Слияние кода завершено, страница обновится автоматически
Crawlab
![]()






中文 | English
Installation | Run | Screenshot | Architecture | Integration | Compare | Community & Sponsorship | CHANGELOG | Disclaimer
Golang-based распределённая платформа управления веб-краулерами, поддерживающая различные языки, включая Python, NodeJS, Go, Java, PHP и различные фреймворки веб-краулеров, такие как Scrapy, Puppeteer, Selenium.
Три метода:
Откройте командную строку и выполните команду ниже. Убедитесь, что вы заранее установили docker-compose.
git clone https://github.com/crawlab-team/crawlab
cd crawlab
docker-compose up -d
Далее вы можете ознакомиться с файлом docker-compose.yml (с подробными параметрами конфигурации) и документацией (на китайском языке).
Используйте docker-compose, чтобы запустить одним щелчком мыши. Таким образом, вам даже не придётся настраивать базы данных MongoDB и Redis. Создайте файл с именем docker-compose.yml и введите код ниже.
version: '3.3'
services:
master:
image: tikazyq/crawlab:latest
container_name: master
environment:
CRAWLAB_SERVER_MASTER: "Y"
CRAWLAB_MONGO_HOST: "mongo"
CRAWLAB_REDIS_ADDRESS: "redis"
ports:
- "8080:8080"
depends_on:
- mongo
- redis
mongo:
image: mongo:latest
restart: always
ports:
- "27017:27017"
redis:
image: redis:latest
restart: always
ports:
- "6379:6379"
Затем выполните команду ниже, и главный узел Crawlab + MongoDB + Redis запустится. Откройте браузер и введите http://localhost:8080, чтобы увидеть интерфейс UI.
docker-compose up
Для получения подробной информации о развёртывании Docker обратитесь к соответствующей документации. ### Домашняя страница
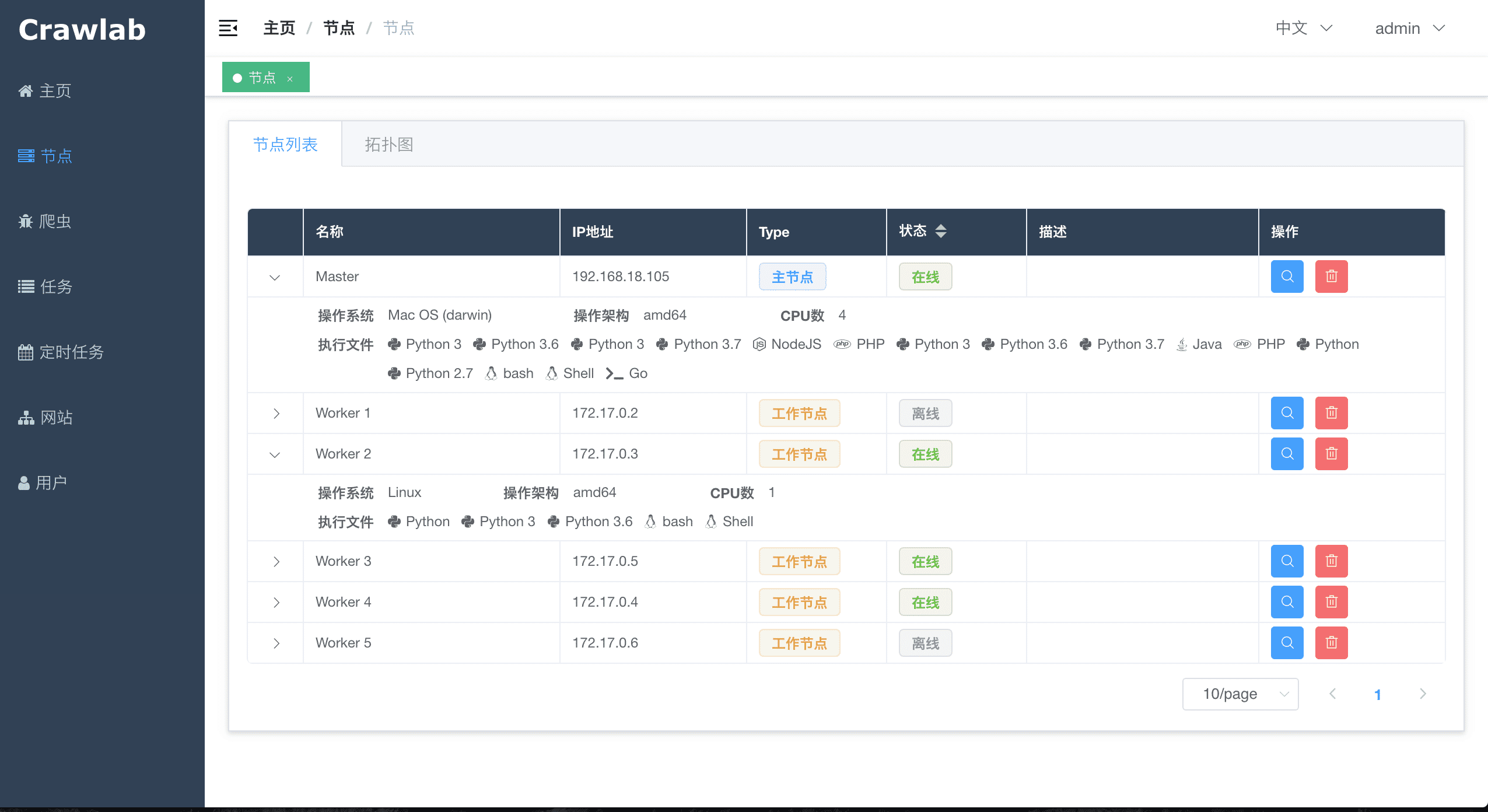
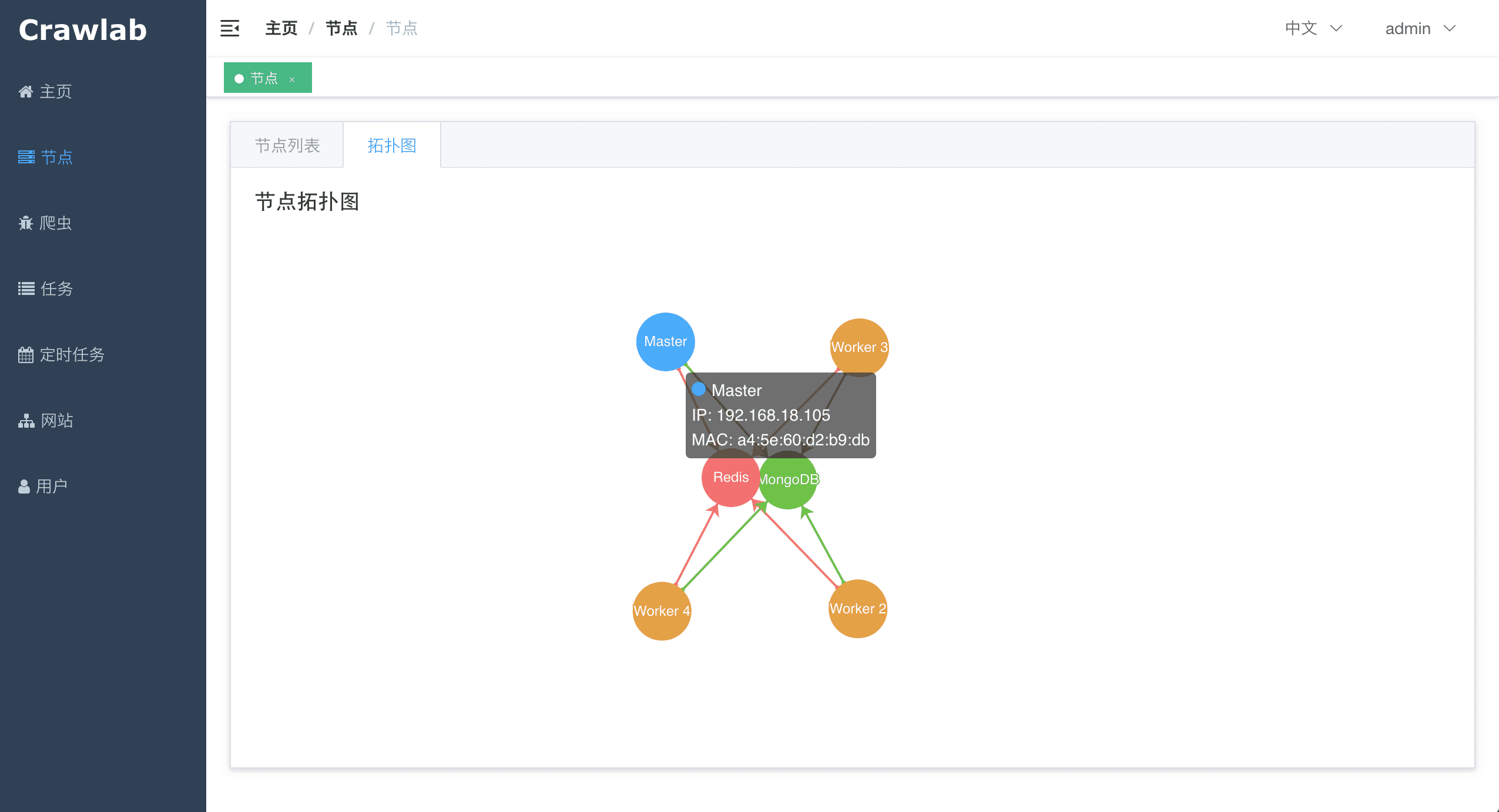
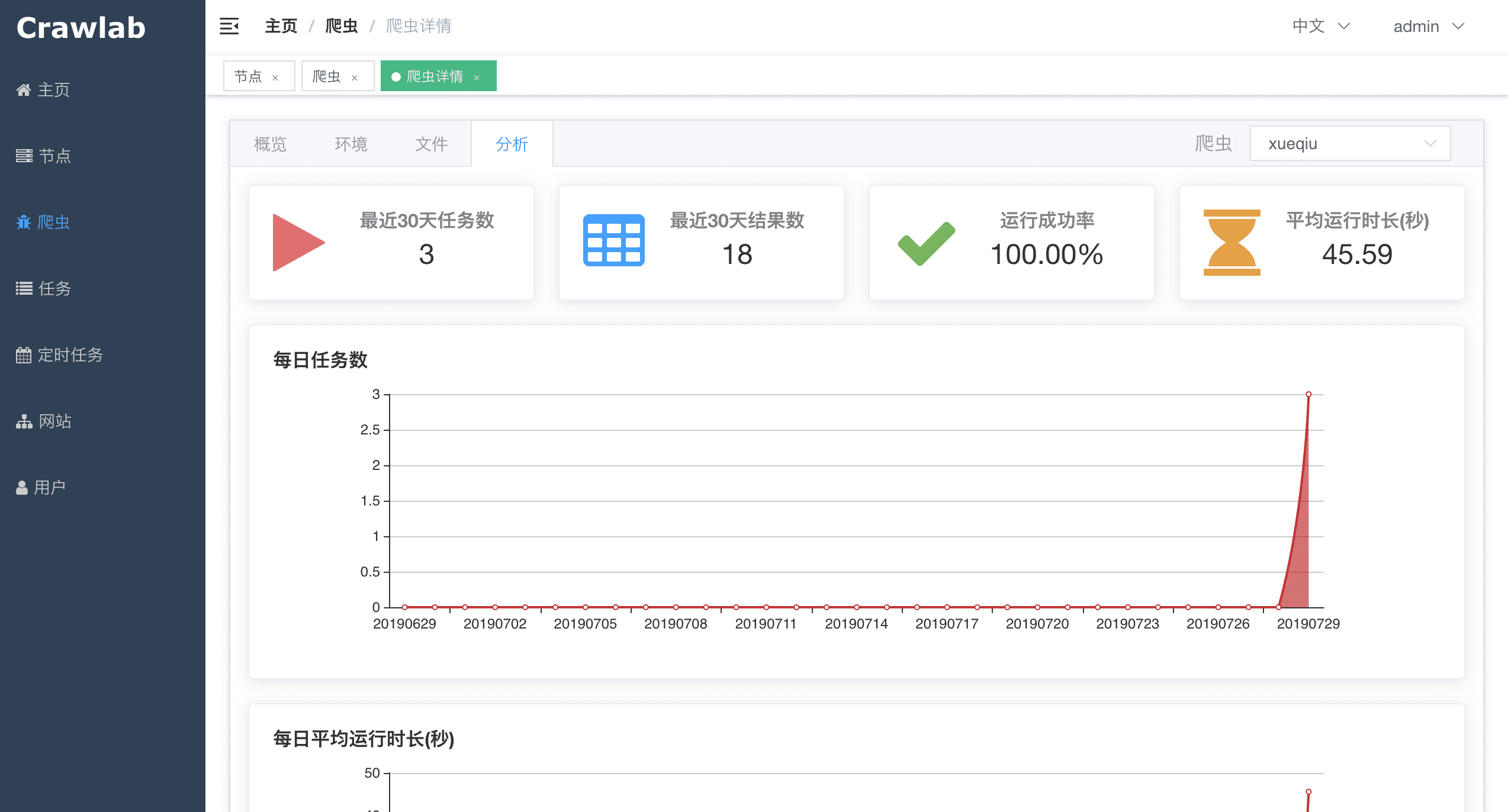


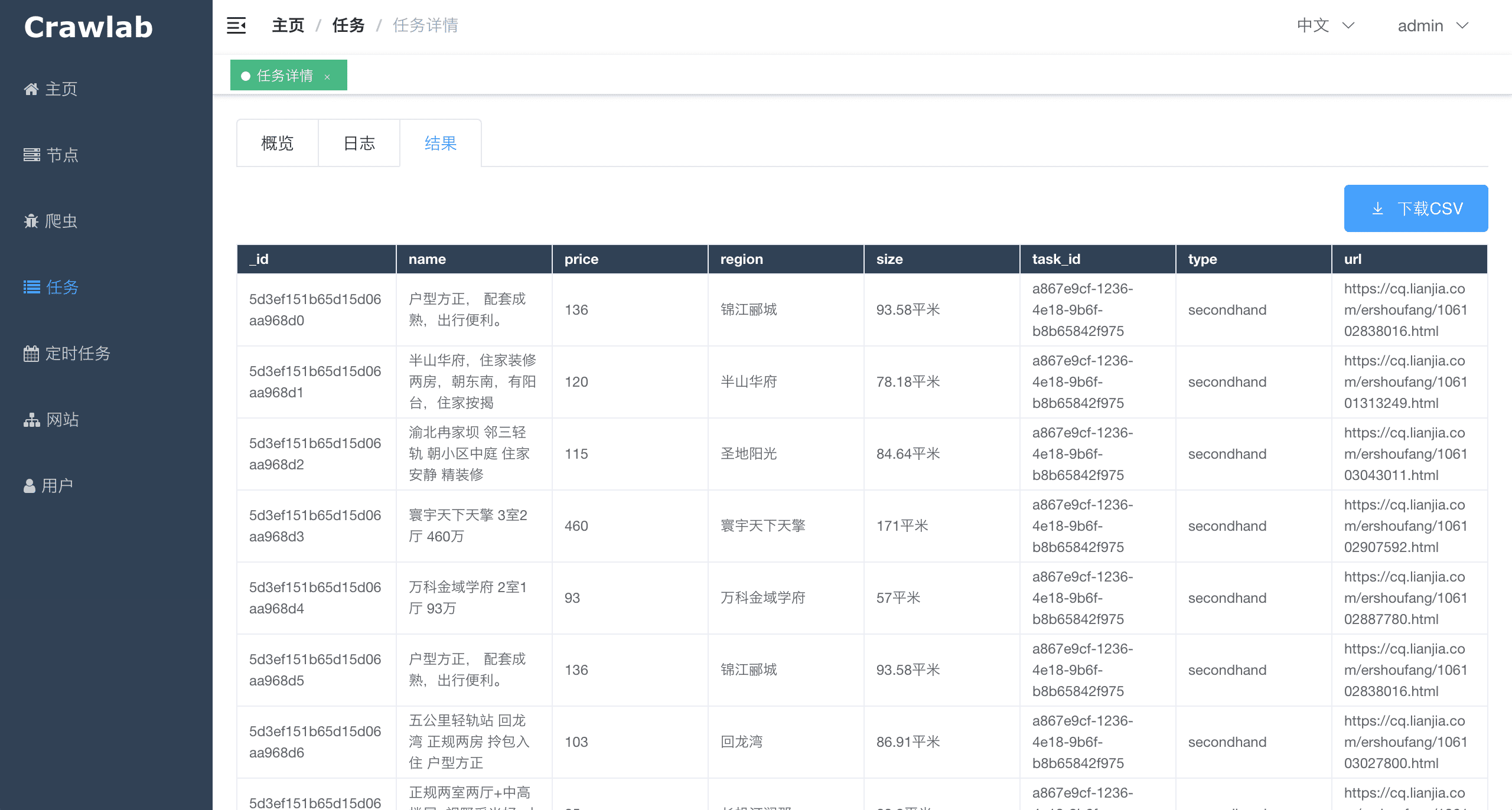




Архитектура Crawlab состоит из главного узла и множества рабочих узлов, а также баз данных Redis и MongoDB, которые в основном предназначены для связи между узлами и хранения данных.

Приложение внешнего интерфейса отправляет запросы главному узлу, который назначает задачи и развёртывает пауков через MongoDB и Redis. Когда рабочий узел получает задачу, он начинает выполнять задачу сканирования, и сохраняет результаты в MongoDB. Архитектура гораздо более лаконична по сравнению с версиями до v0.3.0. Из неё был удалён ненужный модуль Flower, который предлагал услуги мониторинга узлов. Теперь они выполняются Redis.
Главный узел является ядром архитектуры Crawlab. Это центральная система управления Crawlab.
Главный узел предлагает следующие услуги:
Главный узел взаимодействует с приложением внешнего интерфейса и отправляет задачи сканирования рабочим узлам. В то же время главный узел синхронизирует (развёртывает) пауков на рабочие узлы через Redis и MongoDB GridFS.
Основная функция рабочих узлов — выполнение задач сканирования и сохранение результатов и журналов, а также взаимодействие с главным узлом через Redis PubSub. Увеличивая количество рабочих узлов, Crawlab может масштабироваться горизонтально, и разные задачи сканирования могут быть назначены разным узлам для выполнения.
MongoDB — это операционная база данных Crawlab. Она хранит данные об узлах, пауках, задачах, расписаниях и т. д. Файловая система MongoDB GridFS является средством, с помощью которого главный узел сохраняет файлы пауков и синхронизируется с рабочими узлами.
Redis — очень популярная база данных типа «ключ-значение». Он предлагает услуги связи между узлами в Crawlab. Например, узлы будут выполнять HSET, чтобы установить свою информацию в хэш-список с именем nodes в Redis, и главный узел будет идентифицировать онлайн-узлы в соответствии с хэш-списком.
Внешний интерфейс представляет собой SPA на основе Vue-Element-Admin. Он повторно использовал многие компоненты Element-UI для поддержки соответствующего отображения.
Crawlab SDK предоставляет некоторые вспомогательные методы, которые упрощают интеграцию ваших пауков в Crawlab, например, сохранение результатов.
⚠️Примечание: убедитесь, что вы уже установили crawlab-sdk с помощью pip.
В settings.py в вашем проекте Scrapy найдите переменную с именем ITEM_PIPELINES (переменная dict). Добавьте содержимое ниже. ### Общий паук Python
Добавьте приведённый ниже контент в файлы пауков, чтобы сохранить результаты.
# импортируем метод сохранения результатов
from crawlab import save_item
# это запись результата, должна быть типа dict
result = {'name': 'crawlab'}
# вызываем метод сохранения результата
save_item(result)
Затем запустите паука. После того как он завершит работу, вы сможете увидеть результаты парсинга в разделе Задача детализации -> Результат
Задача сканирования фактически выполняется через командную строку. Идентификатор задачи будет передан процессу задачи сканирования в виде переменной среды с именем CRAWLAB_TASK_ID. Таким образом, данные можно связать с задачей. Кроме того, другая переменная среды CRAWLAB_COLLECTION передаётся Crawlab в качестве имени коллекции для хранения данных результатов.
Существуют существующие платформы управления пауками. Зачем использовать Crawlab?
Причина в том, что большинство существующих платформ зависят от Scrapyd, который ограничивает выбор только Python и Scrapy. Конечно, Scrapy — отличный фреймворк для веб-сканирования, но он не может делать всё.
Crawlab прост в использовании, достаточно универсален, чтобы адаптировать пауков на любом языке и в любой среде. У него также есть красивый интерфейс для пользователей, позволяющий гораздо проще управлять пауками.
| Фреймворк | Технология | Плюсы | Минусы | Статистика Github |
|---|---|---|---|---|
| Crawlab | Golang + Vue | Не ограничивается Scrapy, доступен для всех языков программирования и фреймворков. Красивый интерфейс UI. Естественно поддерживает распределённых пауков. Поддерживает управление пауками, управление задачами, cron job, экспорт результатов, аналитику, уведомления, настраиваемые пауки, онлайн-редактор кода и т. д. | Пока не поддерживает управление версиями пауков |
 
|
| ScrapydWeb | Python Flask + Vue | Красивый интерфейс UI, встроенный анализатор журналов Scrapy, статистика и графики выполнения задач, поддержка управления узлами, cron job, уведомление по почте, мобильное приложение. Полнофункциональная платформа управления пауками. | Не поддерживает пауков кроме Scrapy. Ограниченная производительность из-за бэкенда Python Flask. |
 
|
| Gerapy | Python Django + Vue | Gerapy создан гуру веб-краулеров Germey Cui. Простая установка и развёртывание. Красивый интерфейс UI. Поддержка управления узлами, редактирования кода, настраиваемых правил сканирования и т.д. | Опять же не поддерживает пауков кроме Scrapy. Множество ошибок на основе отзывов пользователей в версии 1.0. С нетерпением ждём улучшения в версии 2.0 |
 
|
| SpiderKeeper | Python Flask | Открытый исходный код Scrapyhub. Краткий и простой интерфейс UI. Поддерживает cron job. | Возможно, слишком упрощён, не поддерживает разбиение на страницы, не поддерживает управление узлами, не поддерживает пауков кроме Scrapy. |
 
|




 ## Сообщество и спонсорская поддержка
## Сообщество и спонсорская поддержка
Если вы считаете, что Crawlab может быть полезен в вашей повседневной работе или в компании, пожалуйста, добавьте автора в Wechat, отметив «Crawlab», чтобы присоединиться к группе обсуждения. Или отсканируйте QR-код Alipay ниже, чтобы вознаградить нас и помочь улучшить наше командное программное обеспечение или купить кофе.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )