Слияние кода завершено, страница обновится автоматически
Основные вкладчики этого репозитория включают Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, и Yichen Wei.
Глубокий поток признаков был впервые описан в статье CVPR 2017. Он предоставляет простую, быструю, точную и конечную-до-конечную архитектуру для распознавания видео (например, детекции объектов и семантического сегментирования в видео). Стоит отметить, что:
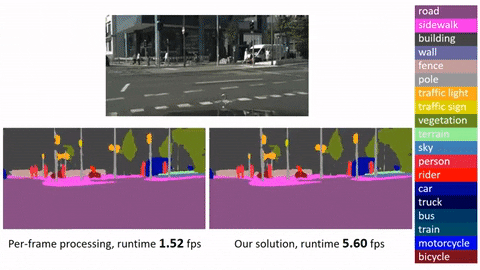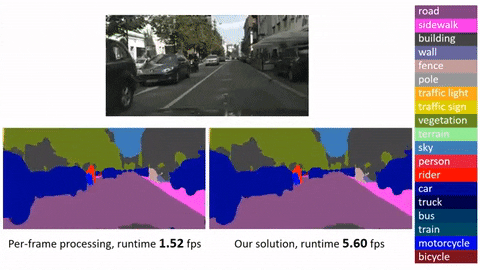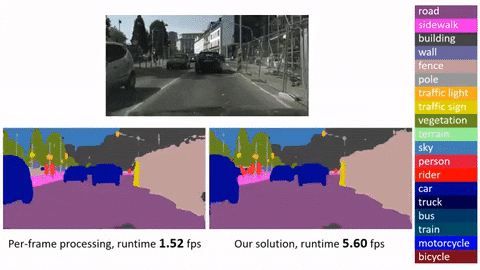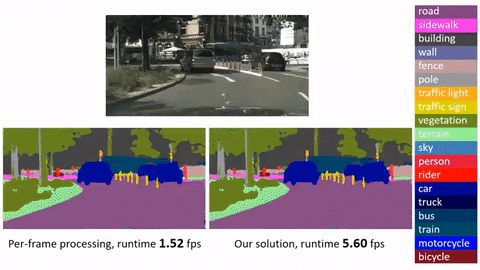

Это официальная реализация для Глубокого потока признаков для распознавания видео (DFF) на основе MXNet. Стоит отметить, что:
Если вы обнаружили, что Deep Feature Flow полезен в вашем исследовании, пожалуйста, рассмотрите возможность цитирования:
@inproceedings{zhu17dff,
Author = {Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, Yichen Wei},
Title = {Deep Feature Flow for Video Recognition},
Conference = {CVPR},
Year = {2017}
}
@inproceedings{dai16rfcn,
Author = {Jifeng Dai, Yi Li, Kaiming He, Jian Sun},
Title = {{R-FCN}: Object Detection via Region-based Fully Convolutional Networks},
Conference = {NIPS},
Year = {2016}
}
| обучающие данные | тестовые данные | mAP@0.5 | время/изображение(Tesla K40) | время/изображение(Maxwell Titan X) | |
|---|---|---|---|---|---|
| Базовая модель(R-FCN, ResNet-v1-101) | ImageNet DET train + VID train | ImageNet VID validation | 74.1 | 0.271с | 0.133с |
| Deep Feature Flow(R-FCN, ResNet-v1-101, FlowNet) | ImageNet DET train + VID train | ImageNet VID validation | 73.0 | 0.073с | 0.034с |
Время выполнения подсчитано на одном GPU (размер mini-batch равен 1 в режиме инференса, продолжительность ключевых кадров для Deep Feature Flow составляет 10).
Время выполнения легковесного FlowNet кажется немного большим на MXNet, чем на Caffe.
Пакеты Python могут быть отсутствовать: cython, opencv-python >= Yöntem 3.2.0, easydict. Если pip настроен на вашей системе, эти пакеты должны быть доступны для загрузки и установки при выполнении
pip install Cython
pip install opencv-python==3.2.0.6
pip install easydict==1.6
Для пользователей Windows требуется Visual Studio 2015 для компиляции модуля cython. ## Требования: аппаратное обеспечение
Любые GPU NVIDIA с не менее 6 ГБ памяти должны подойти.
git clone https://github.com/msracver/Deep-Feature-Flow.git
Для пользователей Windows запустите cmd .\init.bat. Для пользователей Linux запустите sh ./init.sh. Скрипты автоматически построят модуль cython и создадут некоторые папки.
Установите MXNet: 3.1 Клонируйте MXNet и переключитесь на MXNet@(commit 62ecb60) командой
git clone --recursive https://github.com/dmlc/mxnet.git
git checkout 62ecb60
git submodule update
3.2 Скопируйте операторы из $(DFF_ROOT)/dff_rfcn/operator_cxx или $(DFF_ROOT)/rfcn/operator_cxx в $(YOUR_MXNET_FOLDER)/src/operator/contrib командой
cp -r $(DFF_ROOT)/dff_rfcn/operator_cxx/* $(MXNET_ROOT)/src/operator/contrib/
3.3 Скомпилируйте MXNet
cd ${MXNET_ROOT}
make -j4
3.4 Установите Python-пакет MXNet командой
cd python
sudo python setup.py install
3.5 Для продвинутых пользователей вы можете поместить свой Python-пакет в ./external/mxnet/$(YOUR_MXNET_PACKAGE), и измените MXNET_VERSION в ./experiments/dff_rfcn/cfgs/*.yaml на $(YOUR_MXNET_PACKAGE). Таким образом вы сможете быстро переключаться между различными версиями MXNet.## Демонстрация
Чтобы запустить демонстрацию с нашим обученным моделью (на ImageNet DET + VID train), пожалуйста, скачайте модель вручную с OneDrive (для пользователей из материкового Китая, пожалуйста, попробуйте Baidu Yun), и поместите её в папку model/.
Убедитесь, что структура папки выглядит так:
./model/rfcn_vid-0000.params
./model/rfcn_dff_flownet_vid-0000.params
Запустите (размер пакета для инференса = 1)
python ./rfcn/demo.py
python ./dff_rfcn/demo.py
или запустите (размер пакета для инференса = 10)
python ./rfcn/demo_batch.py
python ./dff_rfcn/demo_batch.py
Пожалуйста, скачайте ILSVRC2015 DET и ILSVRC2015 VID датасет, и убедитесь, что структура папок выглядит так:
./data/ILSVRC2015/
./data/ILSVRC2015/Annotations/DET
./data/ILSVRC2015/Annotations/VID
./data/ILSVRC2015/Data/DET
./data/ILSVRC2015/Data/VID
./data/ILSVRC2015/ImageSets
Пожалуйста, скачайте предобученные модели ImageNet ResNet-v1-101 и Flying-Chairs FlowNet из OneDrive (для пользователей из материкового Китая, попробуйте Baidu Yun), и поместите их в папку ./model. Убедитесь, что структура папки выглядит следующим образом:
./model/pretrained_model/resnet_v1_101-0000.params
./model/pretrained_model/flownet-0000.params
Все настройки наших экспериментов (номер GPU, набор данных и т.д.) хранятся в yaml-файлах конфигурации в папке ./experiments/{rfcn/dff_rfcn}/cfgs.2. На данный момент предоставлено два файла конфигурации: базовая модель кадра с R-FCN и глубокий потоковый фичей с R-FCN для ImageNet VID. Мы используем 4 GPU для обучения моделей на ImageNet VID.
Для выполнения экспериментов запустите python-скрипт с соответствующим файлом конфигурации в качестве входных данных. Например, чтобы обучить и протестировать глубокий потоковый фичей с R-FCN, используйте следующую команду:
python experiments/dff_rfcn/dff_rfcn_end2end_train_test.py --cfg experiments/dff_rfcn/cfgs/resnet_v1_101_flownet_imagenet_vid_rfcn_end2end_ohem.yaml
Будет автоматически создан кэш-файл для сохранения модели и логов в папке output/dff_rfcn/imagenet_vid/.
Пожалуйста, найдите более подробную информацию в файлах конфигурации и в нашем коде.
Код был протестирован под:
В: Он говорит AttributeError: 'module' object has no attribute 'MultiProposal'.
О: Это потому что либо
вы забыли скопировать операторы в вашу папку MXNet
или вы скопировали в неправильное место
или вы забыли перекомпилировать и установить
или вы установили неправильную версию MXNet
Пожалуйста, распечатайте mxnet.__path__, чтобы убедиться, что вы используете правильную версию MXNet
В: Я столкнулся с segmentation fault в начале.
О: Выявлено совместимое ограничение между MXNet и opencv-python 3.0+. Мы рекомендуем вам всегда import cv2 перед import mxnet в основном скрипте.
В: Я обнаружил, что скорость обучения становится медленнее при длительном обучении.
A: Установлено, что MXNet на Windows имеет эту проблему. Поэтому мы рекомендуем запускать этот программный код на Linux. Вы также можете остановить его и возобновить процесс обучения, чтобы восстановить скорость обучения, если вы столкнулись с этой проблемой.
Q: Можете ли вы поделиться вашей реализацией Caffe?
A: По нескольким причинам (код основан на старой внутренней версии Caffe, перенос на публичную версию Caffe требует дополнительной работы, ограничение по времени и т.д.). Мы не планируем выпускать наш код Caffe. Поскольку слой преобразования легко реализовать, любой желающий может сделать pull request.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )