Слияние кода завершено, страница обновится автоматически


Если вам понравился этот проект, пожалуйста, оставьте звезды ❤️Star❤️, спасибо за поддержку 🤝
Проект назван Sec-Tools, это многофункциональное веб-приложение для проникновения и тестирования безопасности, основанное на Python-Django. Он включает в себя функции проверки уязвимостей, определения директорий, сканирования портов, определения отпечатков, обнаружения доменов, обнаружения соседних сайтов, обнаружения утечек информации.
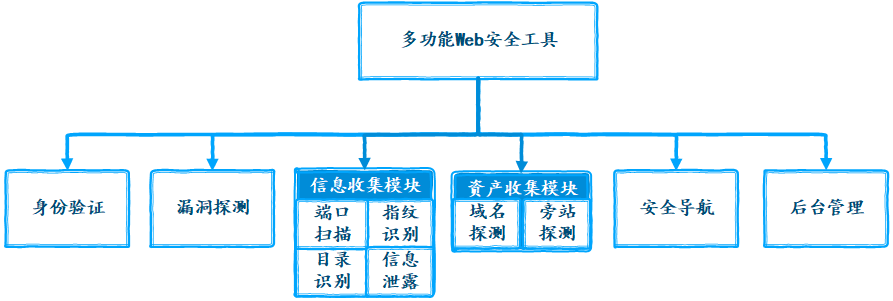
| Название | Python | Django | SQLite | ECharts | Tabler | Layer | Docsify | SimpleUI | Bootstrap Table |
|---|---|---|---|---|---|---|---|---|---|
| Версия | 3.7.0 | 3.1.4 | 3.35.2 | 5.0.1 | 1.0.0 | 3.2.0 | 4.11.6 | 2021.1.1 | 1.18.2 |
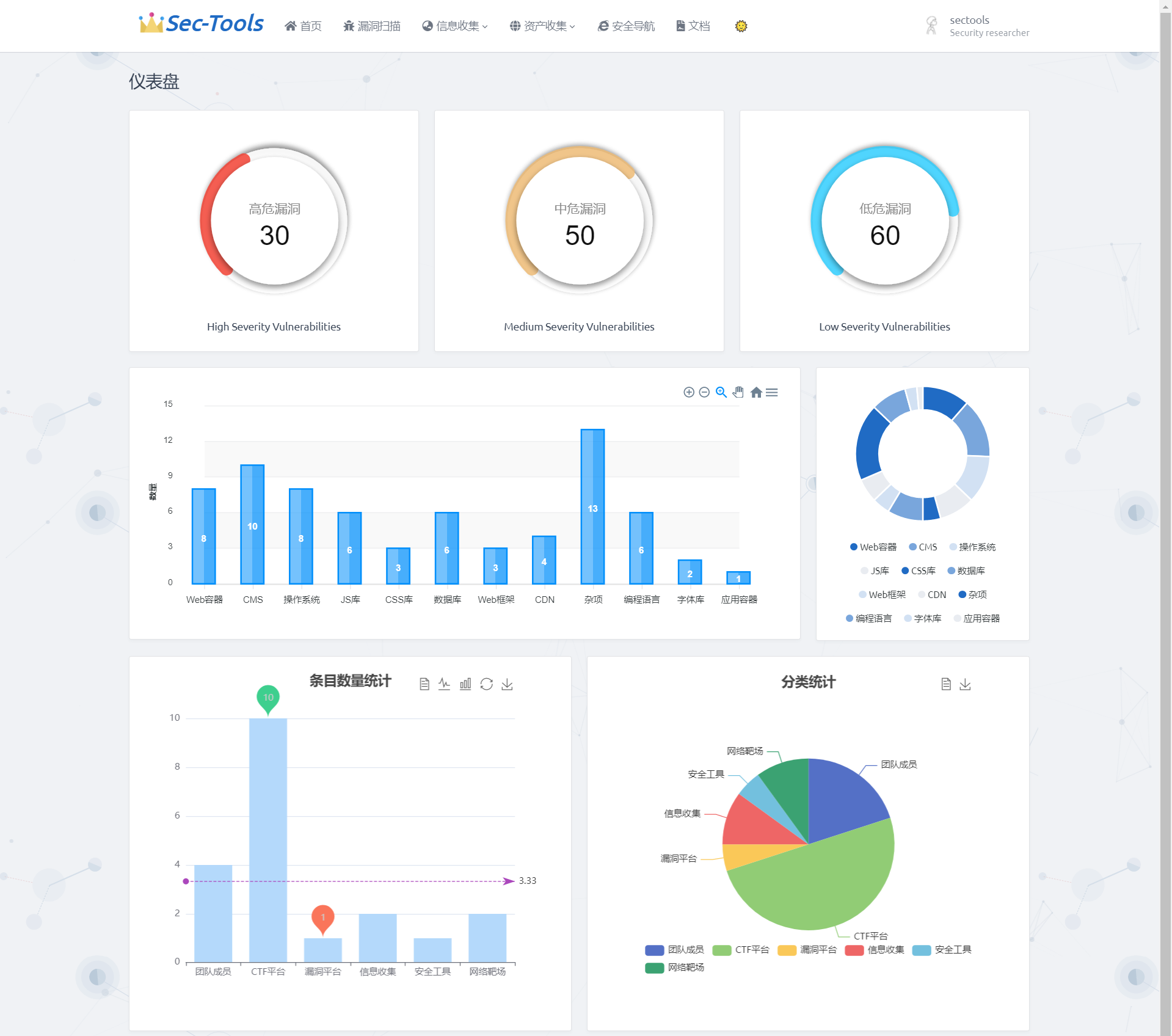
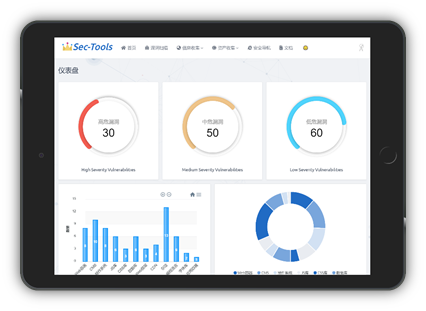
Главная страница использует ECharts для визуализации данных по уровням уязвимостей, результатам идентификации пальцев, а также данным по навигации безопасности. Стиль графиков не унифицирован, но они вполне пригодны для просмотра 😂
auth_user, добавив поле для электронной почты пользователя. Поле пароля в auth_user содержит значение sha256 с добавлением соли, затем кодированное в base64, что обеспечивает безопасность данных пользователей.| Страница входа |  |
|---|---|
| Страница регистрации |  |
| Функция сброса пароля | Реализована с использованием сторонней библиотеки django-password-reset
|
| Шаг 1 |  |
|---|---|
| Шаг 2 |  |
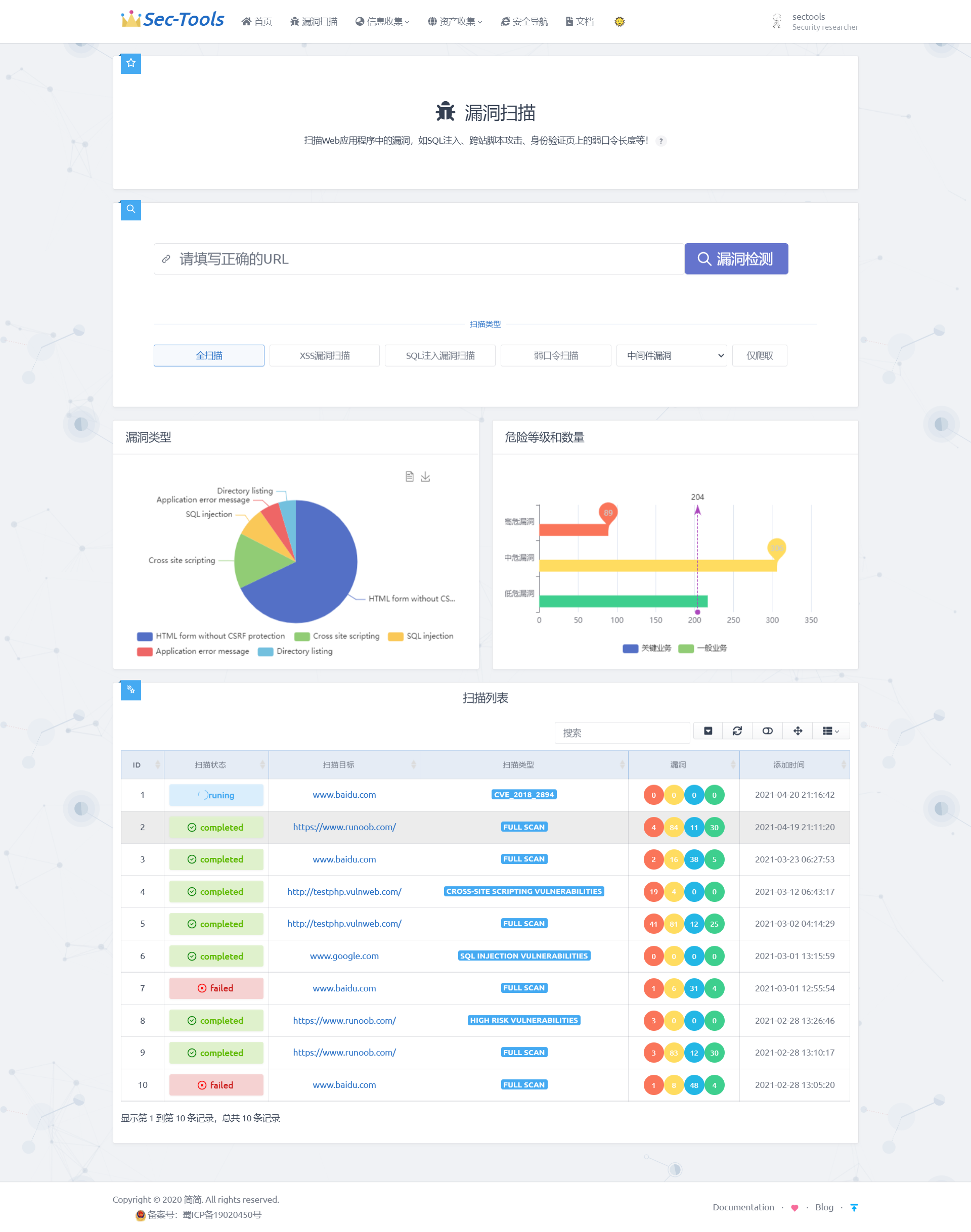
В этом модуле полное сканирование, сканирование на SQL-инъекции, XSS-атаки, сканирование слабых паролей и только сбор информации реализованы с использованием API AWVS. Проверка уязвимостей middleware реализована с помощью скриптов, имитирующих сетевые запросы. На основе причин возникновения уязвимостей создаются тестовые нагрузки (payload), которые отправляются в целевую систему. Затем состояние и данные, возвращаемые системой, используются для определения эффективности нагрузок.
При нажатии на "Проверить целевую систему" происходит переход на страницу с результатами проверки:
При нажатии на "Проверить целевую систему" снова происходит переход на страницу с подробной информацией о проверке:
Первым шагом в проверке уязвимостей является добавление целевой системы в список целей для сканирования AWVS. AWVS предоставляет API-интерфейс: /api/v1/targets, используя POST-запрос, параметры POST-запроса: {"address":"XXXX.XXXX.XXXX","description":"xxxx","criticality":"10"}.При успешном добавлении целевой системы возвращается уникальный идентификатор цели (target_id). Этот идентификатор используется для проверки успешности добавления целевой системы. После добавления целевой системы её сканирование не начинается. Для этого используется другой API-интерфейс: /api/v1/scans, используя POST-запрос, передаются только что добавленный target_id и выбранный пользователем профиль сканирования, параметры POST-запроса: {"target_id":"xxxxxxx","profile_id":"xxxxxxx"}. При успешном запуске сканирования возвращается статус bkod 200. Используйте библиотеку requests для Python для реализации доступа к API-интерфейсам. Основной код представлен ниже:
# Цель: POST-запрос /api/v1/targets
try:
# data содержит целевой URL и тип, auth_headers содержит API_KEY
response = requests.post(targets_api, headers=auth_headers, data=data, verify=False)
result = response.json()
target_id = result.get('target_id')
return target_id
except Exception:
return None
# Сканирование: POST-запрос /api/v1/scans
try:
response = requests.post(scan_api, headers=auth_headers, data=data, verify=False)
status_code = 200
except Exception:
status_code = 404
return status_code
API-интерфейсы уже реализованы, но требуется получить данные, введенные пользователем. Поскольку система реализована на основе Django, HTML и JavaScript используются для предоставления пользовательского интерфейса и получения данных от пользователя, а также отправки их на сервер. Серверная часть написана на Python. Сначала в файле urls.py добавляется маршрут для доступа:path('vuln_scan', views.vuln_scan, name='vuln_scan')
В файле views.py определяется функция vuln_scan(), которая получает введенные пользователем данные и вызывает уже написанные API-функции. URL, введенный пользователем, является целевым объектом для сканирования, а типы сканирования включают SQL-инъекции, XSS-уязвимости, слабые пароли и полное сканирование. Полное сканирование означает сканирование всех типов уязвимостей. Если добавление прошло успешно и возвращенный target_id не равен None, значит добавление прошло успешно, и можно начать вызов API для запуска сканирования. После запуска сканирования возвращается код состояния, если код состояния равен 200, значит сканирование началось успешно, иначе возвращается ошибка. Основной код представлен ниже:
@csrf_exempt
def vuln_scan(request):
# Получаем URL и тип сканирования из POST-запроса
url = request.POST.get('ip')
scan_type = request.POST.get('scan_type')
t = Target(API_URL, API_KEY)
# Добавляем целевой URL в список для сканирования
target_id = t.add(url)
# Если target_id не равен None, начинаем сканирование
if target_id is not None:
s = Scan(API_URL, API_KEY)
status_code = s.add(target_id, scan_type)
if status_code == 200:
return success()
return error()
```Наконец, JavaScript используется для отправки данных, введенных пользователем, выбором POST-метода для отправки данных и проверкой валидности введенных данных перед отправкой. Основной код представлен ниже:
```javascript
function get_scan_info(ip, scan_type) {
// Используем POST-запрос для отправки данных пользователя
$.post('/vuln_scan', {
ip: ip,
scan_type: scan_type
}, function (data) {
if (data.code !== 200) {
......
} else {
......
}
......});
}
var domain = $('input[name=scan_url]').val();
// Используем цикл для проверки выбранного типа сканирования
for (var i = 0; i < document.getElementsByName("scan_type").length; i++) {
if (document.getElementsByName("scan_type")[i].checked) {
var scan_type = document.getElementsByName("scan_type")[i].value;
}
}
if (domain) {
get_scan_info(domain, scan_type);
} else {
......
}
В целом, благодаря реализации вышеуказанного кода, была достигнута передача пользовательского ввода с помощью JavaScript на сервер, сервер принимает данные и вызывает API AWVS, после чего AWVS начинает сканирование целевого URL на основе пользовательского ввода. По завершении сканирования результат сохраняется в базе данных. Реализованный функционал представлен ниже:
В предыдущем разделе результаты сканирования сохранялись в базе данных, нам необходимо получить все сканируемые цели, используя 'api/v1/scans', метод запроса — GET. Успешный запрос вернёт информацию обо всех сканируемых целях, что позволяет реализовать отображение всех сканируемых целей. Для реализации отображения всех уязвимостей для каждой сканируемой цели необходимо искать по target_id среди всех сканируемых целей. AWVS предоставляет соответствующий API: /api/v1/vulnerabilities
?q=severity:{int};criticality:{int};status:{string};cvss_score:{logicexpression};cvss_score:{logicexpression};target_id:{target_id};group_id:{group_id}. Метод запроса — GET. Используя target_id, ищем каждую сканируемую цель. Это также решает проблему URL страницы с деталями уязвимости. При успешном поиске целей по target_id возвращается информация о найденных уязвимостях, включая количество уязвимостей, уровень опасности каждого уязвимости, время сканирования, тип сканирования, статус сканирования и т. д.
Конкретные шаги реализации и добавления сканируемых целей в основном схожи. Сначала используется requests для выполнения запроса к API. Основной код представлен ниже:```python
response = requests.get(scan_api, self.auth_headers, False) scan_response = response.json().get('scans') for scan in scan_response: scan['request_url'] = request_url scan_list.append(scan) return scan_list
vuln_search_api = f'{vuln_api}?q=status:{status};target_id:{target_id}' try:
response = requests.get(vuln_search_api, auth_headers, False)
return response.text
except Exception: return None
В **urls.py** добавьте URL для доступа пользователей, который требует предоставления `target_id` для последующей реализации функционала. Сначала получите все `target_id` для всех целей, а затем используйте цикл для добавления всех `target_id` в список `urlpatterns`. Поскольку в Django функции представлений (`views`) обычно принимают только один параметр `request`, а здесь требуется передать `target_id` в функцию представления, используйте регулярное выражение `"(?P<target_id>.*)$"` для получения `target_id`. В функции представления второй формальный параметр должен иметь такое же имя, как и значение внутри `<>`. Основной код представлен ниже:
```python
from django.urls import path
from . import views
urlpatterns = [
path('targets/<str:target_id>/', views.target_view, name='target_view'),
]
``````python
from django.urls import path
from . import views
urlpatterns = []
targets = views.get_all_targets() # Предполагается, что эта функция возвращает список всех целей
for target in targets:
urlpatterns.append(path(f'<target_id:{target.target_id}>$', views.target_view, name='target_view')) # Замените 'target_view' на имя вашей функции представления
Обратите внимание, что в реальном коде вам потребуется корректно сформировать URL-шаблон для каждого target_id, используя методы, предоставляемые Django для работы с URL.```python
path('vulnscan', views.vulnscan, name="vulnscan"),
for target_id in target_ids:
# Используем регулярное выражение для получения второго параметра: target_id
urlpatterns.append(url(r'^vuln_result/(?P<target_id>.*)$', views.vuln_result, name='vuln_result/' + target_id))
В файле **views.py** определены функции `vulnscan(request)` для получения всех соответствующих данных о уязвимостях целей. Используется API для получения уровня опасности уязвимостей, URL-адреса сканируемого объекта, уникального идентификатора уязвимости vuln_id, типа сканирования и времени выполнения сканирования. Время выполнения сканирования, возвращаемое API, не имеет стандартного формата, поэтому используется регулярное выражение для его преобразования в формат `"YYYY-MM-DD HH:MM:SS"`. Также определена функция `vuln_result(request, target_id)` для получения всех данных о уязвимостях для указанного сканируемого объекта по его идентификатору, включая URL-адреса уязвимостей, типы уязвимостей, статусы и время выполнения. Основной код представлен ниже:
``````python
@login_required
def vuln_result(request, target_id):
d = Vuln(API_URL, API_KEY)
data = []
vuln_details = json.loads(d.search(None, None, "open", target_id=str(target_id)))
id = 1
for target in vuln_details['vulnerabilities']:
item = {
'id': id,
'severity': target['severity'],
'target': target['affects_url'],
'vuln_id': target['vuln_id'],
'vuln_name': target['vt_name'],
'time': re.sub(r'T|\..*$', " ", target['last_seen'])
}
id += 1
data.append(item)
return render(request, 'vuln-reslut.html', {'data': data})
В этом подфункциональном блоке отображение данных на фронтенде осуществляется с помощью таблицы Bootstrap. Эта таблица имеет множество полезных функций, таких как функция поиска в таблице, функция пагинации и т.д., что улучшает пользовательский опыт. Данные таблицы в HTML принимаются с помощью двойных фигурных скобок, а в функции views.py при возврате соответствующего HTML-шаблона вместе с data-словарем, данные могут быть получены с помощью ключей словаря. Также можно использовать if-else, for и другие конструкции для классификации данных. Основной код представлен ниже:
{% for item in data %}
……………
# Здесь показан только столбец с URL-адресами целей, остальные столбцы аналогичны
<a href="/vuln_detail/{{ item.vuln_id }}"> {{ item.target }}</a>
……………
{% endfor %}
@login_required
def vuln_result(request, target_id):
d = Vuln(API_URL, API_KEY)
data = []
vuln_details = json.loads(d.search(None, None, "open", target_id=str(target_id)))
id = 1
for target in vuln_details['vulnerabilities']:
item = {
'id': id,
'severity': target['severity'],
'target': target['affects_url'],
'vuln_id': target['vuln_id'],
'vuln_name': target['vt_name'],
'time': re.sub(r'T|\..*$', " ", target['last_seen'])
}
id += 1
data.append(item)
return render(request, 'vuln-reslut.html', {'data': data})
В этом подфункциональном блоке отображение данных на фронтенде осуществляется с помощью таблицы Bootstrap. Эта таблица имеет множество полезных функций, таких как функция поиска в таблице, функция пагинации и т.д., что улучшает пользовательский опыт. Данные таблицы в HTML принимаются с помощью двойных фигурных скобок, а в функции views.py при возврате соответствующего HTML-шаблона вместе с data-словарем, данные могут быть получены с помощью ключей словаря. Также можно использовать if-else, for и другие конструкции для классификации данных. Основной код представлен ниже:
{% for item in data %}
……………
# Здесь показан только столбец с URL-адресами целей, остальные столбцы аналогичны
<a href="/vuln_detail/{{ item.vuln_id }}"> {{ item.target }}</a>
……………
{% endfor %}
```В итоге реализованный интерфейс выглядит следующим образом: в зависимости от статуса сканирования уязвимостей отображаются в разном цвете (красный, желтый, синий, зелёный для классификации угроз высокого, среднего, низкого уровня и информации). В конце отображается время выполнения сканирования.
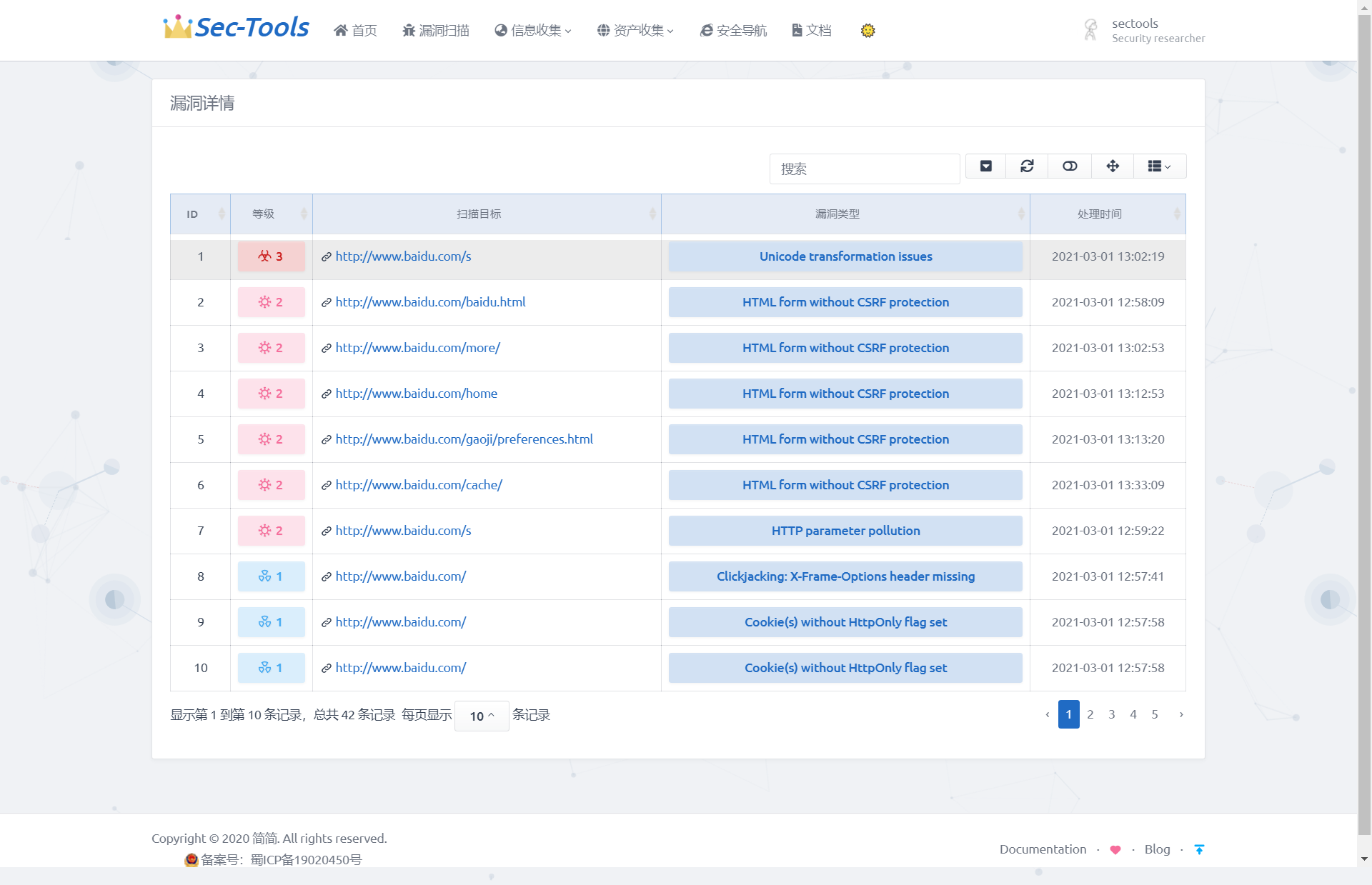
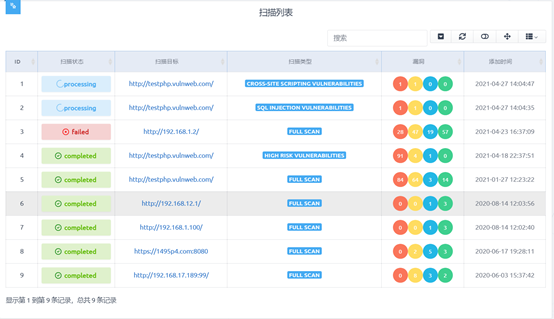Таблица с отсканированными целями позволяет перейти по ссылке для просмотра всех уязвимостей цели, как показано на следующем рисунке, который демонстрирует уровень опасности каждого уязвимости, URL-адреса, содержащие уязвимости, и тип уязвимости для определенной цели сканирования.

#### Получение деталей уязвимости
После реализации сканирования уязвимостей и отображения результатов необходимо получить детали каждого уязвимости. Это включает параметры запроса, вызывающие уязвимость, тестовые нагрузки (payload), пакеты данных запроса, краткие рекомендации по исправлению и т.д. Поскольку каждая уязвимость имеет уникальный идентификатор vuln_id, можно использовать этот идентификатор для запроса всех данных о конкретной уязвимости. Используемый API имеет следующий формат: `/api/v1/vulnerabilities/{vuln_id}`, метод запроса - GET.
Аналогично, сначала используем requests для вызова API, передавая vuln_id для запроса информации о конкретной уязвимости. Код представлен ниже:
```python
# Получение информации о конкретной уязвимости
def get(self, vuln_id):
vuln_get_api = f'{self.vuln_api}/{vuln_id}'
try:
# Используем GET запрос для передачи vuln_id API, результат возвращается в формате JSON
response = requests.get(vuln_get_api, auth_headers, False)
return response.json()
except Exception:
return None
```В файле **urls.py** добавляем URL для получения деталей уязвимости. Здесь используется аналогичный подход к предыдущему разделу, где используется регулярное выражение для получения второго параметра функции из файла **views.py**, но вместо `target_id` используется `vuln_id`. Код представлен ниже:
```python
for vuln_id in vuln_ids:
urlpatterns.append(url(r'^vuln_detail/(?P<vuln_id>.*)$', views.vuln_detail, name='vuln_detail/' + vuln_id))
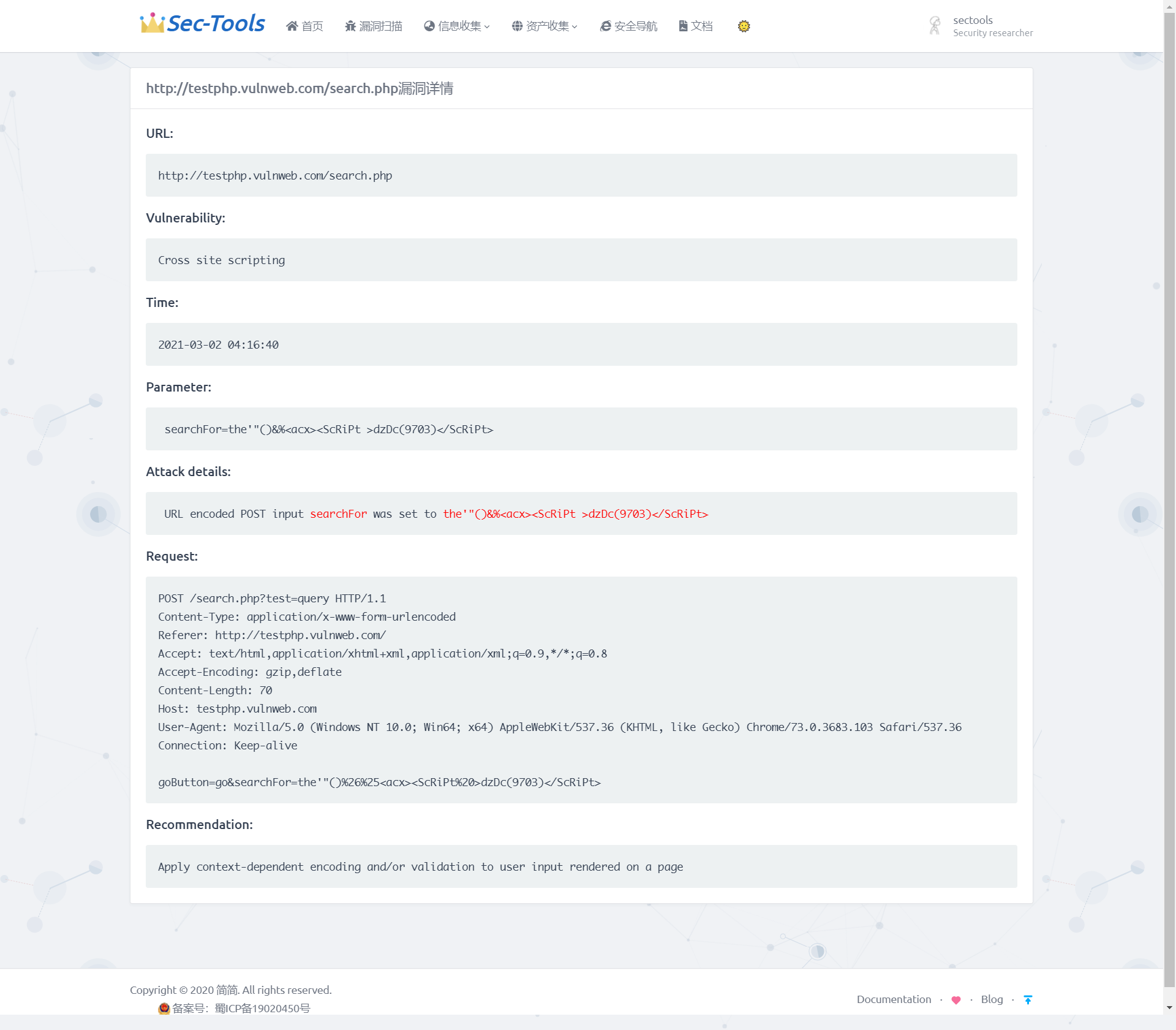
```В файле **views.py** определяем функцию `vuln_details(request, vuln_id)`, которая использует `vuln_id` для получения информации о конкретной уязвимости. Эта функция извлекает полезные данные из ответа API и помещает их в словарь `data`, который затем передается в файл `vuln-details.html`. В этом файле используются двойные фигурные скобки для получения URL, затронутых уязвимостью, времени обнаружения, типа уязвимости, параметров тестирования уязвимости, пакетов данных запроса и кратких рекомендаций по исправлению. Результат представлен на следующем рисунке.

```python
@login_required
def vuln_details(request, vuln_id):
d = Vuln(API_URL, API_KEY)
data = d.get(vuln_id)
print(data)
parameter_list = BeautifulSoup(data['details'], features="html.parser").findAll('span')
request_list = BeautifulSoup(data['details'], features="html.parser").findAll('li')
data_dict = {
'affects_url': data['affects_url'],
'last_seen': re.sub(r'T|\. .*$', " ", data['last_seen']),
'vt_name': data['vt_name'],
'details': data['details'].replace(" ", '').replace('</p>', ''),
'request': data['request'],
'recommendation': data['recommendation'].replace('<br/>', '\n')
}
try:
data_dict['parameter_name'] = parameter_list[0].contents[0]
data_dict['parameter_data'] = parameter_list[1].contents[0]
except:
pass
num = 1
try:
Str = ''
for i in range(len(request_list)):
Str += str(request_list[i].contents[0]) + str(request_list[i].contents[1]).replace('<strong>', '').replace('</strong>', '') + '\n'
num += 1
except:
pass
data_dict['Tests_performed'] = Str
data_dict['num'] = num
data_dict['details'] = data_dict['details'].replace('class="bb-dark"', 'style="color: #ff0000"')
return render(request, "vuln-detail.html", {'data': data_dict})
 png)#### Проведение сканирования уязвимостей middleware на основе тестирования POC> В данной системе используются POC-скрипты для сканирования уязвимостей в некоторых middleware, включая Weblogic, Tomcat, Drupal, JBoss, Nexus, Struts2 и другие. Используя особенности каждого уязвимости, разработаны различные POC-скрипты на Python для проверки наличия уязвимости на целевой системе.
png)#### Проведение сканирования уязвимостей middleware на основе тестирования POC> В данной системе используются POC-скрипты для сканирования уязвимостей в некоторых middleware, включая Weblogic, Tomcat, Drupal, JBoss, Nexus, Struts2 и другие. Используя особенности каждого уязвимости, разработаны различные POC-скрипты на Python для проверки наличия уязвимости на целевой системе.
В данном случае пользовательский интерфейс совместим с сканированием уязвимостей на основе AWVS, но добавлен выбор уязвимостей middleware по CVE-идентификаторам. Используется JavaScript для отправки данных, введенных пользователем, на сервер. Основной код представлен ниже:
// Использование POST-запроса для отправки данных пользователя
function get_Middleware_scan(ip, CVE_id) {
$.post('/Middleware_scan', {
ip: ip, // Целевой URL
CVE_id: CVE_id // Выбранный CVE-идентификатор
}, function (data) {
// Обработка возвращаемых данных
………
………
});
}
После добавления целей в базу данных, производится их поиск и запуск сканирования. Для доступа к функции запуска сканирования используется AJAX. Ввиду того, что время выполнения сканирования может быть достаточно большим, необходимо установить достаточно большое значение таймаута для ожидания возврата результатов. Основной код представлен ниже:
$.ajax({
// Использование POST-запроса для отправки целевого URL и CVE-идентификатора, установка таймаута в 10 секунд
type: "POST",
url: '/start_Middleware_scan',
timeout: 10000,
data: {
ip: ip,
CVE_id: CVE_id
}
});
```В файле **urls.py** добавляются пути для доступа к сканированию уязвимостей middleware. Необходимо добавить два пути: `'Middleware_scan'` и `'start_Middleware_scan'`. Первый путь используется для добавления целей сканирования, второй — для запуска сканирования после добавления целей в базу данных. После завершения сканирования обновляется статус соответствующей цели в базе данных. Такой подход позволяет в реальном времени отслеживать статус сканирования.
Для хранения данных используется база данных SQLite. В файле **models.py** создается таблица Middleware_vuln с полями ID, целевой URL, статус, результат, CVE-идентификатор и отметка времени. В Django этот класс определяет структуру таблицы базы данных. После создания таблицы в файле **models.py** используется команда `python manage.py makemigrations` для создания миграций, а затем команда `python manage.py migrate` для применения миграций и создания таблицы в базе данных. Основной код представлен ниже:
```python
class Middleware_vuln(models.Model):
# Имя класса является именем таблицы в базе данных, а переменные — именами полей. Определение полей приведено ниже
id = models.AutoField(primary_key=True)
url = models.CharField(max_length=100, null=True)
status = models.CharField(max_length=20, null=True)
result = models.CharField(max_length=100, null=True)
cve_id = models.CharField(max_length=100, null=True)
time = models.CharField(max_length=100, null=True, unique=True)
```При добавлении целей и запуске проверок нам нужно вставлять данные в базу данных и выполнять запросы к ней. Для этого используется функциональность Django для работы с базой данных. Для вставки данных в `Middleware_vuln` используется `Middleware_vuln.objects.create(url, status, result, CVE_id, time)`, а для обновления — `Middleware_vuln.objects.filter(time).update(status, result)`. Также необходимо использовать блок `try-except` для обработки исключений и вывода сообщений об ошибках.```python
def insert_Middleware_data(url, CVE_id, Time, result=None, status="runing"):
try:
Middleware_vuln.objects.create(url=url, status=status, result=result, CVE_id=CVE_id, time=Time)
print("вставка успешна")
return True
except:
print("ошибка вставки данных")
return False
def update_Middleware_data(url, CVE_id, Time, result):
try:
Middleware_vuln.objects.filter(url=url, status='runing', CVE_id=CVE_id, time=Time).update(status="completed", result=result)
print("обновление успешное")
except:
print("ошибка обновления данных")
В файле views.py определена функция Middleware_scan(), которая получает ввод пользователя и вставляет его в базу данных. Переменная Time является глобальной и используется как условие для поиска данных в базе данных. Если вставка данных проходит успешно, возвращается success(), в противном случае — error(). Эти функции возвращают коды состояния, где success() возвращает 200, а error() — 404. Эти коды состояния используются JavaScript для вывода соответствующих сообщений.
Time = 0.0
@csrf_exempt
@login_required
def Middleware_scan(request):
# Используем POST-запрос для получения ввода пользователя и вставки его в базу данных.
# Переменная Time используется как глобальная переменная для вставки в базу данных и как условие для поиска данных.
global Time
try:
url = request.POST.get('ip')
CVE_id = request.POST.get('CVE_id').replace('-', '_')
Time = time.time() # time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(t)) преобразование временной метки в формат даты
if insert_Middleware_data(url, CVE_id, Time):
return success()
except:
return error()
def start_Middleware_scan():
# Определи функцию start_Middleware_scan(), которая реализует запрос целей из базы данных,
# где метка времени равна Time, а состояние равно run. Затем используй соответствующий POC-скрипт
# по номеру CVE. В конце обнови результаты сканирования и состояние сканирования в базе данных.
# Поскольку в предыдущем шаге данные могут быть вставлены в базу данных некоторое время,
# необходимо использовать sleep() для ожидания завершения вставки данных перед выполнением запроса и сканирования,
# чтобы гарантировать, что ни одна цель не будет упущена.
targets = get_targets(Time, 'run')
for target in targets:
poc_script = get_poc_script(target['CVE_id'])
result = poc_script(target['url'])
update_scan_results(target['id'], result)
update_scan_status(target['id'], 'completed')
time.sleep(1)
```
```python
Time = 0.0
@csrf_exempt
@login_required
def Middleware_scan(request):
# Используем POST-запрос для получения ввода пользователя и вставки его в базу данных.
# Переменная Time используется как глобальная переменная для вставки в базу данных и как условие для поиска данных.
global Time
try:
url = request.POST.get('ip')
CVE_id = request.POST.get('CVE_id').replace('-', '_')
Time = time.time() # time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(t)) преобразование временной метки в формат даты
if insert_Middleware_data(url, CVE_id, Time):
return success()
except:
return error()
def start_Middleware_scan():
# Определи функцию start_Middleware_scan(), которая реализует запрос целей из базы данных,
# где метка времени равна Time, а состояние равно run. Затем используй соответствующий POC-скрипт
# по номеру CVE. В конце обнови результаты сканирования и состояние сканирования в базе данных.
# Поскольку в предыдущем шаге данные могут быть вставлены в базу данных некоторое время,
# необходимо использовать sleep() для ожидания завершения вставки данных перед выполнением запроса и сканирования,
# чтобы гарантировать, что ни одна цель не будет упущена.
targets = get_targets(Time, 'run')
for target in targets:
poc_script = get_poc_script(target['CVE_id'])
result = poc_script(target['url'])
update_scan_results(target['id'], result)
update_scan_status(target['id'], 'completed')
time.sleep(1)
``````python
@csrf_exempt
@login_required
def start_Middleware_scan(request):
try:
url = request.POST.get('ip')
ip, port = urlparse(url).netloc.split(':')
CVE_id = request.POST.get('CVE_id').replace('-', "_")
time.sleep(5) # ожидание завершения вставки данных перед выполнением запроса
msg = Middleware_vuln.objects.filter(url=url, status='runing', CVE_id=CVE_id, time=Time)
print(msg)
# сканируемые элементы могут быть более одного, поэтому необходимо использовать цикл для сканирования
for target in msg:
result = POC_Check(target.url, target.CVE_id)
# обновление результатов сканирования и состояния
update_Middleware_data(target.url, target.CVE_id, Time, result)
return success()
except:
return error()
```
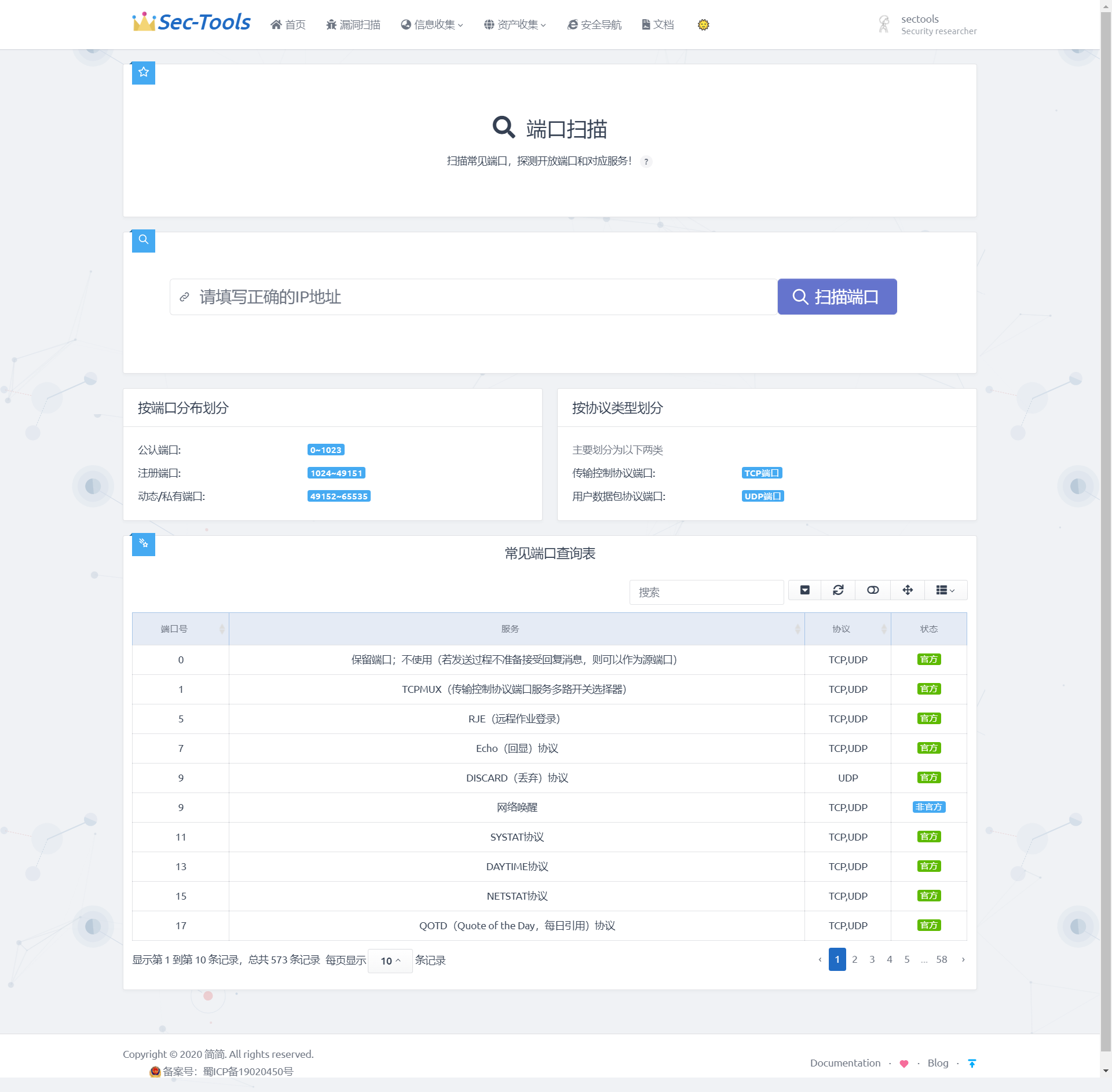
## Портовый сканер
> В данной системе портовый сканер начинает работу после того, как пользователь указывает целевой IP-адрес. Система формирует запрос на сканирование, передает IP-адрес в фоновую часть для сканирования целей. После завершения сканирования открытые порты и соответствующие службы отображаются на пользовательском интерфейсе. В разделах "По портам" и "По протоколам" описывается, как разделены порты, чтобы избавить пользователя от необходимости выполнять сложные запросы. Кроме того, в этом модуле встроена таблица часто используемых портов, где можно выполнять поиск и фильтрацию портов и соответствующих служб. С помощью этих функций пользователь может более четко понять, какие службы открыты на целевой машине, что позволяет анализировать возможные уязвимости.### Концептуальное решение
Реализация портового сканера в данной системе осуществляется с использованием библиотек Python, таких как Socket, для установления соединения с целевым компьютером через TCP-триплет. Когда завершается полный TCP-триплет, можно заключить, что порт и соответствующая служба открыты, в противном случае они закрыты. Для повышения эффективности сканирования в данной системе используется многопоточное сканирование.
### Результат реализации
### Подробная реализация
#### Портовый сканер
Через Python напрямую определяется сокет, пытаясь установить соединение с целевым портом. В данном программном обеспечении используется метод `sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM);` для установления TCP-соединения, вызывая `sock.connect_ex((ip, port))`, чтобы попытаться установить соединение с портом. Если порт открыт, возвращается 0, в противном случае возвращается код ошибки. Используются блоки `try` для перехвата исключений, если соединение сокета превышает время ожидания, возвращается информация об обработке исключений. Основной код представлен ниже:```python
def socket_scan(self, hosts):
'''Основной код сканера портов'''
global PROBE
socket.setdefaulttimeout(1)
ip, port = hosts.split(':')
try:
if len(self.port) < 25:
# Создание сокета
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Установка TCP/IP соединения через три рукопожатия
result = sock.connect_ex((ip, int(port)))
# Вызов socket.connect_ex((ip, port)), если порт открыт, возвращается 0, в противном случае возвращается код ошибки
# Реализация функциональности, аналогичной полному соединению сканированию nmap.
if result == 0: # Успешное установление TCP соединения
self.port.append(port) # Добавление порта в результат
for i in PROBE: # Пробный запрос через HTTP 1.1
sock.sendall(i.encode()) # Отправка полного TCP пакета
response = sock.recv(256) # Прием до 256 байт
sock.close()
if response:
break
if response:
for pattern in SIGNS:
pattern = pattern.split(b'|')
if re.search(pattern[-1], response, re.IGNORECASE):
# Поиск совпадений с шаблоном для получения информации о бренде
proto = '{}:{}'.format(pattern[1].decode(), port)
self.out.append(proto) # Добавление к выходным данным
break
else:
self.num = 1
except (socket.timeout, ConnectionResetError): # Обработка исключений
pass
except:
pass
Если такой однопоточный (последовательный) блокирующий режим используется, это займет значительное время. Поэтому, для ускорения процесса сканирования, используется параллельный подход, параллельные запросы, что позволяет значительно ускорить процесс сканирования. В сравнении, сканирование 300 портов в однопоточном режиме занимает около 30 секунд, в то время как в многопоточном режиме это занимает около 10 секунд. В данной функции порт-сканирования используется параллельное выполнение 64 потоков для сканирования. Поэтому, при определении метода run, каждый поток сканирует диапазон из 64 портов. В программе используется модуль concurrent.futures для реализации параллельного выполнения. Модуль concurrent.futures предоставляет высокоуровневый интерфейс для асинхронного выполнения вызовов. Асинхронное выполнение может быть реализовано с помощью потоков, используя ThreadPoolExecutor, или с помощью отдельных процессов, используя ProcessPoolExecutor. Оба они реализуют одинаковый интерфейс, определенный абстрактным классом Executor.
THREADNUM = 64 # количество потоков
def run(self, ip): # многопоточное сканирование
hosts = []
global PORTS, THREADNUM
for i in PORTS:
hosts.append('{}:{}'.format(ip, i))
try:
with concurrent.futures.ThreadPoolExecutor(
max_workers=THREADNUM) as executor:
executor.map(self.socket_scan, hosts)
except EOFError:
pass
```#### Таблица портов
Функция построения таблицы портов выполняется путем сбора информации о портах из интернета и созданием базы данных для поиска портов. В случае обработки дел с участием иностранных сторон, данные о портах хранятся в базе данных, включая номер порта, услугу, соответствующую порту, протокол, соответствующий порту, и состояние порта. Структура таблицы для поиска портов показана в таблице ниже.
| Поле | Тип поля | Допускает пустое значение | Является первичным ключом | Примечание |
| ---------- | ------------ | -------------------------- | -------------------------- | ------------------ |
| id | integer | Не допускает пустое значение | Да | ID порта |
| num | bigint | Не допускает пустое значение | Нет | Номер порта |
| service | text | Не допускает пустое значение | Нет | Услуга, соответствующая порту |
| protocol | Varchar(20) | Не допускает пустое значение | Нет | Протокол, соответствующий порту |
| status | Varchar(10) | Не допускает пустое значение | Нет | Статус порта |
Таблица портов создается с использованием Django Model, содержащая поля номер порта, услуга, протокол и статус. Реализация кода представлена ниже:```python
class PortList(models.Model):
'''Port table'''
num = models.BigIntegerField(verbose_name='Номер порта')
service = models.TextField(max_length=100, verbose_name='Услуга')
protocol = models.CharField(max_length=20, verbose_name='Протокол', blank=True, default='Неизвестно')
status = models.CharField(max_length=10, verbose_name='Статус', blank=True, default='Неизвестно')
class Meta:
# Admin panel header settings
verbose_name = verbose_name_plural = 'Список портов'
После создания базы данных необходимо зарегистрироваться в административной панели, чтобы иметь возможность управлять данными из административного интерфейса. Реализация кода приведена ниже:```python
@admin.register(PortList)
class PortListAdmin(ImportExportModelAdmin):
# Установка полей, отображаемых в административной панели
list_display = ('num', 'service', 'protocol', 'status',)
# Установка поля num для перехода в режим редактирования
list_display_links = ('num',)
search_fields = ('num', 'service',)
# Фильтры для поиска по полям
list_filter = ('protocol', 'status')
# Установка поля num как поля для сортировки
ordering = ('num', )
list_per_page = 15 # Установка количества записей на страницу
## Удостоверение по отпечаткам пальцев
> В этом модуле используется извлечение информации о характеристиках отпечатков пальцев для идентификации веб-отпечатков. Система создает множество специальных HTTP-запросов для взаимодействия с веб-сервером и извлекает информацию о характеристиках отпечатков из ответных данных. Затем эта информация сравнивается с базой данных отпечатков, чтобы получить информацию о компонентах и версиях веб-сервера и приложений. Обнаружение и идентификация этих характеристик помогают нам быстро разрабатывать стратегию проникновения, что является ключевым шагом в процессе проникновения.
### Концептуальное решениеВнутри и за пределами страны исследования веб-серверов и приложений по отпечаткам пальцев в основном включают создание множества специальных HTTP-запросов для взаимодействия с веб-сервером и извлечение информации о характеристиках отпечатков из ответных данных. Затем эта информация сравнивается с базой данных отпечатков, чтобы получить информацию о компонентах и версиях веб-сервера и приложений. В данной статье используется метод на основе ключевых слов для реализации функции идентификации отпечатков. Для повышения точности результатов сравнения с несколькими основными базами данных отпечатков, была проведена серия оптимизаций для базы данных данной системы.### Результат реализации
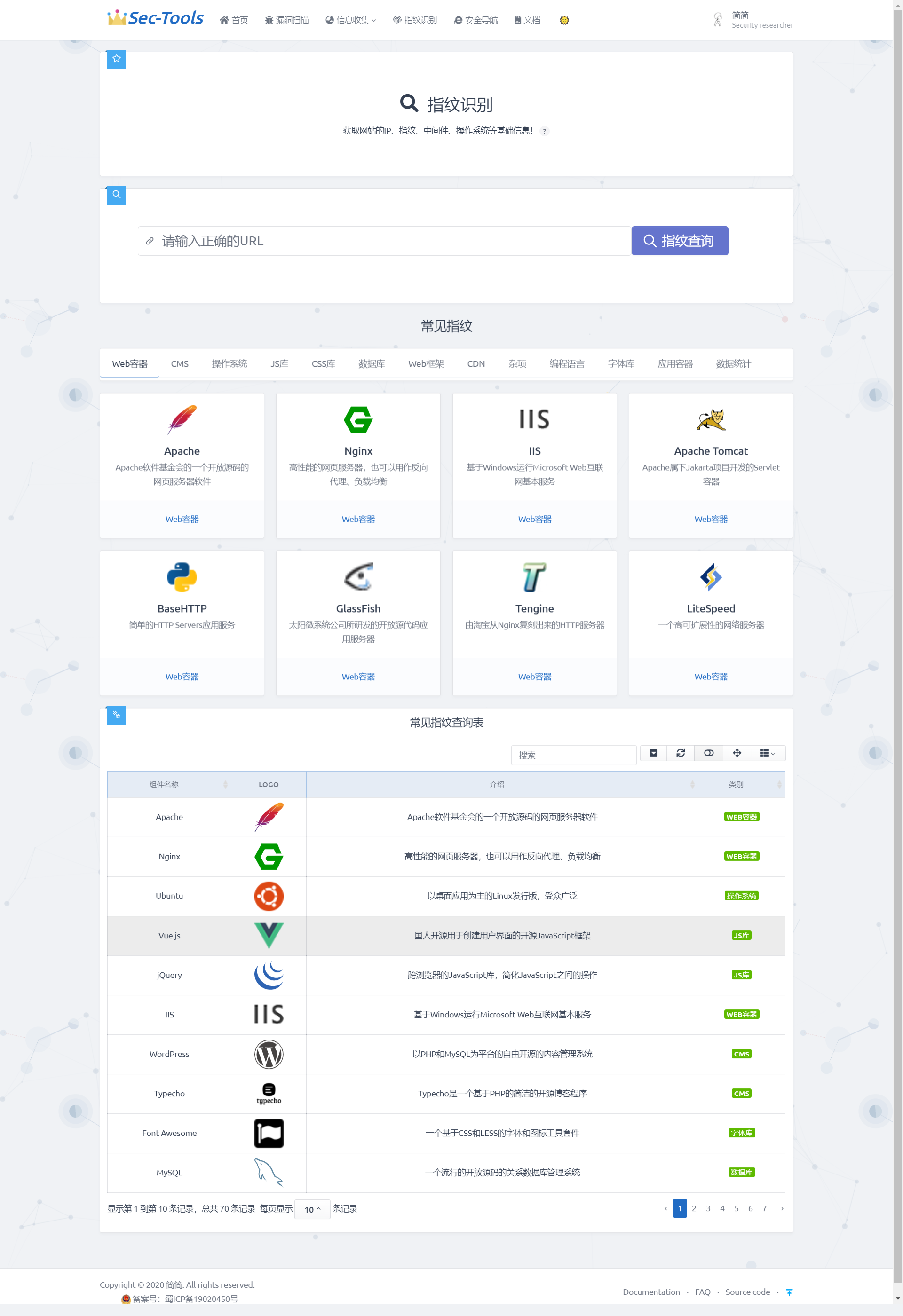
### Подробная реализация
Ключевым этапом процесса идентификации отпечатков пальцев является извлечение характеристик отпечатков пальцев. Для извлечения характеристик отпечатков пальцев сначала необходимо определить, какие данные следует извлекать из ответных данных пакетов. Поэтому необходимо разработать алгоритм извлечения характеристик для анализа ответных данных пакетов. Ответные данные пакеты состоят из строки ответа, заголовка ответа и тела ответа. Строка ответа состоит из версии HTTP, кода состояния и описания кода состояния. Заголовок ответа используется для указания клиенту, как обрабатывать тело ответа. В заголовке ответа содержится множество компонентных данных, которые используются для указания браузеру типа ответа, кодировки символов, типа сервера и размера в байтах. Тело ответа представляет собой конкретные данные, возвращаемые сервером клиенту в ответ на запрос клиента. Заголовок ответа и тело ответа содержат поля, которые могут быть использованы для идентификации компонентов веб-отпечатков пальцев. Поэтому извлечение ключевых полей из заголовка ответа и тела ответа является ядром технологии идентификации отпечатков пальцев.
Fingerprint-идентификация включает в себя два этапа: сбор информации и веб-fingerprint-идентификацию.(I) Сбор информации: на этом этапе собираются специфические данные веб-приложения, используя URL, введенные пользователем. Возвращаются ключевые слова страницы, специальные файлы и пути, которые являются характеристиками. Чем больше собрано ключевых данных, тем точнее будет результат последующей идентификации.
(2) Веб-фingerprint-идентификация: этот этап состоит из двух частей. Первая часть связана с созданием базы данных fingerprint, которая собирает характеристики известных веб-приложений и создает базу данных fingerprint. В данной работе анализ HTTP-ответов позволяет разработать правила для извлечения fingerprint-идентификаторов. Анализ заголовков ответов и содержимого ответов позволяет создать базу данных fingerprint-компонентов, которая хранится в формате JSON. Информация о fingerprint-идентификаторах собирается с платформ, таких как Wappalyzer и FOFA. Вторая часть включает сбор характеристик из веб-приложений, которые подлежат тестированию, и сравнение их с базой данных fingerprint-идентификаторов для идентификации веб-приложений.
## Сканирование директорий
> Сканирование директорий реализовано по аналогии с dirsearch, включая типы веб-приложений, таких как php, asp, jsp, и т. д. Также предусмотрены опции рекурсивного сканирования и пользовательского сканирования. Поддерживается настройка префиксов и суффиксов или подкаталогов.### Концептуальное описание
Результаты сканирования dirsearch сохраняются в соответствующих путях в формате JSON, что позволяет уменьшить зависимость от баз данных. Полученные данные разделяются на URL и TIME, где URL включает в себя content-length, path, redirect, status. Поскольку данные, заключенные в различные типы скобок в JSON, могут быть интерпретированы Django как списки или словари, необходимо обрабатывать полученные данные JSON и преобразовывать их в формат, который может быть распознан Django, чтобы они могли быть отображены на фронтенде.
Для правильного анализа данных необходимо сначала понять методы преобразования между структурами данных Python и JSON.
### Результат реализации
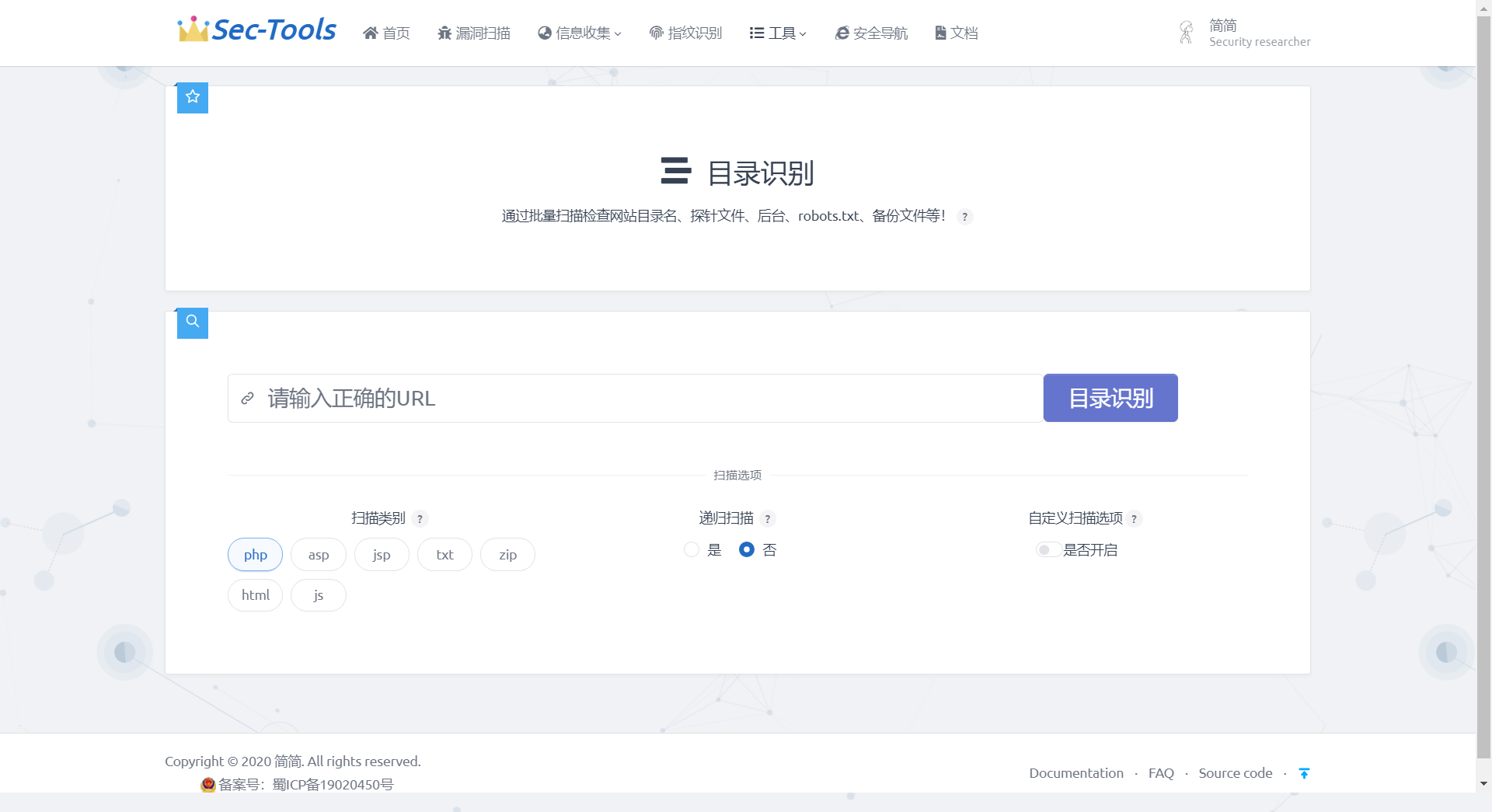
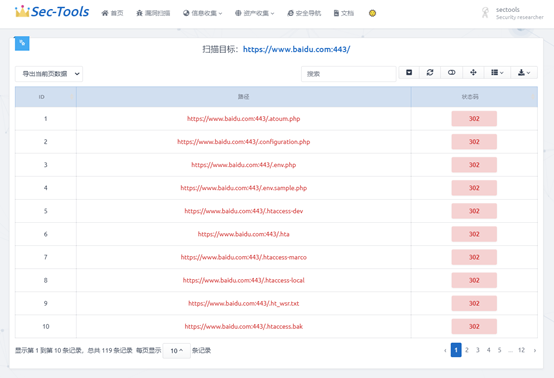
## Утечка информации
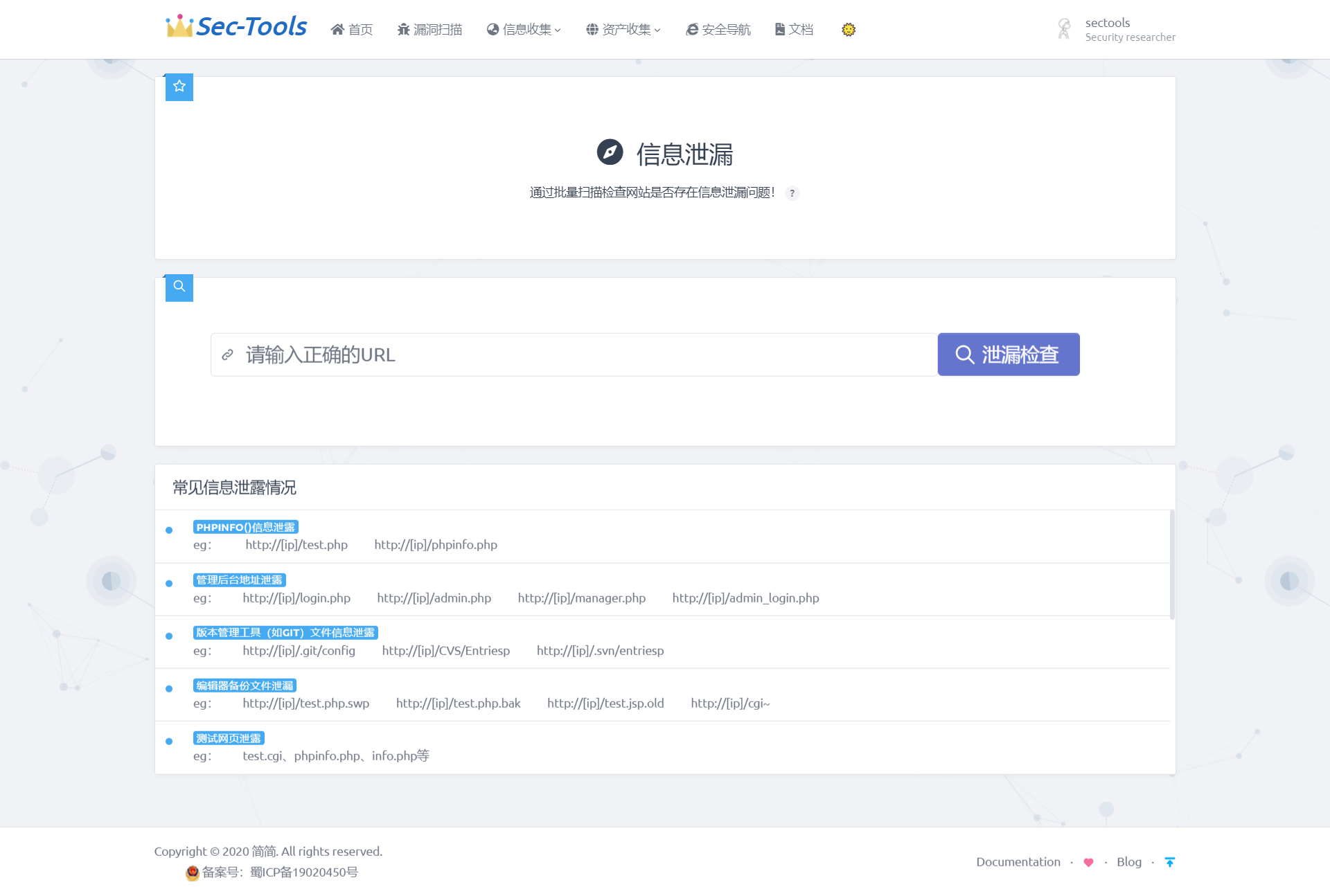
Этот модуль предназначен для проверки типичных утечек информации для пользователей. Веб-адреса, конфигурационные файлы и другие потенциально утечные данные отображаются в интерфейсе пользователя. В результатах пользователи могут легко определить утечки информации в конкретном веб-сервисе.
## Параллельный сканер
Этот модуль предназначен для получения информации о других сайтах, размещенных на том же сервере, по IP-адресу. Модуль напрямую вызывает API для выполнения своей функции.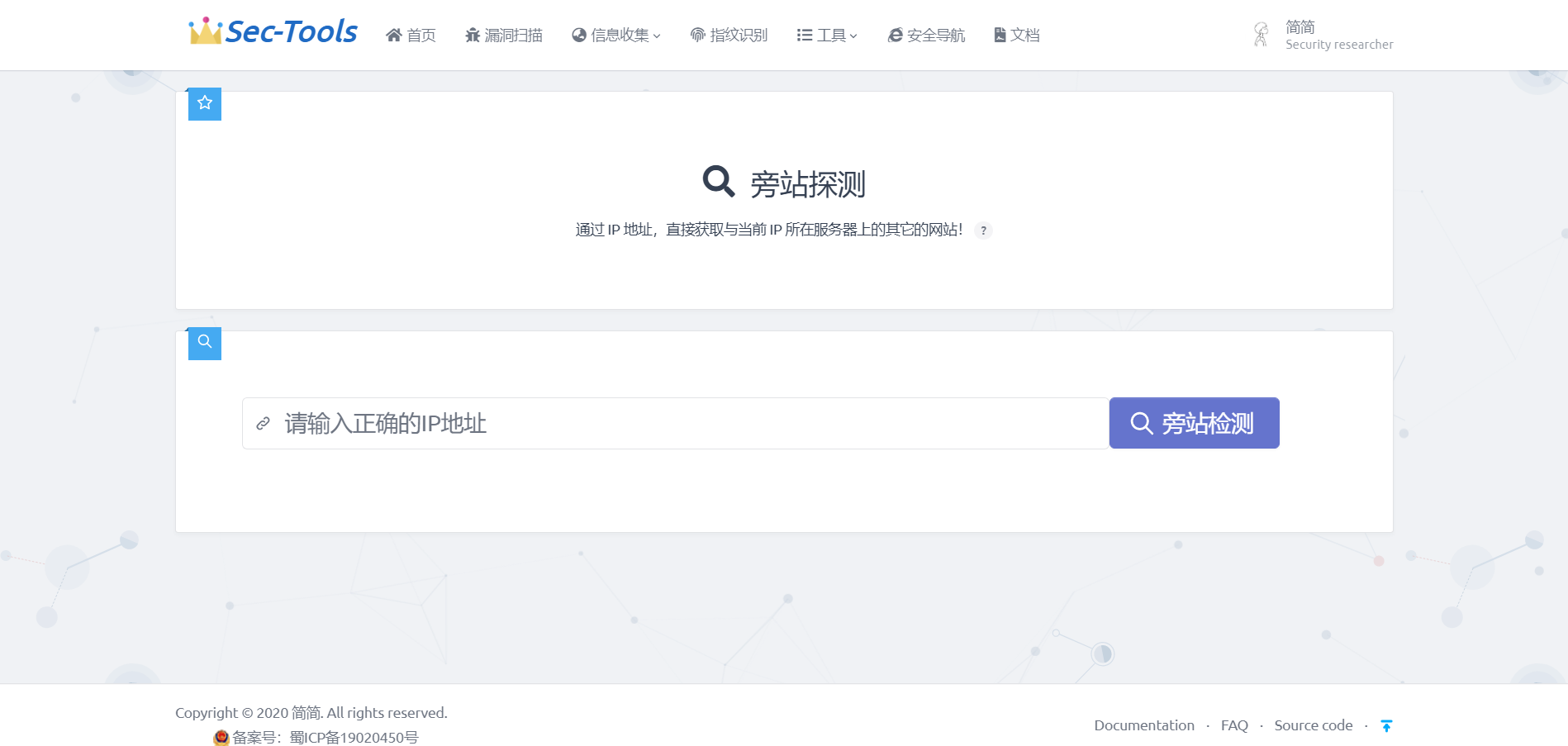
## Сканирование поддоменов
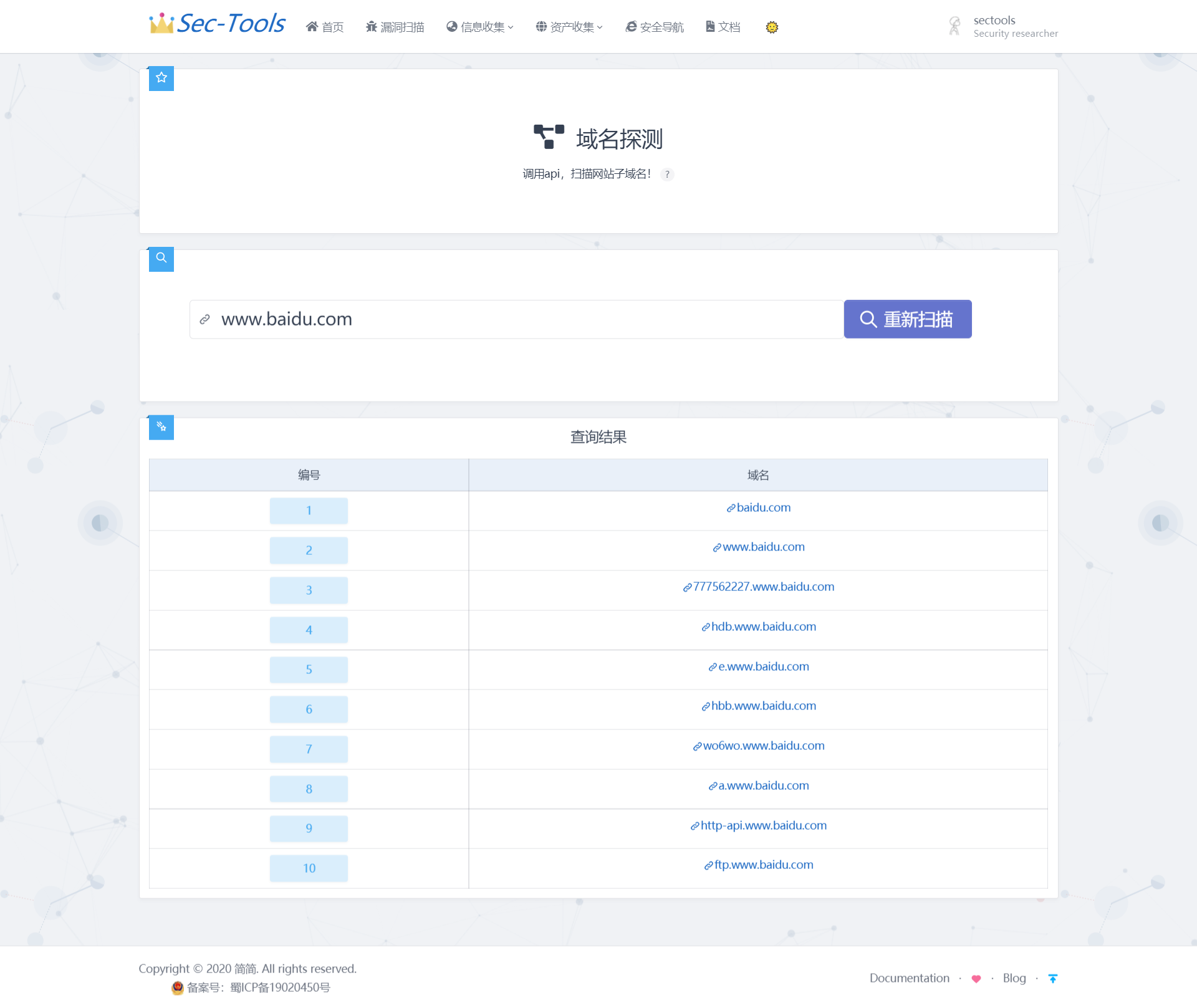
Этот модуль предназначен для сканирования поддоменов сайта с помощью вызова API.
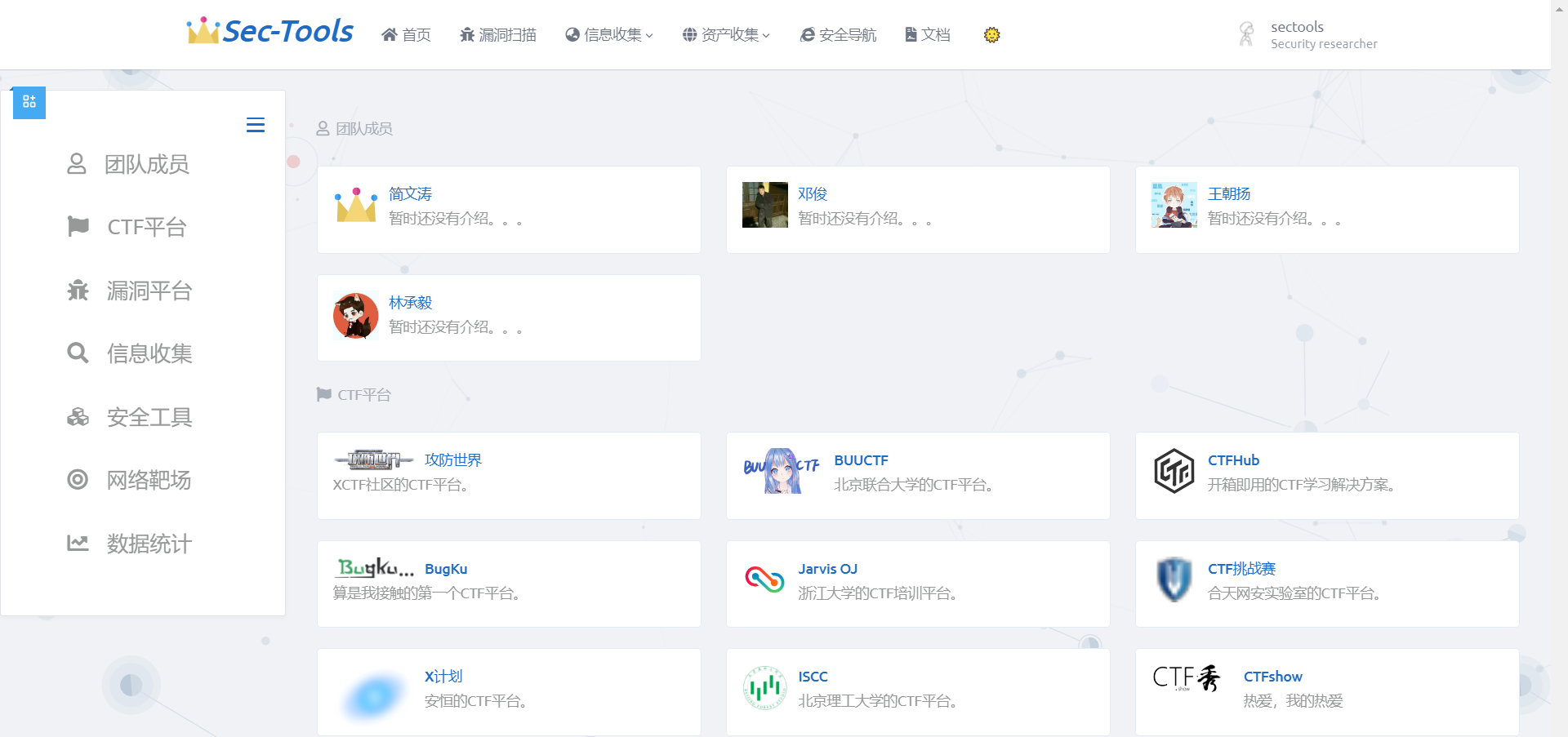
## Безопасное навигирование
Страница безопасного навигирования вдохновлена проектом [Webstack](http://webstack.cc/) от [Viggo](http://viggoz.com/). Проект разработан на основе Bootstrap и представляет собой чисто фронтенд-страницу. В фронтенде я использовал стиль `Webstack` и объединил его с `Tabler UI`, а также написал бэкенд с использованием `Django` для управления категориями и элементами в режиме онлайн.
### Фронтенд-страница
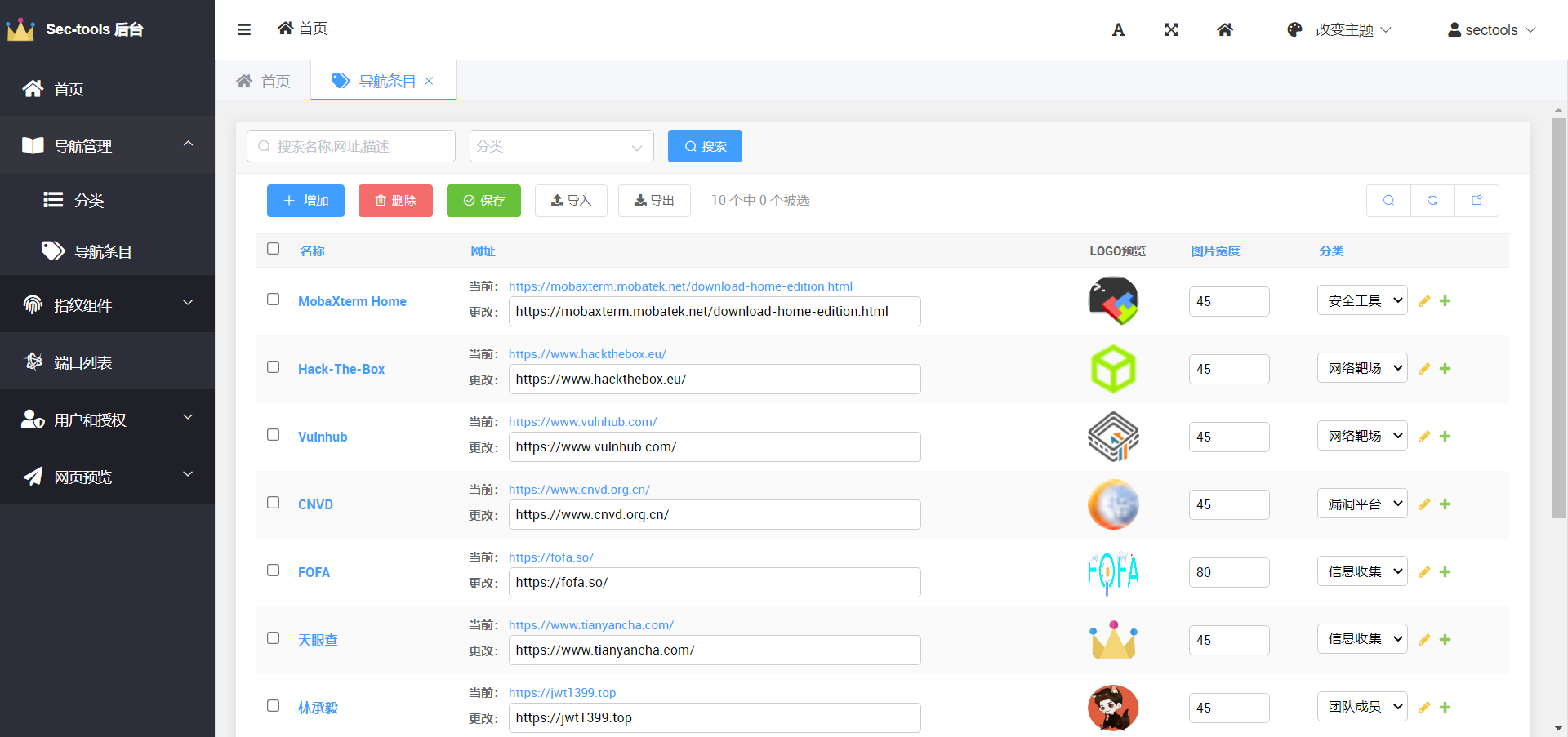
### Страница управления бэкендом
### Проектирование базы данных
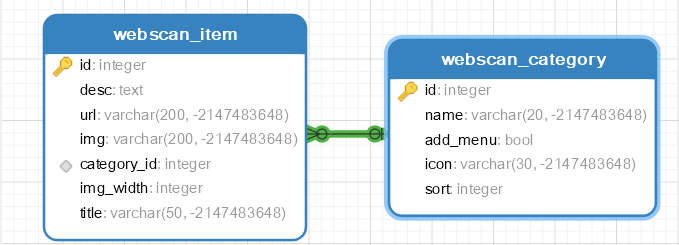
#### Элементы навигации - Item
> Заголовок title Описание desc Ссылка url Категория category (внешний ключ) Изображение img Ширина изображения img_width```python
class Item(models.Model):
'''Navigation items'''
title = models.CharField(max_length=50, verbose_name='Title')
desc = models.TextField(max_length=100, verbose_name='Description')
url = models.URLField(verbose_name='URL', blank=True)
img = models.URLField(default='https://jwt1399.top/favicon.png', verbose_name='Logo')
img_width = models.IntegerField(default=45, verbose_name='Image width')
category = models.ForeignKey(Category, blank=True, null=True, verbose_name='Category', on_delete=models.CASCADE)
class Meta:
verbose_name = verbose_name_plural = 'Navigation items'
# Preview of the item's image in the admin panel
def img_admin(self):
return format_html('<img src="{}" width="50px" height="50px" style="border-radius: 50%;" />', self.img,)
img_admin.short_description = 'Logo preview'
def __str__(self):
return self.title
```#### Категории элементов - Category
> Название name Сортировка sort Добавить в навигацию add_menu Иконка icon```python
class Category(models.Model):
"""Категории элементов"""
name = models.CharField(max_length=20, verbose_name='Название')
sort = models.IntegerField(default=1, verbose_name='Порядок отображения')
add_menu = models.BooleanField(default=True, verbose_name='Добавить в навигационное меню')
icon = models.CharField(max_length=30, default='fas fa-home', verbose_name='Иконка')
class Meta:
verbose_name_plural = verbose_name = 'Категории'
``` # Подсчет количества элементов и сохранение в админке
def get_items(self):
return len(self.item_set.all())
get_items.short_description = 'Количество элементов' # Установка заголовка для отображения в админке
# Предварительный просмотр иконки в админке
def icon_data(self): # Использование Font Awesome Free 5.11.1
return format_html('<h1><i class="{}"></i></h1>', self.icon) # Преобразование в <i class="{self.icon}"></i>
icon_data.short_description = 'Предварительный просмотр иконки'
def __str__(self):
return self.name
Документация была интегрирована в Django с использованием Docsify.

| Портретный режим | Альбомный режим |
|---|---|
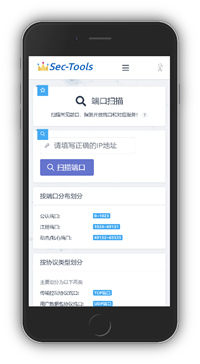 |
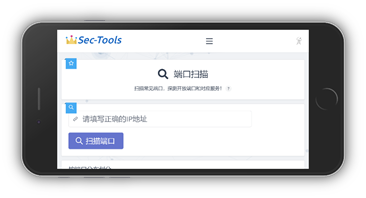 |
| Портретный режим | Альбомный режим |
|---|---|
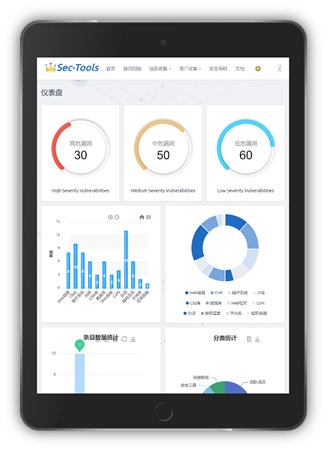 |
 |
Добавлена функция "детектирования соседних сайтов";
Добавлена функция "анализа данных" на странице навигации;
Добавлена страница документации на основе "Docsify";
Переработана структура "статических файлов";
Улучшена структура файлов проекта;
Улучшена "страница регистрации";
Введен "динамический эффект частиц" для фона;
Исправлены некоторые "UI" проблемы отображения;### v2.1 (2021-01-13)
Добавлена функция "распознавания отпечатков пальцев";
Добавлена функция "логина и регистрации";
Добавлена "страница приветствия";
Добавлена страница документации;
Исправлены некоторые "UI" проблемы отображения;
Откройте проект в PyCharm, перейдите в PyCharm -> "Settings" -> "Project Interpreter" и добавьте новую виртуальную среду.
В этой виртуальной среде откройте встроенный терминал PyCharm и выполните команду pip install -r requirements.txt для установки необходимых пакетов.3. Теперь проект можно запустить, но для использования функции сканирования уязвимостей необходимо установить AWVS и настроить API URL и API KEY в файле settings.py проекта.
Настройки для функции восстановления пароля изменяются в файле проекта `settings.py````python EMAIL_HOST = 'smtp.163.com' EMAIL_PORT = 25 # Порт SMTP-сервера отправителя EMAIL_HOST_USER = 'xxx' # Ваш адрес электронной почты EMAIL_HOST_PASSWORD = "xxx" # Пароль доступа к почтовому ящику EMAIL_USE_TLS = True # Здесь должно быть True, иначе отправка не будет успешной EMAIL_FROM = 'xxx' # Ваш адрес электронной почты DEFAULT_FROM_EMAIL = 'xxx' # Ваш адрес электронной почты
5. Создание суперпользователя `python manage.py createsuperuser`
6. По умолчанию учетная запись: sectools/password..!!
### Развертывание на сервере
Для подробностей обратитесь к: [Быстрое развертывание проекта Django с помощью панели управления Baota](https://www.django.cn/article/show-30.html)
## TO DO
> Независимо от того, работаете ли вы над разработкой или безопасностью, кажется, что у вас есть долгий путь вперед. Долгий путь к совершенству, я буду искать его вверх и вниз, вместе с вами!
- [ ] Страница с инструментами безопасности
- [ ] Страница с книгами по безопасности
- [ ] Введение MySQL-базы данных
- [ ] Оптимизация алгоритма сканирования
- [ ] Оптимизация переменных кода и структуры базы данных
- [ ] Функция экспорта отчета о уязвимостях
- [ ] Асинхронное обновление страниц
## Вкладчики проекта
- @Adam
- @xiafeng
- @lcyok
## Поддержка💰
Если вы считаете, что это было полезно для вас, вы можете угостить меня холодным коктейлем! Хи-хи🤭<table>
<tbody>
<tr>
<td style="text-align:center;">AliExpress</td>
<td style="text-align:center;">WeChat</td>
</tr>
<tr>
<td style="text-align:center;"><img width="200" src="https://jwt1399.top/medias/reward/alipay.png"></td>
<td style="text-align:center;"><img width="200" src="https://jwt1399.top/medias/reward/wechat.png"></td>
</tr>
</tbody>
</table>
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )