", "index": 1 } } }, "cookie": [], / Значения cookies, составленные из нескольких объектов, каждый объект представляет одно значение cookie / "inject_jquery": false, / Внедрять ли jQuery при использовании PhantomJS / "load_img": false, / Загружать ли изображения при использовании PhantomJS / "drill_rules": ["a"], / Интересные ссылки внутри страницы, заполнены CSS селекторами для выбора элементов , можно включать несколько, здесь представляют все ссылки */ }
### Выборочные единицы
```javascript
{
"base": "content", /* Основание для выборки, DOM веб-страницы: content или url */
"mode": "css", /* Режим выборки, css или regex указывает на CSS селектор или регулярное выражение, value указывает на фиксированное значение */
"expression": "title", /* Выражение, соответствует mode: CSS селектор или регулярное выражение или фиксированное значение */
}
``````markdown
### Параметры выборки
```json
{
"pick": "text", /* В CSS режиме выбирается атрибут или значение элемента; `text` или `html` указывают на текстовое значение или HTML код соответственно, `@href` указывает на значение атрибута `href`, остальные атрибуты указываются аналогично с добавлением символа `@` перед названием атрибута */
"index": 1 /* При наличии нескольких элементов, выбирается n-ый элемент; `-1` указывает на выбор всех элементов, что вернет массив значений */
}
/* Правила выборки состоят из множества выборочных единиц, их базовая структура представлена ниже */
{
"extract_rule": {
"category": "crawled", /* Название таблицы HBase, куда будет сохраняться этот узел */
"rule": { /* Конкретные правила */
"title": { /* Выборочная единица, правила см. выше */
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1,
"subset": { /* Подмножество */
"category": "comment", /* Категория `comment` (сохраняется в `comment`) */
"relate": "#title#", /* Соответствие с родительским узлом */
"mapping": false, /* Тип подмножества, если `mapping=true`, то данные будут храниться отдельно в другой таблице */
"rule": {
``````markdown
"profile": {"base":"content","mode":"css","expression":".classname","pick":"@href","index":1},/*Извлечение единицы*/
"message": {"base":"content","mode":"css","expression":".classname","pick":"@alt","index":1}
},
"require":["profile"]/*Необходимое поле*/
}
}
}
"require":["title"]/*Необходимое поле. Если значение внутри поля является массивом, то это означает, что любое одно из значений в этом массиве удовлетворяет требование, например [[a,b],c]*/
}
Этот шаг предполагает, что вы уже запустили веб-конфигурацию в фоновом режиме. Для запуска веб-конфигурации следуйте инструкциям из предыдущего раздела. Ниже приведён пример конфигурации для извлечения WeChat ID. Предположим, что наша цель — извлечение всех WeChat ID c http://www.sovxin.com.
Мы создаем правила извлечения согласно этим уровням страниц, где только на детальной странице требуется извлечение информации, а остальные три страницы используются для последовательного открытия детальной страницы.
Мы начинаем с конца, с детальной страницы, и затем переходим к главной странице.
## Скриншот правил (на вашем интерфейсе таких списков пока нет, нажмите Add для добавления правил, используйте мою конфигурацию ниже)

## Детальная страница (извлечение фактического содержимого)
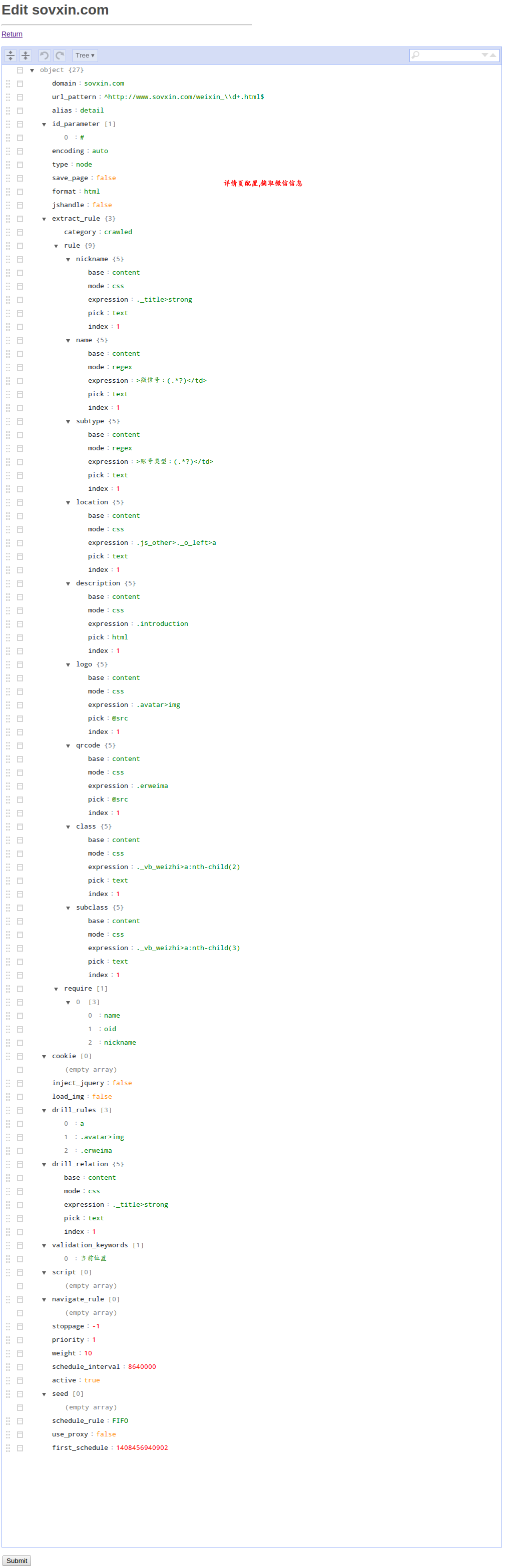Вы должны сравнить этот пример со всеми объяснениями каждого параметра конфигурации из предыдущего раздела.
Вы можете переключиться в режим редактирования кода и вставить следующий JSON.
```json
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/weixin_\\d+.html$",
"alias": "detail",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "node",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {
"nickname": {
"base": "content",
"mode": "css",
"expression": ".title>strong",
"pick": "text",
"index": 1
},
"name": {
"base": "content",
"mode": "regex",
"expression": ">微信号:(.*)</td>",
"pick": "text",
"index": 1
},
"subtype": {
"base": "content",
"mode": "regex",
"expression": ">账号类型:(.*)</td>",
"pick": "text",
"index": 1
}
}
}
}

{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/t_.+?.html$",
"alias": "list",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "branch",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
}
 ```javascript
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/fenlei_.+\\.html$",
"alias": "категория",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "ветвь",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [
"当前位置"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 2,
"weight": 10,
"schedule_interval": 86400,
"active": true,
"seed": [
"http://www.sovxin.com/fenlei_zixun.html"
],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1414938594585
}
```javascript
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/fenlei_.+\\.html$",
"alias": "категория",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "ветвь",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [
"当前位置"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 2,
"weight": 10,
"schedule_interval": 86400,
"active": true,
"seed": [
"http://www.sovxin.com/fenlei_zixun.html"
],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1414938594585
}

```javascript
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/$",
"alias": "home",
}
## Продвинутый пример
### Кастомизация хранения данных
По умолчанию данные, полученные при парсинге, хранятся в HBase. Вы можете отключить это поведение по умолчанию и хранить данные в других типах баз данных. Для этого измените `instance/ваш_экземпляр/settings.json`, установив значение `save_content_to_hbase` в `false`. Затем измените `instance/ваш_экземпляр/spider_extend.js`, где вы сможете реализовать свои кастомизации. Удалите комментарий метода `pipeline`, который будет вызван после завершения парсинга страницы. Этот метод принимает два аргумента: `extracted_info` — структурированные данные, и `callback` — обратный вызов, требующий выполнения ваших действий (например, записи данных в вашей базе данных).
Пример кода (хранение данных в MongoDB) приведён ниже для справки:
``````javascript
/**
* Вместо основной конвейерной логики фреймворка
* если этот метод ничего не делает, закомментируйте его
* @param extracted_info (тот же, что и в процессе извлечения)
*/
spider_extend.prototype.pipeline = function(extracted_info, callback) {
var spider_extend = this;
if (!extracted_info['extracted_data'] || isEmpty(extracted_info['extracted_data'])) {
logger.warn('Данные ' + extracted_info['url'] + ' пусты.');
callback();
} else {
var data = extracted_info['extracted_data'];
if (data['article'] && data['article'].trim() !== '') {
var _id = crypto.createHash('md5').update(extracted_info['url']).digest('hex');
var pureContent = data['article'].replace(/[^\u4e00-\u9fa5a-z0-9]/ig, '');
var simplefp = crypto.createHash('md5').update(pureContent).digest('hex');
var currentTime = new Date();
currentTime.getTime();
data['обновлено'] = currentTime;
data['опубликовано'] = false;
``````markdown
// удаление дополнительной информации
if (data['$category']) delete data['$category'];
if (data['$require']) delete data['$require'];
// форматирование отношения в массив
if (выtracted_info['drill_relation']) {
data['отношение'] = выtracted_info['drill_relation'].split('->');
}
// получение домена
var urlibarr = выtracted_info['origin']['urllib'].split(':');
var домен = urlibarr[urlibarr.length - 2];
data['домен'] = домен;
logger.debug('получено ' + data['название'] + ' с ' + домен + '(' + выtracted_info['url'] + ')');
data['url'] = выtracted_info['url'];
var запрос = {
"$or": [
{
'_id': _id
},
{
'simplefp': simplefp
}
]
};
spider_extend.mongoTable.findOne(запрос, function (err, элемент) {
if (err) {
throw err;
callback();
} else {
if (элемент) {
// если новое значение поля меньше старого, удалить его
(function (nlist) {
for (var c = 0; c < nlist.length; c++) {
if (data[nlist[c]] && элемент[nlist[c]] && data[nlist[c]].length < элемент[nlist[c]].length)
delete data[nlist[c]];
}
})(['название', 'статья', 'теги', 'ключевые слова']);
spider_extend.mongoTable.update({'_id': элемент['_id']}, {$set: data}, {w: 1}, function (err, результат) {
if (!err) {
spider_extend.reportdb.rpush('очередь:обработано', _id);
logger.debug('обновление ' + data['название'] + ' в mongodb, ' + data['url'] + ' --перезапись-> ' + элемент['url']);
}
callback();
});
} else {
data['simplefp'] = simplefp;
data['_id'] = _id;
data['создано'] = текущее_время;
spider_extend.mongoTable.insert(data, {w: 1}, function (err, результат) {
if (!err){
```
Перевод:
```markdown
// удаление дополнительной информации
if (data['$category']) delete data['$category'];
if (data['$require']) delete data['$require'];
// форматирование отношения в массив
if (выtracted_info['drill_relation']) {
data['relation'] = выtracted_info['drill_relation'].split('->');
}
// получение домена
var urlibarr = выtracted_info['origin']['urllib'].split(':');
var domain = urlibarr[urlibarr.length - 2];
data['domain'] = domain;
logger.debug('received ' + data['name'] + ' from ' + domain + '(' + выtracted_info['url'] + ')');
data['url'] = выtracted_info['url'];
var query = {
"$or": [
{
'_id': _id
},
{
'simplefp': simplefp
}
]
};
spider_extend.mongoTable.findOne(query, function (err, element) {
if (err) {
throw err;
callback();
} else {
if (element) {
// если новое значение поля меньше старого, удалить его
(function (nlist) {
for (var c = 0; c < nlist.length; c++) {
if (data[nlist[c]] && element[nlist[c]] && data[nlist[c]].length < element[nlist[c]].length)
delete data[nlist[c]];
}
})(['name', 'article', 'tags', 'keywords']);
spider_extend.mongoTable.update({'_id': element['_id']}, {$set: data}, {w: 1}, function (err, result) {
if (!err) {
spider_extend.reportdb.rpush('queue:processed', _id);
logger.debug('updated ' + data['name'] + ' in mongodb, ' + data['url'] + ' --overwrite-> ' + element['url']);
}
callback();
});
} else {
data['simplefp'] = simplefp;
data['_id'] = _id;
data['created'] = current_time;
spider_extend.mongoTable.insert(data, {w: 1}, function (err, result) {
if (!err){
```## Настройка параллельной обработки данных пауками
Для изменения количества параллельных запросов, выполняемых пауками, отредактируйте файл `instance/ваш_экземпляр/settings.json` и установите значение параметра `SPIDER_CONCURRENCY`. Обратите внимание: этот параметр настраивает количество параллельных запросов, выполнение которых осуществляется пауками. Частота повторного захвата содержимого для каждого типа страниц устанавливается в интерфейсе конфигурирования правил.
## Кастомизация процесса извлечения ссылок и контентаИногда правила, установленные через веб-интерфейс, недостаточно для удовлетворения специфических требований к захвату данных. Например, после того как страница была захвачена, вам может потребоваться отправить AJAX-подзапрос для объединения данных. Либо вы можете предпочесть использовать свои методы для извлечения ссылок и контента. Удалите метод `extract` в файле `instance/ваш_экземпляр/spider_extend.js`, так как он будет вызван пауком после завершения извлечения данных. Этот метод принимает два аргумента: `extracted_info`, содержащий информацию о захваченном содержимом, и `callback`, который требуется вызвать после выполнения ваших действий.## 5. Данные Redis/ssdb
Понимание данных поможет вам лучше понять всю систему и проводить дальнейшие доработки. Neocrawler использует четыре хранилища: driller_info_redis_db, url_info_redis_db, url_report_redis_db, proxy_info_redis_db. Настройки можно найти в settings проекта.
```javascript
/**
* @param {Object} extracted_info - информация, извлеченная из страницы
* @param {Function} callback - обратный вызов с результатами
*/
spider_extend.prototype.extract = function(extracted_info, callback) {
var self = this;
var domain = __getTopLevelDomain(extracted_info['url']);
var result = extracted_info;
``` switch (domain) {
case 'sino-manager.com':
if (result['origin'].urllib === 'urllib:driller:sino-manager.com:sinolist') {
for (var i = 0; i < result['drill_link']['urllib:driller:sino-manager.com:sinolist'].length; i++) {
result['drill_link']['urllib:driller:sino-manager.com:sinolist'][i] = result['drill_link']['urllib:driller:sino-manager.com:sinolist'][i].replace(/(.{31})/, "$1s");
}
break;
} else {
break;
}
case 'chinaventure.com.cn':
if (result['origin'].urllib === 'urllib:driller:chinaventure.com.cn:chinaventurelist') {
var content = JSON.parse(result['content'].substring(1, result['content'].length - 1));
var news_url = '';
var detail = [];
var list = [];
var pages;
for (var i = 0; i < content.length; i++) {
detail.push(content[i].news_url);
}
result['drill_link']['urllib:driller:chinaventure.com.cn:chinaventuredetail'] = detail;
var expression = new RegExp('^.*pages=([0-9]+).*$', 'ig');
var matched = expression.exec(result['url']);
if (matched) {
pages = parseInt(matched[1]) + 1;
result['url'] = result['url'].replace('pages=' + matched[1], 'pages=' + pages);
} else {
}
logger.debug(result['url']);
list.push(result['url']);
result['drill_link']['urllib:driller:chinaventure.com.cn:chinaventurelist'] = list;
break;
} else {
break;
}
default:;
} return callback(result);
}
```JSON конфигурация, использует четыре различных категории хранения с одним и тем же ключом, который не вызывает конфликтов. Можно указывать все четыре пространства в одной базе данных Redis/SSDB, при этом каждое пространство может иметь различный темп роста. При использовании Redis рекомендуется направлять каждый тип пространства в отдельное базовое пространство (db). В идеальном случае каждому пространству следует выделить отдельную базу данных Redis.```Далее приведены описания четырёх пространств:
## driller_info_redis_dbСодержит правила сбора и адреса сайтов.
* `driller:{domain}:{alias}`
Пример: `driller:163.com:newslist`. Квадратные скобки обозначают переменные, аналогично далее. Хэш-тип, содержащий правила сбора, которые были настроены через веб-интерфейс.
* `urllib:driller:{domain}:{alias}`
Пример: `urllib:driller:163.com:newslist`. Списковый тип, содержащий очередь адресов сайта, соответствующих определённым правилам. Когда паук обнаруживает адрес, соответствующий правилам сбора, он помещает его в соответствующую очередь. Диспетчер извлекает адреса из этих очередей для распределения задач, а паук выполняет сбор информации согласно распределённой очереди. Процесс повторяется циклически.
* `queue:scheduled:all`
Очередь для планирования сбора, списковый тип. Одновременно существует множество `urllib` (см. выше). Диспетчер определяет текущий допустимый размер очереди на основе общего ограничения распределения пауками и длины очереди `queue:scheduled:all`. Затем он извлекает адреса из каждого списка в соответствии со значением приоритета (priority, weight), которое было настроено через веб-конфигурационный центр, и помещает их в очередь `queue:scheduled:all`. Паук извлекает адреса из этой очереди для выполнения сбора информации.
* `updated:driller:rule`
Запись версии правил сбора.Изменения пауков/диспетчеров относительно правил сбора реагируют мгновенно (в режиме реального времени), но полное перезагрузочное сканирование всех правил после каждого распределения (период примерно составляет несколько секунд) невозможно. Поэтому используется система версионирования. После изменения правил сбора через веб-конфигурационный центр версия обновляется. Паук периодически проверяет этот ключ; если обнаруживается изменение версии, то он перезагружает правила сбора.## url_info_redis_db
Это пространство содержит информацию об адресах сайтов. Чем больше время работы системы сбора, тем больше данных здесь накапливается.
* {url-md5-lowercase}
Пример: 9108d6a10bd476158144186138fe0ba8. Хэш-тип, содержащий подробную информацию об адресе сайта, странице, где был найден адрес, текущем состоянии, истории действий пауковой системы (открытие — распределение — сборка — хранение/неудача и т.д.) и последнем времени действия. Эти записи используются диспетчером как основа для принятия решений о том, следует ли снова распределять адрес сайта для сборки.
## url_report_redis_db
Это пространство содержит отчеты о работе пауков.
* fail:urllib:driller:{domain}:{alias}
Пример: fail:urllib:driller:163.com:newslist. Zset-тип, содержащий адреса сайтов, которые не удалось собрать.
* stuck:urllib:driller:{domain}:{alias}
Пример: stuck:urllib:driller:1.63.com:newslist. Zset-тип, содержащий адреса сайтов, которые не удалось сохранить (HBase). Ошибка при захвате/хранении URL можно исправить с помощью tools/queue-helper.js для добавления в очередь повторной попытки захвата.
Замечание: В связи с сетевыми факторами, паук уже выполняет повторные попытки при неудачном захвате; количество таких попыток можно настроить в settings.json. Упомянутые выше ошибки захвата/хранения обычно возникают после нескольких попыток и связаны либо с неправильными правилами захвата, либо с проблемами HBase.* count:{date}
Пример: count:20150203, тип хэша, увеличение статистики захвата, которое находится в соответствующих функциях расширения spider_extend.js. По умолчанию эти строки статистики закомментированы, но если их активировать, они будут выполнять увеличенное статистическое отслеживание. В конфигурационном центре Web "Ежедневный отчёт захвата" можно будет видеть результаты статистики.
## proxy_info_redis_db
Этот раздел предназначен для хранения данных, связанных с прокси-IP.
* proxy:public:available:3s
Список доступных прокси-IP
# [Контакты автора]
* E-mail: <successage@gmail.com>,
* Блог: <http://my.oschina.net/waterbear>
* Проблемы: <http://git.oschina.net/dreamidea/neocrawler/issues? assignee_id=&issue_search=&label_name=&milestone_id=&scope=&sort=&status=all>
* Группа QQ для обсуждения: 3239305
* QQ для беспокоить: 419117039
* WeChat для беспокоить: dreamidea
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )