Слияние кода завершено, страница обновится автоматически
![]()
![]()

Zipkin — это система распределенной трассировки. Она помогает собирать временные данные, необходимые для устранения проблем с задержками в архитектуре сервисов. Возможности системы включают как сбор, так и поиск этих данных.
Если у вас есть идентификатор трассировки в лог-файле, вы можете сразу перейти к нему. В противном случае вы можете выполнить запрос на основе атрибутов, таких как сервис, имя операции, метки и продолжительность. Интересные данные будут автоматически суммированы для вас, такие как процент времени, затраченного на сервис, и то, были ли операции успешными.
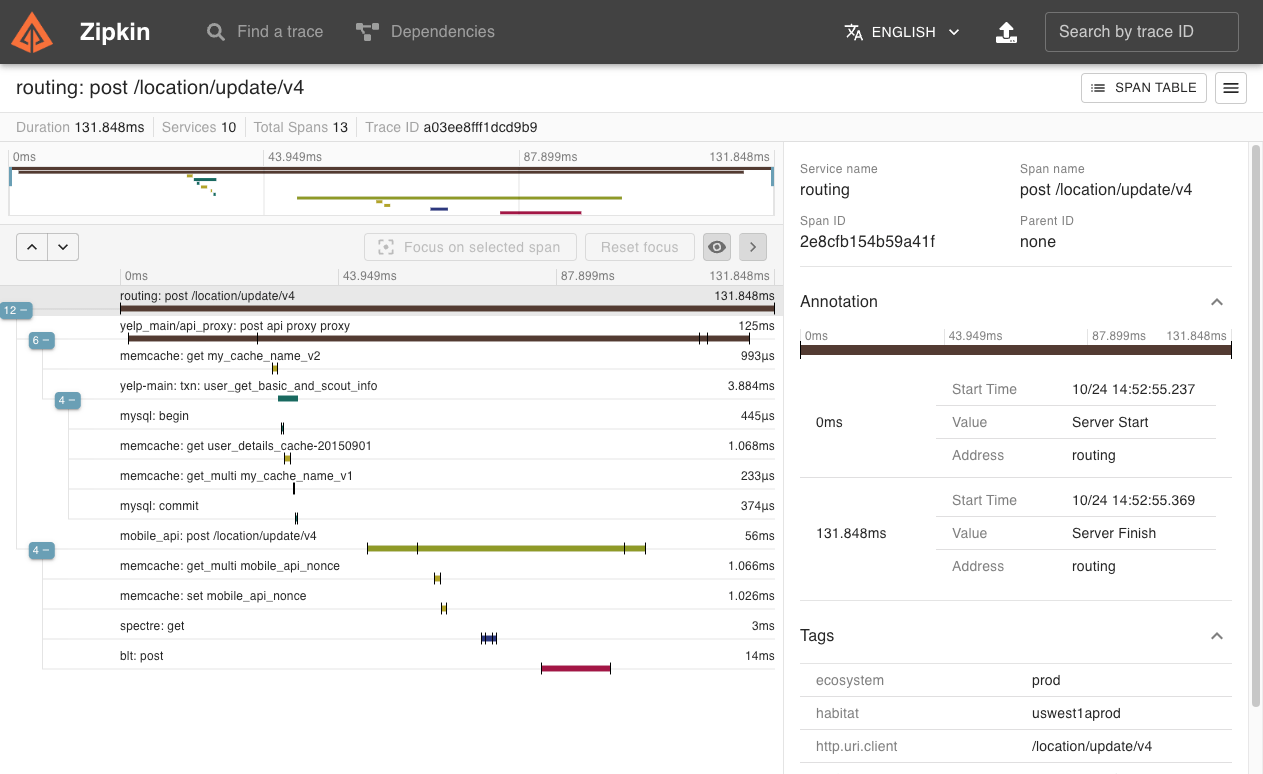
Интерфейс пользователя Zipkin также представляет собой диаграмму зависимостей, показывающую количество отслеживаемых запросов, прошедших через каждое приложение. Это может быть полезно для выявления совокупного поведения, включая пути ошибок или вызовы устаревших сервисов.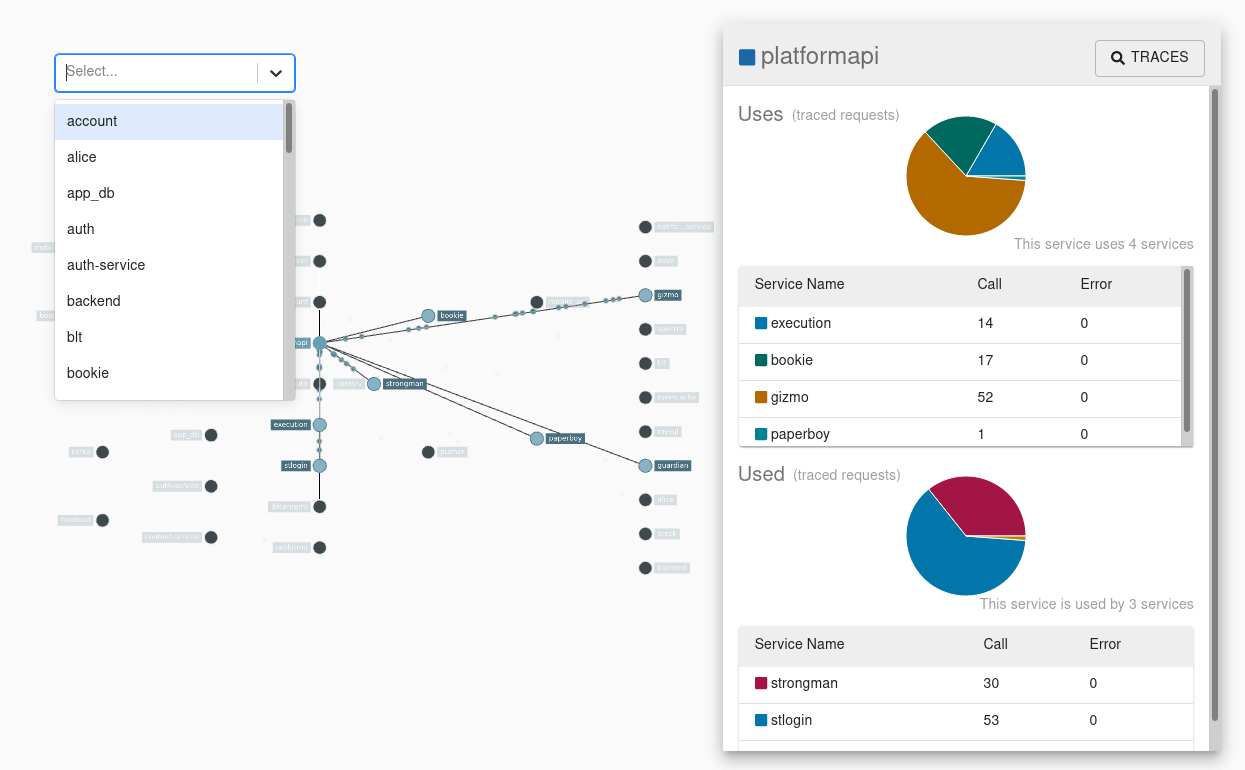
Приложения должны быть "настроены" для отправки данных трассировки в Zipkin. Обычно это означает конфигурирование трассера или библиотеки инструментирования. Самым популярным способом отправки данных в Zipkin является использование HTTP или Kafka, хотя существует множество других вариантов, таких как Apache ActiveMQ, gRPC, RabbitMQ и Apache Pulsar. Данные, предоставляемые интерфейсу пользователя, хранятся в памяти или в постоянном хранилище с поддержкой, таким как Apache Cassandra или Elasticsearch.
Наиболее быстрый способ начать работу — это получить последнюю выпущенную версию сервера zipkin-server в виде самодостаточного исполняемого jar-файла. Учитывайте, что сервер Zipkin требует минимальной версии JRE 17+. Например:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
Вы также можете запустить Zipkin с помощью Docker.
# Примечание: это зеркало доступно по адресу ghcr.io/openzipkin/zipkin
docker run -d -p 9411:9411 openzipkin/zipkin
Как только сервер начнет работу, вы сможете просматривать трассировки через интерфейс Zipkin по адресу http://localhost:9411/zipkin.
Если ваши приложения еще не отправляют трассировки, настройте их с использованием инструментирования Zipkin или попробуйте один из наших примеров.См. документацию по конфигурации в разделе zipkin-server или примеры использования Docker.
Урезанная версия Zipkin меньше по размеру и быстрее запускается. Она поддерживает хранение данных в памяти и Elasticsearch, но не поддерживает транспорты сообщений, такие как Kafka или RabbitMQ. Если эти ограничения соответствуют вашим потребностям, вы можете использовать урезанную версию следующим образом:
Запуск через Java:
curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin:zipkin-server:LATEST:slim zipkin.jar
java -jar zipkin.jar
Запуск через Docker:
# Примечание: это зеркало доступно по адресу ghcr.io/openzipkin/zipkin-slim
docker run -d -p bk 9411:9411 openzipkin/zipkin-slim
Запуск через Homebrew:
brew install zipkin
# чтобы запустить в фоновом режиме
zipkin
# чтобы запустить в фоновом режиме
brew services start zipkin
Основная библиотека используется как для инструментирования Zipkin, так и для сервера Zipkin.
Это включает встроенные кодеки для форматов JSON версий 1 и 2 Zipkin. Непосредственная зависимость от gson (библиотеки для работы с JSON) избегается путем минификации и переупаковки используемых классов. В результате получается JAR-файл объемом 155 КБ, который не будет конфликтовать с любой другой библиотекой, которую вы используете.Пример:
// Все данные записываются относительно одного конечного пункта, связанного с вашей службой
localEndpoint = Endpoint.newBuilder().serviceName("tweetie").ip("192.168.0.1").build();
span = Span.newBuilder()
.traceId("d3d200866a77cc59")
.id("d3d200866a77cc59")
.name("targz")
.localEndpoint(localEndpoint)
.timestamp(epochMicros())
.duration(durationInMicros)
.putTag("compression.level", "9");
// Теперь вы можете закодировать его в JSON
bytes = SpanBytesEncoder.JSON_V2.encode(span);
Примечание: В приведённом выше примере вероятнее всего вы захотите использовать существующую библиотеку трассировки, такую как Brave.
Минимальный уровень языка Java для основной библиотеки — 8. Это помогает поддерживать тех, кто пишет агентскую инструментацию. Версия 2.x была последней, поддерживающей Java 6.
Примечание: zipkin-reporter-brave не использует эту библиотеку. Поэтому brave всё ещё поддерживает Java 6.
Zipkin включает компонент StorageComponent, который используется для хранения и запроса трейсов и связей зависимости. Этот компонент используется сервером и теми, кто создаёт собирающие данные компоненты или отчёты о трейсах. По этой причине компоненты хранения имеют минимальные зависимости, хотя требуют Java 17+.Пример:
// Это не создаст сетевые соединения
storage = ElasticsearchStorage.newBuilder()
.hosts(Arrays.asList("http://myelastic:9200")).build();
// Подготовьте вызов
traceCall = storage.spanStore().getTrace("d3d200866a77cc59");
// Выполните его синхронно или асинхронно
trace = traceCall.execute();
// Освободите любые сессии и т.д.
storage.close();
Компонент InMemoryStorage упакован в основную библиотеку Zipkin. Он не является постоянным и не предназначен для работы под высокими нагрузками. Его цель — тестирование, например запуск сервера на вашем ноутбуке без необходимости использования базы данных.
Компонент Cassandra использует возможности Cassandra 3.11.3+ и проверяется против последнего патча Cassandra 4.1.
Это второе поколение нашей схемы Cassandra. Она хранит трейсы с использованием UDTs, поэтому они выглядят как Zipkin v2 json в cqlsh. Она предназначена для масштабируемости и использует сочетание SASI и вручной реализованных индексов для повышения производительности при запросе больших объемов данных.
Примечание: Эта система хранения требует задачи для агрегации зависимостей.### Elasticsearch Компонент Elasticsearch использует возможности Elasticsearch 5+ и проверяется против Elasticsearch 7–8.x и OpenSearch 2.x. Он хранит отрезки в виде Zipkin v2 JSON, чтобы обеспечить простую интеграцию с другими инструментами. Для масштабируемости используется сочетание пользовательских и вручную реализованных индексов.Примечание: Это хранилище требует выполнения задачи Spark для агрегации зависимых ссылок.
Следующие конечные точки API предоставляют возможности поиска и включены по умолчанию. Поиск позволяет главному экрану просмотра трассировки работать корректно.
GET /services — Уникальные значения Span.localServiceNameGET /remoteServices?serviceName=X — Уникальные значения Span.remoteServiceName по Span.localServiceNameGET /spans?serviceName=X — Уникальные значения Span.name по Span.localServiceNameGET /autocompleteKeys — Уникальные ключи Span.tags, подчинённые настраиваемому белому спискуGET /autocompleteValues?key=X — Уникальные значения Span.tags по ключуGET /traces — Трассировки, соответствующие запросу, возможно, включающие вышеупомянутые критерииКогда поиск отключен, трассировки могут быть получены только по идентификатору (GET /trace/{traceId}). Отключение поиска является допустимым только при наличии альтернативного способа получения идентификаторов трассировки, таких как журналы. Отключение поиска может снизить затраты на хранение данных или увеличить пропускную способность записи.
StorageComponent.Builder.searchEnabled(false) подразумевается при запуске Zipkin с переменной окружения SEARCH_ENABLED=false.### Устаревшие (v1) компоненты
Следующие компоненты больше не рекомендуются, но остаются для помощи при переходе на поддерживаемые версии. Эти компоненты помечаются как "v1", поскольку они используют модели данных на основе Zipkin V1 Thrift, а не более простую модель данных v2.#### MySQL
Компонент MySQL v1 использует функции MySQL 5.6+, но тестируется против MariaDB 10.11.
Схема была спроектирована для удобства понимания и быстрого старта; она не предназначена для высокой производительности. Элементы span являются столбцами, поэтому вы можете выполнять произвольные запросы с помощью SQL. Однако этот компонент имеет известные проблемы с производительностью: запросы со временем будут занимать несколько секунд для возврата, если вы поместите большое количество данных.
Это хранилище не требует выполнения задачи для агрегации зависимых ссылок. Однако выполнение задачи улучшит производительность запросов зависимостей.
Сервер Zipkin принимает трассировки через HTTP POST и отвечает на запросы от его веб-интерфейса. Он также может запускать сборщики данных, такие как RabbitMQ или Kafka.
Чтобы запустить сервер из текущих исходников, выполните следующие команды. Для компиляции требуется JDK версии 17+.
# Сборка сервера и его зависимостей
$ ./mvnw -q --batch-mode -DskipTests --also-make -pl zipkin-server clean install
# Запуск сервера
$ java -jar ./zipkin-server/target/zipkin-server-*exec.jar
Артефакты сервера находятся в группе Maven io.zipkin.
Библиотечные артефакты находятся в группе Maven io.zipkin.zipkin2.### Выпуски библиотек
Выпуски доступны на Sonatype и Maven Central.
Предварительные выпуски загружаются на Sonatype после внесения изменений в ветку master.
Открытые версии zipkin-server публикуются на Docker Hub как openzipkin/zipkin и GitHub Container Registry как ghcr.io/openzipkin/zipkin. Подробнее см. раздел docker.
Графики Helm доступны через helm repo add zipkin https://zipkin.io/zipkin-helm. Подробнее см. раздел zipkin-helm.
https://zipkin.io/zipkin содержит версионированные папки с Javadoc, опубликованные при каждом (не PR) билде, а также при выпусках.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )