Слияние кода завершено, страница обновится автоматически
Как следует из названия, этот метод представляет собой простое циклическое распределение запросов между серверами, расположенными в конце цепочки.
Каждый входящий запрос из сети последовательно направляется к серверам, начиная с 1 до N, после чего процесс начинается заново. Этот алгоритм подходит для случаев, когда все серверы имеют одинаковое программное и аппаратное обеспечение, а также равномерно распределены по количеству обслуживаемых запросов.
На основе различных вычислительных возможностей каждого сервера, каждому серверу присваивается определенный вес, который определяет количество запросов, которое он может обрабатывать. Например, если вес сервера A составляет 1, B — 3, а C — 6, то серверы A, B и C будут получать соответственно 10%, 30% и 60% всех запросов. Этот алгоритм позволяет более эффективно использовать высокопроизводительные серверы, избегая перегрузки менее мощных серверов.
Как следует из названия, этот алгоритм заключается в случайном выборе сервера из конечной группы для обработки каждого входящего запроса.
Этот алгоритм похож на весовую циклическую балансировку, но при распределении запросов используется случайный выбор.### 5. Балансировка по времени отклика (Response Time)
Устройство балансировки нагрузки отправляет каждый серверу в группе запрос на проверку (например, Ping) и затем направляет запрос клиента к тому серверу, который ответил быстрее всего. Этот алгоритм лучше всего отражает текущее состояние работы сервера, однако время отклика определяется только временем ответа устройства балансировки нагрузки, а не клиента.
Этот алгоритм направляет запрос к тому серверу, где число активных соединений минимально. Поскольку код для определения числа соединений сложен, его здесь не приведено. Основная идея заключается в том, чтобы циклически пройтись по списку серверов и выбрать тот, у которого число соединений минимально.
Этот алгоритм распределяет запросы между серверами, основываясь на их способности обрабатывать нагрузку (учитываются модель процессора, количество процессоров, объем оперативной памяти и текущее число соединений). Так как этот алгоритм учитывает производительность серверов и текущее состояние сети, он является наиболее точным и особенно полезен для балансировки нагрузки на уровне приложений (седьмом уровне модели OSI).
Консистентный хэш (Consistent Hash) гарантирует, что запросы с одинаковыми параметрами всегда направляются к одному и тому же поставщику. При отказе одного из поставщиков, запросы, которые ранее направлялись к этому поставщику, распределяются между другими поставщиками с помощью виртуальных узлов, что позволяет избежать резких колебаний.
Алгоритм, который использует хэширование информации URL-запросов клиента для направления запросов к одному и тому же серверу, если они имеют одинаковый URL.
Короткое соединение — это соединение, которое поддерживается только во время передачи данных. Соединение создается при запуске запроса, данные возвращаются после завершения запроса, а затем соединение закрывается. Это подходящий вариант для запросов реального времени, особенно когда используется опрос для обновления старых и новых данных.
Чтобы решить проблемы, возникающие при использовании TCP-соединений, HTTP/1.1 и некоторые реализации HTTP/1.0 используют метод долгого соединения (Persistent Connections, также известный как HTTP Keep-Alive или HTTP Connection Reuse). Основная особенность долгого соединения состоит в том, что оно поддерживается до тех пор, пока ни одна из сторон не явно не закроет его.Преимущества долгого соединения включают снижение затрат на повторное создание и закрытие TCP-соединений, что снижает нагрузку на сервер. Кроме того, время, затраченное на снижение этих затрат, позволяет завершить HTTP-запросы и ответы быстрее, что ускоряет отображение веб-страниц. По умолчанию все соединения являются долгими в HTTP/1.1, но это не является стандартом для HTTP/1.0. Хотя некоторые серверы поддерживают долгие соединения через нестандартные методы, сервер может не поддерживать их. Безусловно, кроме сервера, клиент также должен поддерживать долгие соединения.
Формула: key mod x (x — натуральное число) Ключ может быть первичным ключом, номером заказа или ID пользователя, что зависит от сценария. В качестве ключа выбирается тот параметр, который чаще всего используется в запросах.
Преимущества: Позволяет по мере необходимости добавлять новые базы данных и таблицы Равномерное распределение данных, различия между частями минимальны
Недостатки: Часто начинают с разделения на две базы данных, затем постепенно увеличивают количество. При переходе, например, от mod 3 к mod 5, большинство данных будут перераспределены. Например, при key = 3, mod 3 = 0, а при переходе к mod 5 = 3, данные переместятся из первой базы данных в третью, что приведет к множественным перемещениям данных.
При каждом изменении количества баз данных данные будут повторно перемещаться. Например, если сначала было две базы данных, а затем добавлена третья, данные могут переместиться из первой базы данных во вторую, а затем вернуться в первую при добавлении четвертой базы данных.
Этот алгоритм требует добавления года, месяца и дня или временной метки к номеру заказа или ID пользователя, либо передачи этих данных через интерфейс запроса, чтобы определить, в какой шарде находятся данные.Преимущества: Данные расположены по времени последовательно. Просто анализировать рост данных.
Недостатки: При работе с историческими данными, которые были созданы до разделения баз данных, требуется наличие временной метки. Однако, исторические данные могут иметь автоинкрементные ключи или ключи, сгенерированные другими алгоритмами. Это означает, что для выполнения запросов необходимо передавать номер заказа и время создания вместе.
Если временная метка не передана, или если временная метка в системе-источнике отличается от временной метки в текущей системе, то в базе данных должны храниться временные метки. Это требует наличия основной таблицы для хранения связи между номерами заказов и временем их создания, что усложняет процесс запросов.
Размещение данных может быть неравномерным: ежемесячный прирост данных может отличаться, что приводит к неравномерному распределению данных.
Таблица 0 [0,10000000)
Таблица 1 [10000000,20000000)
Таблица 2 [20000000,30000000)
Таблица 3 [30000000,40000000)
...
Преимущества: Равномерное распределение данных.Недостатки: Необходимость знать максимальное значение для использования временной метки как ключа. Этот метод не позволяет использовать автоинкрементные ключи, так как каждый ключ будет уникален для каждой таблицы. Поэтому требуется наличие системы генерации ключей для обеспечения уникальности ключей.### Схема 4: Концепция Consistent Hash — сбалансированное распределение### Схема 5: Концепция Consistent Hash — добавление узлов по циклу
Наследование: HashMap наследует AbstractMap, Hashtable наследует Dictionary, ConcurrentHashMap наследует AbstractMap и реализует интерфейс ConcurrentMap.
Потокобезопасность: HashMap не потокобезопасна, а Hashtable и ConcurrentHashMap потокобезопасны. Однако механизмы обеспечения потокобезопасности различаются: Hashtable использует synchronized для синхронизации методов, в то время как ConcurrentHashMap снижает гранулу блокировки, что позволяет достичь лучшей производительности при параллельной работе.
Значения ключей и значений: В Hashtable и ConcurrentHashMap значения ключей и значений не могут быть null, в то время как в HashMap значение ключа может быть null, но только одно, а значений — любое количество.
Алгоритмы хеширования: Алгоритмы хеширования в HashMap и ConcurrentHashMap (в JDK 8) одинаковы и используют XOR высокого и низкого 16-битного хеш-значения ключа, а затем берут остаток от деления на длину массива. В Hashtable используется прямое деление на остаток от хеш-значения ключа.
Механизмы увеличения размера: Механизмы увеличения размера в ConcurrentHashMap и HashMap одинаковы: размер увеличивается вдвое относительно текущего размера массива, начальный размер равен 16. В Hashtable начальный размер равен 11, а увеличение происходит до двух раз от текущего размера плюс один.Механизмы обработки ошибок: ConcurrentHashMap поддерживает безопасное завершение, в то время как HashMap и Hashtable поддерживают быстрое завершение.
Методы поиска: В HashMap нет метода contains, но есть методы containsKey и containsValue. В Hashtable и ConcurrentHashMap есть метод contains.
Способы итерации: В Hashtable и ConcurrentHashMap есть способ итерации Enumeration.
Потокобезопасность: Нет, все методы не защищены блокировками, что обеспечивает максимальную производительность.
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Увеличивает modCount!!
elementData[size++] = e;
return true;
}
Потокобезопасность: Да, все методы защищены блокировками, что обеспечивает минимальную производительность (методы содержат логику обработки).
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}
Чтение, запись и удаление защищены блокировками, но блокировки применяются к конкретным операциям, а не к методам, что обеспечивает хорошую производительность. Итерация не защищена блокировками, поэтому можно самостоятельно решить, когда применять блокировки в зависимости от бизнес-требований.
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
public int indexOf(Object o) {
synchronized (mutex) {return list.indexOf(o);}
}
``````java
public int lastIndexOf(Object o) {
synchronized (mutex) { return list.lastIndexOf(o); }
}
public boolean addAll(int index, Collection<? extends E> c) {
synchronized (mutex) { return list.addAll(index, c); }
}
public ListIterator<E> listIterator() {
return list.listIterator(); // Должна быть ручная синхронизация пользователя
}
public ListIterator<E> listIterator(int index) {
return list.listIterator(index); // Должна быть ручная синхронизация пользователя
}
Чтение не защищено блокировками, запись использует CAS-блокировку, которая выполняется в цикле (спинлок). При записи создается копия исходного массива, который затем модифицируется, и новая версия массива заменяет старую (при большом размере массива это может привести к низкой производительности). Избыточное количество конкурирующих операций и коллизий CAS также могут влиять на производительность. Чтение данных происходит из исходного массива, поэтому если метод add еще не завершил выполнение метода setArray, то считанные данные будут представлять собой старые данные.
// Пример метода add
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = array;
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
array = newElements;
return true;
} finally {
lock.unlock();
}
}
Описание:Кэш апокалипсис — это ситуация, когда большая часть данных в кэше истекает срок действия, при этом количество запросов очень велико, что приводит к чрезмерной нагрузке на базу данных и может вызвать её отказ. В отличие от кэш пробоя, кэш апокалипсис происходит, когда разные данные истекают срок действия, и многие данные становятся недоступными, что приводит к необходимости обращаться к базе данных.Решение:
Установите случайные сроки действия для данных кэша, чтобы предотвратить ситуацию, когда большая часть данных истекает срок действия одновременно.
Если кэш и база данных распределены, распределите горячие данные равномерно между различными кэшами.
Установите горячие данные как вечные, чтобы они никогда не истекали срок действия.
Описание:
Кэш пробой — это ситуация, когда данные отсутствуют как в кэше, так и в базе данных, и пользователи продолжают отправлять запросы, например, за id "-1" или за очень большим id, который не существует. В этом случае пользователь может быть атакующим, что приведёт к чрезмерной нагрузке на базу данных.
Решение:
Добавьте проверку на уровне интерфейса, например, проверку аутентификации пользователя, базовую проверку id, и отклоните запросы с id ≤ 0.
Если данные не найдены в кэше и в базе данных, можно временно записать ключ-значение как key-null, установив короткий срок действия кэша, например, 30 секунд. Это поможет предотвратить повторные атаки с использованием одного и того же id.
Описание:Кэш пробиваемость — это ситуация, когда данные отсутствуют в кэше, но присутствуют в базе данных (обычно это связано с истечением срока действия кэша), при этом большое количество конкурирующих пользователей одновременно обращаются к кэшу, не находят данные и обращаются к базе данных, что приводит к внезапному увеличению нагрузки на базу данных.Решение:
Установите горячие данные как вечные, чтобы они никогда не истекали срок действия.
Используйте мьютекс, пример кода для мьютекса представлен ниже:
Предварительная загрузка кэша — это процесс загрузки связанных данных кэша сразу после запуска системы. Это позволяет избежать ситуации, когда пользователь делает запрос, и система сначала обращается к базе данных, а затем кэширует данные. Пользователь получает доступ к уже предварительно загруженным данным кэша!
Обновление кэша включает в себя не только встроенные стратегии истечения срока действия кэша сервера (Redis предлагает 6 различных стратегий выбора), но также позволяет пользователям настраивать собственные стратегии удаления кэша в соответствии с конкретными бизнес-потребностями. Обычно используются две основные стратегии:
(1) Периодическое удаление просроченного кэша.
(2) При получении запроса от пользователя проверка того, является ли используемый кэш просроченным. Если да, то получение новых данных из нижележащей системы и обновление кэша.
В мире Java, чтобы получить уникальный идентификатор, первым делом приходит в голову UUID, так как он имеет глобальную уникальность. Может ли UUID использоваться в качестве распределённого ID? Ответ — да, но его использование не рекомендуется!
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
System.out.println(uuid);
}
Преимущества:
Недостатки:
База данных с использованием auto_increment может полностью выполнять роль распределённого ID. Для реализации этого требуется отдельный экземпляр MySQL для генерации ID, структура таблицы следующая:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
value CHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY (id)
) ENGINE=MyISAM;
INSERT INTO SEQUENCE_ID(value) VALUES ('values');
```Когда нам нужен новый ID, мы добавляем запись в таблицу и получаем её `primary key`. Однако этот метод имеет один серьёзный недостаток: при резком увеличении нагрузки MySQL сам становится бутылочной горлышком системы, что увеличивает риск использования его для реализации распределённых служб. Этот подход не рекомендуется!
**Преимущества:**
- Простая реализация, ID увеличивается последовательно, быстрый поиск по числовым значениям.
**Недостатки:**
- Одиночная база данных представляет риск сбоев, не может справиться с высокой конкуренцией запросов.
### 3) На основе кластера баз данных
Ранее мы говорили, что одиночная база данных неприемлема, поэтому проведём оптимизацию над этим методом, заменив его на режим работы с главным и вторичным узлами. Чтобы избежать ситуации, когда главный узел выходит из строя, можно использовать двойной главный режим кластера, то есть два экземпляра MySQL могут самостоятельно генерировать последовательные ID.
Таким образом, возникает проблема: оба экземпляра MySQL начинают сгенерировать ID с единицы. **Как избежать дублирования ID?**
**Решение:** Установка начального значения и шага увеличения
Для MySQL_1:
```sql
SET @@auto_increment_offset = 1; -- Начальное значение
SET @@auto_increment_increment = 2; -- Шаг
Для MySQL_2:
SET @@auto_increment_offset = 2; -- Начальное значение
SET @@auto_increment_increment = 2; -- Шаг
```Таким образом, последовательные ID для двух экземпляров MySQL будут следующими:
> 1, 3, 5, 7, 9
> 2, 4, 6, 8, 10
А если производительность кластера после расширения все еще не может справиться с высокой конкуренцией запросов, потребуется расширение кластера MySQL, добавление новых узлов. Это довольно сложная задача.

Согласно приведенному выше рисунку, горизонтальное расширение базы данных кластера помогает решить проблему нагрузки на одиночную базу данных, а также позволяет установить шаг увеличения ID в соответствии с количеством машин.
Добавление третьего экземпляра MySQL требует ручного изменения начального значения и шага для первых двух экземпляров MySQL. Начальное значение ID для третьего экземпляра должно быть установлено на значении, которое значительно превышает текущий максимальный ID, но это должно быть сделано до того, как ID первого и второго экземпляров достигнут этого значения, иначе произойдет дублирование ID. **В некоторых случаях может потребоваться остановить работу системы для выполнения этих изменений.**
**Преимущества:**
- Решает проблему одиночной базы данных.
**Недостатки:**
- Не способствует дальнейшему расширению, и фактическая нагрузка на одну базу данных остается большой, что делает невозможным удовлетворение высоких требований к конкуренции запросов.### 4) Redis
Redis также может быть использован для реализации этой функции, основываясь на использовании команды `incr` для обеспечения атомарного увеличения ID.
```sql
127.0.0.1:6379> SET seq_id 1 -- Инициализация ID с 1
OK
127.0.0.1:6379> INCR seq_id -- Увеличение на 1 и возврат нового значения
(integer) 2
При использовании Redis важно учитывать вопрос сохранения состояния Redis. Redis имеет два способа сохранения состояния — RDB и AOF.
RDB периодически делает снимок для персистентного хранения данных. Если последовательно увеличивать значение, но redis не успеет его сохранить вовремя, а затем Redis выключится, при перезапуске Redis могут возникнуть ситуации повторения ID.AOF сохраняет каждую запись в базу данных, поэтому даже если Redis выключился, повторение ID не произойдет. Однако из-за специфики команды INCR, перезапуск Redis может привести к длительной перезагрузке данных.Алгоритм SnowFlake — это открытый алгоритм генерации уникальных идентификаторов, разработанный Twitter. Основная идея заключается в использовании 64-битного числа типа long как глобального уникального идентификатора. Этот метод широко используется в распределённых системах, так как ID включают временные метки, что обеспечивает их последовательное увеличение. Подробное описание можно найти в коде ниже.
Данное изображение взято из интернета, если есть нарушение авторских прав, пожалуйста, сообщите об этом.
Snowflake генерирует ID типа Long, который занимает 8 байт, каждый байт содержит 8 бит, то есть всего 64 бита.
Структура ID Snowflake состоит из следующих частей: знак положительного числа (1 бит) + временная метка (41 бит) + идентификатор машины (10 бит) + идентификатор центра обработки данных (5 бит) + счётчик (12 бит), всего 64 бита.
long число имеет знаковый бит, который указывает на положительное или отрицательное значение. Для ID обычно используется положительное значение, поэтому этот бит всегда равен 0.(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69 лет.workId. Этот параметр можно настроить, используя комбинацию номера машины или центра обработки данных.(1) Высокая производительность и надёжность: генерация ID не зависит от базы данных и полностью происходит в оперативной памяти. (2) Большая емкость: каждую секунду можно сгенерировать миллионы уникальных ID. (3) Уникальное увеличение ID: при сохранении в базе данных эффективность индексации повышается.
Зависимость от согласованности системного времени: если системное время будет возвращено назад или изменено, это может привести к конфликтам идентификаторов или их повторению.
TinyID был разработан компанией Didi, GitHub адрес: https://github.com/didi/tinyid.
TinyID реализован на основе принципа сегментации номеров, аналогично Leaf, каждый сервис получает сегмент номеров (1000, 2000], (2000, 3000], (3000, 4000].
Структура идентификатора uid-generator:
рабочий идентификатор занимает 22 бита, время — 28 бит, последовательность — 13 бит. Важно отметить, что время измеряется в секундах, а не в миллисекундах, и рабочий идентификатор также отличается. При каждом перезапуске приложения потребляется новый рабочий идентификатор.
Leaf был разработан компанией Meituan, GitHub адрес: https://github.com/Meituan-Diya...
Leaf поддерживает как сегментный режим, так и режим Snowflake, что позволяет переключаться между ними.
GitHub: XiaoMi/chronos Chronos зависит от ZooKeeper, при запуске ChronosServer запускается Thrift сервер.
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT 'текущий максимальный идентификатор',
step int(20) NOT NULL COMMENT 'длина сегмента',
biz_type int(20) NOT NULL COMMENT 'тип бизнеса',
version int(20) NOT NULL COMMENT 'версия',
PRIMARY KEY (id)
)
`biz_type` представляет различные типы бизнеса.
`max_id` — текущий максимальный доступный идентификатор.
`step` — длина диапазона номеров.
`version` — оптимистический блокировщик, который обновляется каждый раз, чтобы гарантировать правильность данных при параллельном доступе.
| id | biz_type | max_id | step | version |
| ---- | -------- | ------ | ---- | ------- |
| 1 | 101 | 1000 | 2000 | 0 |
После того как этот диапазон ID будет использован, снова запрашивается новый диапазон ID в базе данных, выполняется операция `update` для поля `max_id`, `update max_id=max_id+step`. Успешное выполнение `update` указывает на успешное получение нового диапазона ID, новый диапазон ID имеет значение `(max_id, max_id+step]`.
```javascript
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = #{version} and biz_type = XXX
Из-за возможности одновременного использования несколькими бизнес-конечными точками, используется оптимистическая блокировка с помощью поля version для обновления. Этот способ генерации распределённых ID не сильно зависит от базы данных и не требует частого обращения к ней, что снижает нагрузку на базу данных.
В настоящее время большинство крупных сайтов и приложений распределены. В распределённых сценариях проблема согласованности данных всегда была важной темой. Распределённая теория CAP говорит, что "никакой распределённой системе нельзя одновременно обеспечивать согласованность (Consistency), доступность (Availability) и отказоустойчивость (Partition tolerance)". Поэтому многие системы должны делать выбор между этими тремя при проектировании. В большинстве сценариев интернет-технологий требуется жертвовать согласованностью ради высокой доступности системы, система часто должна обеспечивать лишь "конечную согласованность", если это конечное время находится в пределах допустимого для пользователя.
В многих сценариях для обеспечения конечной согласованности данных требуется множество технологических решений, таких как распределённые транзакции, распределённые блокировки и т. д. Иногда требуется гарантировать, что метод может быть выполнен только одним потоком в одно и то же время.
Блокировка на основе базы данных; Блокировка на основе кэша (Redis и т. д.); Блокировка на основе Zookeeper;
Несмотря на наличие этих трёх подходов, каждое решение должно выбираться в зависимости от конкретной ситуации бизнеса, среди них нет лучшего, есть только более подходящего!#### 1) Блокировка на основе базы данных
Основная идея реализации на основе базы данных заключается в следующем: создается таблица в базе данных, которая содержит поля, такие как имя метода, и создается уникальный индекс на поле имени метода. Чтобы выполнить какой-либо метод, используется имя этого метода для вставки данных в таблицу. Успешная вставка означает получение блокировки, после выполнения метода соответствующая строка данных удаляется из таблицы, освобождая блокировку.
(1) Создайте таблицу:
(2) Чтобы выполнить какой-либо метод, используйте имя этого метода для вставки данных в таблицу:
Поскольку мы добавили ограничение уникальности для method_name, если несколько запросов одновременно отправлены в базу данных, база данных гарантирует, что только один операция может быть успешной. Таким образом, можно считать, что поток, который выполнил операцию успешно, получил блокировку на этот метод и может выполнить его содержимое.
(3) Успешная вставка означает получение блокировки, после выполнения операции удалите соответствующую строку данных для освобождения блокировки:
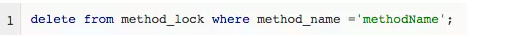
Поскольку блокировка реализуется с помощью базы данных, доступность и производительность базы данных будут напрямую влиять на доступность и производительность распределенной блокировки. Поэтому база данных должна быть установлена на двух машинах, данные должны быть синхронизированы, а также должна быть возможность переключения между основным и резервным серверами;
Блокировка не имеет свойства повторного захвата, поскольку при отсутствии освобождения блокировки одной и той же строкой данных она будет существовать до тех пор, пока блокировка не будет освобождена. Поэтому необходимо добавить новую колонку в таблицу для хранения информации о текущей машине и потоке, которые захватили блокировку. При повторном захвате блокировки следует сначала проверить информацию о машине и потоке в таблице, и если они совпадают, блокировка должна быть захвачена.3. Отсутствие механизма истечения срока действия блокировки, поскольку возможно, что после успешной вставки данных сервер выйдет из строя, и соответствующие данные не будут удалены. В этом случае, когда сервис восстановится, он не сможет получить блокировку. Поэтому необходимо добавить новую колонку в таблицу для хранения времени истечения срока действия и иметь задачу планировщика для очистки этих устаревших данных;4. Отсутствие свойства блокировки с возможностью блокировки, поскольку при невозможности получения блокировки сразу возвращается сообщение об ошибке. Поэтому необходимо оптимизировать логику получения блокировки, повторяя попытки получения блокировки несколько раз;
В процессе реализации могут возникнуть различные проблемы, и для решения этих проблем способ реализации будет становиться всё более сложным. Зависимость от базы данных требует определённых ресурсов, и вопрос производительности также должен быть учтён.
В отличие от реализации распределённой блокировки на основе базы данных, реализация на основе кэша будет проявлять лучшую производительность. Кроме того, многие кэши могут быть установлены в кластере, что позволяет решить проблему одного узла. Существует множество成熟的缓存产品,包括Redis、memcached和我们公司的内部产品Tair。
(1)Redis имеет высокую производительность; (2)Команды Redis хорошо поддерживают это, что делает реализацию удобной
(1)SETNX: SETNX key val — когда ключ отсутствует, устанавливает строку с ключом key и значением val, возвращая Yöntem 1: SETNX key val — Eger anahtar yoksa, key anahtarı ve val değerini içeren bir dize ayarlar ve 1 döndürür; eğer anahtar varsa, hiçbir şey yapmaz ve 0 döner.(2) expire: expire key timeout — устанавливает временную метку для ключа key, измеряемую в секундах, после которой ключ будет автоматически освобожден, что предотвращает проблемы.(3)delete: delete key — удаляет ключ key
При использовании Redis для реализации распределённых блокировок: Основные команды, которые используются:
(1)При получении блока, используйте setnx для блокировки и добавьте временный срок действия для блока с помощью команды expire, чтобы блок был автоматически освобожден после истечения времени. Значение блока представляет собой случайно сгенерированный UUID, который используется для проверки при освобождении блока.
(2)Установите время ожидания получения блока, если блок не получен за это время, прекратите попытки его получения.
(3)При освобождении блока, используйте UUID для проверки принадлежности блока, если это ваш блок, выполните команду delete для освобождения блока.
Zookeeper — это открытая система для обеспечения согласованности в распределённых приложениях, которая представляет собой структуру дерева каталогов. Внутри одного каталога могут существовать только уникальные имена файлов. Шаги для реализации распределённой блокировки на основе Zookeeper следующие:(1)Создайте каталог mylock; (2)Поток A хочет получить блокировку, создавая временный последовательный узел в каталоге mylock; (3)Получите все подузлы каталога mylock, затем получите узлы, меньшие текущего узла; если таких узлов нет, значит поток A имеет наименьший порядковый номер и получает блокировку; (4)Поток B получает все узлы, проверяет, является ли он наименьшим узлом; если нет, устанавливает слушателя для узла, следующего за ним; (5)Поток A завершает работу и удаляет свой узел, поток B получает событие изменения и проверяет, является ли он наименьшим узлом; если да, то получает блокировку.Здесь рекомендуется использовать библиотеку Apache Curator, которая является клиентом для Zookeeper, и InterProcessMutex, который предоставляет реализацию распределённой блокировки, метод acquire для получения блокировки, метод release для её освобождения.
Преимущества: обеспечивает высокую доступность, возможность повторного захвата, блокировку с возможностью блокировки, а также решение проблемы смертельного замыкания при отказе. Недостатки: из-за необходимости частого создания и удаления узлов, производительность ниже по сравнению с подходом Redis.
Класс Object расположен в пакете java.lang, который содержит самые базовые и центральные классы Java; этот пакет автоматически импортируется при компиляции;
Класс Object является предком всех Java-классов. Каждый класс использует Object как родительский класс. Все объекты (включая массивы) реализуют методы этого класса. Переменная типа Object может указывать на объект любого типа.
public final native Class<?> getClass(); // Возвращает класс, к которому принадлежит данный объект
public native int hashCode(); // Возвращает хэш-код данного объекта
private static native void registerNatives(); // Регистрация нативных методов
public boolean equals(Object obj); // Проверяет равенство данного объекта с другим объектом
protected native Object clone() throws CloneNotSupportedException; // Создает и возвращает копию данного объекта
``````markdown
## 11. Структура объекта в Java
В виртуальной машине HotSpot объекты в памяти могут быть разделены на три области:
**Заголовок объекта** (Header)
**Инстанцированные данные** (Instance Data)
**Область заполнения** (Padding)
Следующая диаграмма показывает структуру данных обычного объекта и массива:
.jpg)
Заголовок объекта состоит из следующих трёх частей:
1. **Mark Word**
2. Указатель на класс
3. [Длина массива](https://so.csdn.net/so/search?q=%u0434лина%20массива&spm=1001.2101.3001.7020) (только для объектов типа массив)
Mark Word содержит информацию о объектах и связанных с ними блоках, когда объект используется в качестве блока синхронизации ключевым словом `synchronized`. Вся информация, связанная с блоком синхронизации, хранится в Mark Word.
```Размер Mark Word составляет 32 бита в 32-битной JVM и 64 бита в 64-битной JVM.
Содержимое Mark Word различается в зависимости от состояния блока синхронизации:
В 32-битной JVM содержимое Mark Word выглядит следующим образом:
JVM обычно использует блоки синхронизации и Mark Word таким образом:
1. Когда объект не используется как блок синхронизации, это обычный объект. Mark Word содержит хэш-код объекта, а флаг блока синхронизации установлен на OnClickListener 01, а флаг использования привязанного блока синхронизации установлен на 0.
2. Когда объект используется как блок синхронизации и один поток A захватывает блок синхронизации, флаг блока синхронизации остается 01, но флаг использования привязанного блока синхронизации меняется на 1, а первые 23 бита используются для записи ID потока A, что указывает на переход в состояние привязанного блока синхронизации.
3. Когда поток A пытается снова получить блок синхронизации, JVM видит, что флаг блока синхронизации установлен на 01, а флаг использования привязанного блока синхронизации установлен на 1, то есть в состоянии привязки. Mark Word содержит ID потока A, что указывает на то, что поток A уже получил привязанный блок синхронизации и может выполнить код блока синхронизации.
Исправлено:
- Удалены лишние слова и фрагменты, которые не относятся к переводу.
- Корректировка пунктуации и стилистики текста.4. Когда поток B пытается получить этот блок синхронизации, JVM видит, что блок синхронизации находится в состоянии привязки, но ID потока в Mark Word не соответствует B. Тогда поток B пытается использовать операцию CAS для получения блока синхронизации. Эта операция может быть успешной, так как поток A обычно не освобождает привязанный блок синхронизации автоматически. Если блок синхронизации получен успешно, ID потока в Mark Word заменяется на ID потока B, что указывает на то, что поток B получил привязанный блок синхронизации и может выполнить код блока синхронизации. Если операция не удалась, продолжаются шаги 5.5. Если попытка получить блок синхронизации в состоянии привязки не удалась, это указывает на наличие конкуренции за блок синхронизации. Привязанный блок синхронизации будет преобразован в легковесный блок синхронизации. JVM создаёт отдельное пространство в стеке потока B, которое содержит указатель на блок синхронизации Mark Word объекта. В то же время в Mark Word объекта сохраняется указатель на это пространство. Обе эти операции выполняются с использованием CAS. Если обе операции были успешными, флаг блока синхронизации в Mark Word изменяется на 00, что указывает на получение блока синхронизации и возможность выполнения кода блока синхронизации. Если обе операции не были успешными, это указывает на неудачу в получении блока синхронизации из-за высокой конкуренции, и продолжаются шаги 6.6. Если попытка получить блок синхронизации в состоянии легковесного блокировки не удалась, JVM использует спин-блок (spin lock). Спин-блок не является состоянием блока синхронизации, а представляет собой процесс постоянной попытки получить блок синхронизации. С версии JDK 1.7 спин-блок по умолчанию активирован, количество попыток определяется JVM. Если блок синхронизации получен успешно, выполняется код блока синхронизации. Если попытка не удалась, продолжаются шаги 7.7. После того как попытка повторного захвата спин-блок (spin lock) не увенчалась успехом, синхронизация лока повышается до тяжёлой блокировки, а битовая метка лока изменяется на 10. В этом состоянии все потоки, которые не смогли захватить лок, блокируются.2. Указатель на класс
Длина этого указателя составляет 32 байта в 32-битной JVM и 64 байта в 64-битной JVM.
Данные класса Java-объекта хранятся в методической области (method area).
3. Длина массива
Эта информация хранится только в объектах массива.
Длина массива имеет размер 32 байта как в 32-битной, так и в 64-битной JVM.
## 12. Алгоритмы сборки мусора в JVM
**Молодое поколение:** область, где хранятся объекты с коротким временем жизни.
**Старшее поколение:** область, где хранятся объекты с долгим временем жизни.
**Общие черты:** обе области находятся в Java-стеке (heap).
### 1) Алгоритм маркировки и очистки
**Шаги выполнения:**
- Маркировка: проход по всему пространству памяти и пометка объектов, которые должны быть собраны.
- Очистка: повторный проход по пространству памяти и удаление всех помеченных объектов.
**Рисунки:**
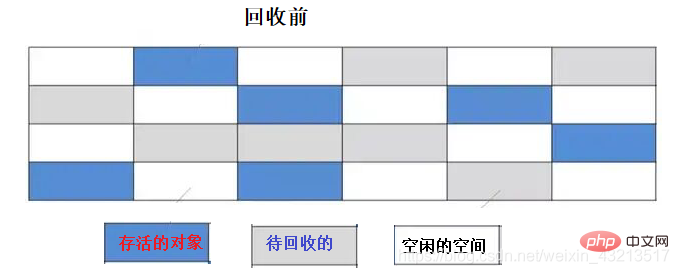
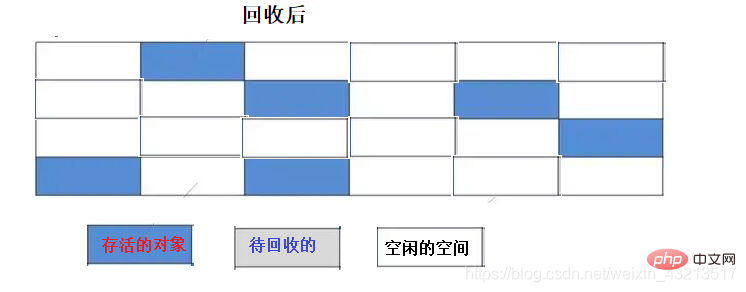
#### **Недостатки**
- Проблемы с производительностью; дважды проходит по всему пространству памяти (первый раз для пометки, второй раз для очистки).
- Проблемы с использованием памяти; легко образуются фрагменты памяти, что затрудняет поиск подходящего участка памяти при необходимости.
### 2) Алгоритм копированияПамять делится на две равные части, одна из которых используется в данный момент. Когда эта часть заполнена, происходит сборка мусора, и живые объекты копируются в другую часть, затем очищается первая часть. При следующей сборке мусора живые объекты снова копируются обратно, затем очищается вторая часть, и процесс повторяется.
**Рисунки:**
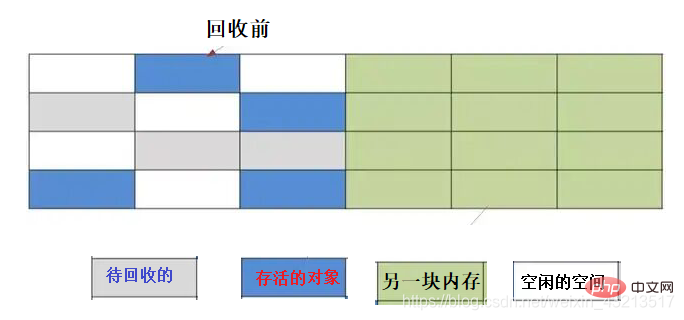
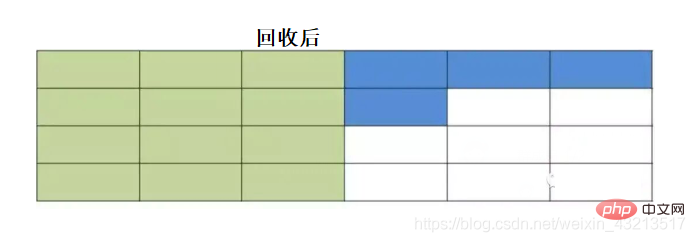
#### **Преимущества**
- Решает проблему фрагментации памяти по сравнению с алгоритмом маркировки и очистки.
- Высокая производительность (при очистке памяти, запоминаются начальный и конечный адреса, и вся область сразу очищается).
#### **Недостатки**
- Низкая эффективность использования памяти; всегда используется только половина памяти.
#### Улучшения
Исследования показывают, что большинство объектов в новой генерации имеют "краткосрочный" жизненный цикл, то есть они создаются утром и уничтожаются вечером. Их жизнь очень коротка, а чем дольше живут объекты, тем сложнее их освободить. При выполнении сборки мусора (Garbage Collection, GC) требуется очистить большое количество объектов, в то время как выживает лишь небольшое количество. Поэтому требуется переместить очень мало объектов в другую область памяти, и поэтому нет необходимости в однородном разделении памяти.Поэтому вся новая генерация памяти разделяется в соотношении 8 : 1 : 1 на три части. Самая большая часть называется Eden (иудейское слово "Эддун", часто переводится как "Эддун" или "Эддунская долина", но в контексте Java — "Эддун" или "Эддунская долина"). Две меньшие части называются To Survivor и From Survivor. Первая сборка мусора (GC) требует только копирования живых объектов из Eden в To. Затем область Eden полностью очищается. При следующей сборке мусора живые объекты из Eden и To копируются в From, и этот процесс повторяется. Таким образом, каждый раз доступная память в молодой зоне составляет около 90% всей молодой зоны, что значительно повышает эффективность использования памяти.
Однако это не гарантирует, что количество живых объектов всегда будет меньше 10% от всей молодой зоны. В этом случае копирование объектов может оказаться невозможным, поэтому используется другая область памяти, называемая старой зоной, для обеспечения распределения памяти, где объекты хранятся в старой зоне. Если этого недостаточно, возникает исключение OutOfMemoryError (OOM).
Старая зона: хранит объекты из молодой зоны, которые выживают после нескольких сборок мусора (по умолчанию OnClickListener 15 сборок).
### 3) Алгоритм помечивания и сжатияПоскольку алгоритм копирования становится менее эффективным при высокой выживаемости объектов, для старой зоны был предложен алгоритм "помечивания и сжатия".
**Шаги выполнения:**
- Помечивание: помечаются объекты, которые подлежат удалению.
- Сжатие: живые объекты перемещаются к одному концу памяти, а затем непотребляемая память удаляется.
**Рисунки:**
### 4) Алгоритм разделения по поколениям
Большинство современных коммерческих виртуальных машин используют этот алгоритм разделения по поколениям. Этот алгоритм не представляет ничего нового, он просто делит память на молодую и старую зоны в зависимости от времени жизни объектов, позволяя применять различные алгоритмы к различным областям. Например:
- Для молодой зоны, где большинство объектов погибает, применяется алгоритм копирования, имея в виду, что старая зона служит гарантом памяти.
- Для старой зоны, где объекты живут долго, можно использовать алгоритм помечивания и сжатия или помечивания и очистки.
## 13. Различие между MinorGC и FullGCMinorGC: сборка мусора, происходящая в молодой зоне. Из-за особенностей молодой зоны, MinorGC происходит очень часто, быстро и эффективно, удаляя большое количество объектов за один раз.
FullGC: сборка мусора, происходящая в старой зоне, также известная как MajorGC. Она происходит медленнее, примерно в 10 раз медленнее, чем MinorGC. Обычно FullGC сопровождается несколькими циклами MinorGC.## 14. Как JVM определяет, что объект является мусором
### 1) Алгоритм счетчика ссылок
Каждому объекту добавляется счетчик ссылок. Когда объект ссылается из некоторого места, счетчик увеличивается на 1. Когда ссылка на объект становится недействительной, счетчик уменьшается на 1. Когда счетчик становится равным 0, объект считается не используемым. **Преимущества**: **простота реализации и высокая эффективность проверки**
**Недостатки**: **возможность возникновения циклических ссылок**, если объект A ссылается на объект B, а объект B ссылается на объект A, то счетчики никогда не достигнут нуля.
### 2) Алгоритм достижимости (алгоритм поиска корней)
Начинается с объекта, называемого "корнем сборки мусора", и продолжает поиск ссылок вниз по дереву. Путь, пройденный при этом, называется цепочкой ссылок. Если объект больше не ссылается ни на что, то он считается ненужным и может быть собран сборщиком мусора. Это и есть алгоритм достижимости.
.jpg)
**Какие объекты могут служить корнями сборки мусора?**
1. Объекты, на которые ссылаются стеки виртуальной машины
2. Объекты, на которые ссылаются статические свойства классов в области классов
3. Объекты, на которые ссылаются константы в области классов
4. Объекты, на которые ссылаются стеки вызова методов## 15. Глубокое и поверхностное клонирование в Java
### **Поверхностное клонирование (Shallow Copy)**
1. Для членов-переменных, имеющих базовый тип данных, поверхностное клонирование будет просто копировать значения этих переменных в новый объект. Поскольку это две разных копии данных, изменения одного объекта не повлияют на другой объект.
2. Для членов-переменных, имеющих ссылочный тип данных, такие как массивы или объекты классов, поверхностное клонирование будет просто копировать ссылку на эти данные. Поскольку оба объекта указывают на одну и ту же область памяти, изменения одного объекта будут влиять на другой объект.
### Глубокое клонирование
Для глубокого клонирования требуется не только скопировать все значения членов-переменных базового типа данных, но и выделить память для всех членов-переменных ссылочного типа данных, а также скопировать все объекты, на которые они ссылаются, до тех пор, пока не будет достигнут конец всей графики объектов. То есть, при глубоком клонировании создаётся полная копия всего графа объектов!
Кратко говоря, глубокое клонирование создаёт новые области памяти для всех объектов, на которые ссылаются члены-переменные ссылочного типа; в то время как поверхностное клонирование просто передаёт адреса.## 16. Четыре типа ссылок в Java
### 1) Сильная ссылка
В Java наиболее распространены сильные ссылки. Присвоение объекта переменной ссылки делает эту переменную сильной ссылкой. Когда объект ссылается на сильную ссылочную переменную, он находится в доступном состоянии, **и его невозможно будет освободить сборщик мусора**, даже если этот объект никогда больше не будет использоваться, JVM всё равно не освободит его. Поэтому сильные ссылки являются одними из основных причин утечек памяти в Java.
```java
String str = new String("str");
Слабые ссылки реализуются с помощью класса WeakReference. Для объектов, имеющих только слабые ссылки, сборка мусора происходит следующим образом: когда у системы достаточно свободной памяти, такие объекты не собираются в мусор; когда же свободной памяти недостаточно, эти объекты собираются в мусор. Слабые ссылки обычно используются в программах, чувствительных к использованию памяти.
Если у системы достаточно свободной памяти, объект не будет собран в мусор.
Если у системы недостаточно свободной памяти, объект будет собран в мусор.
// Обратите внимание: wrf это также сильная ссылка, она указывает на объект WeakReference,
// а слабая ссылка указывает на новый объект String("str"), то есть T в классе WeakReference.
WeakReference<String> wrf = new WeakReference<String>(new String("str"));
```**Пригодные случаи использования:** при создании кеша, когда созданные объекты помещаются в кеш, и когда памяти становится недостаточно, сборщик мусора автоматически очистит ранее созданные объекты.
### 3) Уровень слабых ссылок
Уровень слабых ссылок реализуется с помощью класса `WeakReference`. Этот тип ссылок имеет более короткий срок жизни по сравнению со слабыми ссылками. Для объектов, имеющих только слабые ссылки, сборка мусора происходит следующим образом: как только запустится механизм сборки мусора, независимо от того, достаточно ли свободной памяти у JVM, этот объект будет собран в мусор.
```java
WeakReference<String> wrf = new WeakReference<>(str);
Пригодные случаи использования: ключи в java.util.WeakHashMap используют слабые ссылки. Это позволяет JVM автоматически управлять этими объектами, когда они больше не нужны.
Фантомные ссылки имеют механизм сборки мусора, похожий на слабые ссылки, но перед тем как объект будет собран в мусор, он временно помещается в очередь ReferenceQueue. Обратите внимание: другие ссылки помещаются в очередь ReferenceQueue только после того, как были собраны в мусор. Из-за этого механизма фантомные ссылки часто используются для выполнения действий перед удалением объекта. При создании фантомной ссылки обязательно нужно указать очередь ReferenceQueue.Пример использования:
PhantomReference<String> prf = new PhantomReference<>(new String("стр"), new ReferenceQueue<>());
Пригодные случаи использования: выполнение действий перед удалением объекта, таких как освобождение ресурсов. Метод Object.finalize() также может использоваться для этой цели, но он менее безопасен и менее эффективен.
Вышеперечисленные ссылки относятся к ссылкам на сами объекты, а не к ссылкам на четыре подкласса Reference (например, SoftReference).
Если алгоритмы сборки мусора являются методологией управления памятью, то сборщики мусора являются конкретной реализацией этих методов.
Garbage collector можно разделить на последовательный сборщик (Serial), параллельный сборщик (Parallel), CMS сборщик и G1 сборщик
Последовательный (Serial) сборщик
Обрабатывает все операции сборки мусора в одном потоке, что делает его эффективным благодаря отсутствию необходимости взаимодействия между несколькими потоками. Однако, он также не может использовать преимущества нескольких процессоров, поэтому этот сборщик подходит для машин с одним процессором. Конечно, этот сборщик также может использоваться на машинах с несколькими процессорами при небольшом объеме данных (около 100М). Можно использовать -XX:+UseSerialGC для включения.Параллельный (Parallel) сборщик
Производит параллельную сборку мусора в молодом поколении, что позволяет сократить время сборки мусора. Обычно используется на машинах с несколькими потоками и процессорами. Используйте -XX:+UseParallelGC для включения.
Конкурентный (CMS) сборщик Гарантирует, что большую часть работы можно выполнять конкурентно (приложение не останавливается), а сборка мусора прерывается только на короткое время. Этот сборщик подходит для средних и крупных приложений, где требуется высокое качество обслуживания. Используйте -XX:+UseConcMarkSweepGC для включения.
Serial означает последовательность, то есть он выполняется последовательно, это однопоточный сборщик, который использует только один поток для сборки мусора. Когда GC-поток работает, все остальные потоки останавливаются.
Использует алгоритм копирования для сборки мусора в молодом поколении.
Его преимущества заключаются в простоте и эффективности. В однопроцессорной среде, благодаря отсутствию затрат на взаимодействие между потоками, он имеет самую высокую производительность среди однопоточных сборщиков, поэтому он является по умолчанию сборщиком молодого поколения для клиентских сценариев.Явное использование этого сборщика как сборщика молодого поколения: -XX:+UseSerialGC
ПарНью сборщик является многопоточной версией сборщика Serial, он также является сборщиком молодого поколения. Кроме использования нескольких потоков для сборки мусора, все остальные параметры управления, алгоритмы сборки (алгоритм копирования), остановка всех потоков (Stop The World), правила распределения объектов, стратегии сборки и т.д. полностью совпадают с сборщиком Serial, и они используют много общего кода.
Процесс работы ПарНью сборщика представлен на следующем рисунке (старшее поколение использует Serial Old сборщик):Collector ParNew использует многопоточную сборку помимо прочего, но в остальном он не сильно отличается от собирателя Serial. Тем не менее, это предпочтительный собиратель нового поколения для многих виртуальных машин, работающих в режиме Server, и это связано с одним важным аспектом, не имеющим отношения к производительности: кроме собирателя Serial, на данный момент только он может работать совместно с собирателем CMS (Concurrent Mark Sweep). Собиратель CMS был представлен в JDK 1.5 и представляет собой революционный подход к сборке мусора, подробнее о котором будет рассказано позднее. Коллектор ParNew в однопроцессорной среде точно не будет эффективнее коллектора Serial, а в среде с двумя процессорами, реализованными с помощью технологии гиперпотоков, он также не гарантирует превосходства. В многопроцессорной среде, при увеличении количества процессоров, он значительно улучшает использование системных ресурсов во время сборки мусора. По умолчанию количество запущенных параллельных потоков сборки равно количеству процессоров, а при большом количестве процессоров можно использовать параметр -XX:ParallelGCThreads.### 3) Параллельный Scavenge коллектор — молодое поколение
Параллельный Scavenge коллектор также является параллельным многопоточным коллектором молодого поколения, использующим алгоритм копирования. Основной особенностью этого коллектора является то, что его цель отличается от целей других коллекторов. Цель таких коллекторов, как CMS, заключается в том, чтобы максимально сократить время приостановки пользовательских потоков во время сборки мусора, тогда как цель коллектора Параллельный Scavenge — это достижение управляемой пропускной способности (Throughput).
Чем меньше время приостановки, тем больше подходит для программ, требующих взаимодействия с пользователем, хорошая скорость реакции повышает удовлетворенность пользователя. Высокая пропускная способность позволяет эффективно использовать время работы CPU, чтобы как можно скорее завершить вычисления программы, что особенно полезно для задач, выполняемых в фоновом режиме и не требующих значительного взаимодействия с пользователем.
Старший вариант коллектора Serial, который также является однопоточным коллектором. Основные применения:
CMS (Concurrent Mark Sweep) коллектор ориентирован на получение минимального времени приостановки пользовательских потоков. Он отлично подходит для приложений, где важно обеспечивать высокое качество пользовательского опыта. Особенности:
CMS (Concurrent Mark Sweep) является первым истинно параллельным сборщиком, представленным в HotSpot с JDK 1.5; первый раз удалось сделать так, чтобы потоки сборки мусора работали одновременно с потоками пользователя (почти полностью).
Использует алгоритмы копирования + маркировки - компактации для сборки мусора в молодом и старшем поколении.
G1 делит кучу на несколько равных по размеру независимых областей (region), при этом молодое и старшее поколения больше не физически разделены.
Явное использование этого сборщика мусора как сборщика мусора для старшего поколения: -XX:+UseG1GC
ZGC (The Z Garbage Collector) — это сборщик мусора с низкой задержкой, введенный в JDK 11. Его основные цели включают:
Задержка не превышает 10 мс; Задержка не увеличивается с увеличением размера кучи или активных объектов; Поддерживает кучи размером от 8 МБ до 4 ТБ (в будущем поддерживает до 16 ТБ).
Принцип работы ZGC
Полностью конкурирующий ZGC
Как и ParNew и G1 в CMS, ZGC использует алгоритм маркировки - копирования, но он значительно модифицировал этот алгоритм: почти все этапы маркировки, копирования и перестройки в ZGC являются конкурирующими, что является ключевым фактором достижения цели задержки менее 10 мс.## 18. Отличия String, StringBuffer и StringBuilder
java.lang.String является потокобезопасным; поскольку private final char value[]; неизменяемыйString неизменяемо, значения StringBuffer и StringBuilder изменяемыStringBuilder > StringBuffer > String (потому что StringBuffer имеет блокировку, поэтому производительность снижается)StringBuffer: потокобезопасный, StringBuilder: потоконебезопасный. Поскольку все открытые методы StringBuffer имеют модификатор synchronized, а у StringBuilder такого нетString
sleep принадлежит классу Thread, а wait принадлежит классу Object.sleep не освобождает блокировку, в то время как метод wait освобождает блокировку, позволяя другим потокам использовать синхронизированные методы или блоки.wait, notify и notifyAll могут использоваться только внутри синхронизированных методов или блоков, в то время как sleep может использоваться в любом месте.
sleep требует захвата исключения, в то время как wait, notify и notifyAll не требуют захвата исключений. | | wait | sleep |
| ---------- | ------------------------------------------------------------ | ------------------------------------------------- |
| Синхронизация | Метод wait может быть вызван только в синхронизированном контексте, в противном случае будет выброшено исключение IllegalMonitorStateException | Не требуется вызывать в синхронизированном методе или блоке |
| Объект действия | Метод wait определен в классе Object и действует на объекте | Метод sleep определен в классе java.lang.Thread и действует на текущий поток |
| Освобождение блокировки | Да | Нет |
| Условие пробуждения | Другие потоки вызывают метод notify() или notifyAll() для объекта | Прерывание или истечение времени ожидания || Свойства метода | wait - это экземплярный метод | sleep - это статический метод |
| | | |
| | | |public enum State { /** * Новый */ NEW,
/**
* Выполняется
*/
RUNNABLE,
/**
* Блокируется
*/
BLOCKED,
/**
* Ждет, жестко ждет
*/
WAITING,
/**
* Ждет с таймаутом
*/
TIMED_WAITING,
/**
* Завершен
*/
TERMINATED;
}
## 21. Отличия synchronized и Lock
1. Synchronized — встроенное ключевое слово Java, а Lock — это класс Java.
2. Synchronized не может определить состояние получения блокировки, в то время как Lock может проверить, была ли блокировка успешно получена.
3. Synchronized автоматически освобождает блокировку, **Lock требует ручного освобождения блокировки! Если блокировка не будет освобождена, произойдет зацикливание!**
4. Synchronized: поток 1 (получает блокировку), поток 2 (ожидает, глупо ждет); Lock не обязательно будет ждать.
5. Synchronized — это повторно захватываемая блокировка, которая не может быть прервана, **несправедливая**; Lock — это повторно захватываемая блокировка, которая может быть прервана, несправедливая (можно настроить).
6. Synchronized подходит для синхронизации небольших участков кода, а Lock — для синхронизации больших участков кода.
7. Lock имеет блокировку только для блока кода, а synchronized имеет блокировку для блока кода и метода.
8. Использование блокировки Lock позволяет JVM затратить меньше времени на расписание потоков, что обеспечивает лучшую производительность. Кроме того, это обеспечивает лучшую масштабируемость (предоставляет больше подклассов).## 22. Что такое кэш-апокалипсис? Как его решить?
Кэш-апокалипсис — это ситуация, когда большая часть данных в кэше истекает срок действия и происходит большое количество запросов к базе данных, что приводит к чрезмерной нагрузке на базу данных и даже к её отказу. В отличие от кэш-перфорации, при которой одновременно происходят запросы к одной и той же записи, кэш-апокалипсис характеризуется истечением срока действия множества различных записей, что приводит к тому, что многие данные недоступны, и запросы переходят к базе данных.
Решение
1. Установите случайные сроки истечения для данных кэша, чтобы предотвратить массовое истечение срока действия данных в одно и то же время.
2. Если кэш-база данных распределена, распределите горячие данные равномерно между различными кэш-базами данных.
3. Установите горячие данные так, чтобы они никогда не истекали срок действия.
4. Обеспечьте высокую доступность кэша, чтобы предотвратить его отказ.
5. Используйте размытие, если кэш отказывает, чтобы предотвратить полный отказ системы, ограничивая часть трафика, направляемого в базу данных, чтобы гарантировать частичную доступность, а остальные запросы возвращаются с дефолтным значением размытия.
## 23. Что такое двойное написание кэша и базы данных с несоответствием? Как его решить?**Объяснение**: При последовательном написании в базу данных и кэш, во время операции, возникает параллелизм, что приводит к несоответствию данных. Обычно обновление кэша и базы данных происходит в следующих последовательностях:
- Обновление базы данных, а затем кэша.
- Удаление кэша, а затем обновление базы данных.
- Обновление базы данных, а затем удаление кэша.
Рассмотрим преимущества и недостатки каждого подхода:
**Обновление базы данных, а затем кэша.**
Проблема этого подхода заключается в том, что при одновременном обновлении данных двумя запросами, если не использовать распределенные блокировки, невозможно контролировать конечное значение кэша. То есть, проблема возникает при параллельном обновлении данных.
**Удаление кэша, а затем обновление базы данных.**
Проблема этого подхода: если после удаления кэша клиент читает данные, он может получить старые данные и установить их в кэше, что приведет к тому, что в кэше всегда будут старые данные.
Существуют два решения:
Использование "двойного удаления", то есть удаление после удаления, где последнее удаление выполняется асинхронно, чтобы предотвратить установку старых значений при чтении клиентом.
Использование очередей, когда ключ отсутствует, его помещают в очередь, и операция выполняется последовательно, до тех пор пока база данных не будет обновлена.
В целом, это довольно сложный подход.**Обновление базы данных, а затем удаление кэша**
Этот подход является наиболее распространенным. Он известен как паттерн Cache Aside. Если сначала обновить базу данных, а затем удалить кэш, то перед обновлением базы данных данные могут быть неактуальными.
Кроме того, если кэш истощится до обновления, а клиенты читают данные до удаления кэша, они могут получить старые данные. Это очень редкое совпадение.
Два условия: кэш истощается до обновления, и старые данные устанавливаются после удаления кэша — то есть чтение происходит быстрее, чем запись. **Некоторые записи также блокируют таблицу.**
Поэтому это случается крайне редко, но что делать, если это произошло? Используйте двойное удаление! Запишите, был ли клиентский запрос для чтения данных во время обновления, и если да, выполните асинхронное удаление после обновления базы данных.
Еще одна возможность: если обновление базы данных начинается, а удаление кэша не завершается из-за сбоя сервиса, что делать?
Это действительно проблема! Однако можно подписаться на журнал бинарных логов базы данных для удаления кэша.
## 24. Скажите, сколько методов в классе Object?
Какой язык используется в этом тексте? Текст на русском языке, поэтому нет необходимости в переводе. Однако, если требуется перевести текст на другой язык, он будет адаптирован под него.Java — это язык с одиночным наследованием, все классы Java имеют общего предка. Этот предок — класс Object.
Если класс не указывает явно, что он наследуется от какого-либо класса с помощью ключевого слова extends, то он автоматически наследует класс Object.
Методы класса Object мы используем практически постоянно.**Анализ**Класс `Object` является базовым классом для всех классов в Java. Он находится в пакете `java.lang` и содержит 13 методов. Как показано на следующем рисунке:
.jpg)
**Среди 13 методов конструктор класса `Object` скрыт и недоступен напрямую в коде;**
**метод `registerNatives()` является приватным методом.**
```java
private static native void registerNatives();
Два метода имеют модификатор protected:
protected native Object clone() throws CloneNotSupportedException;
protected void finalize() throws Throwable { }
Статический метод представлен только методом registerNatives():
конкретный ответ
1. Object()
Ничего особенного сказать нельзя, это конструктор класса `Object`. (не основной момент)
2. registerNatives()
Этот метод используется для того, чтобы JVM обнаруживала нативные функции. Они имеют определённое имя. Например, для `java.lang.Object.registerNatives` соответствующая C-функция имеет имя `Java_java_lang_Object_registerNatives`.
Используя `registerNatives` (или более точно, JNI функцию `RegisterNatives`) можно назначить любую C-функцию. (не основной момент)
3. clone()
Метод `clone()` используется для создания копии существующего объекта. Этот метод доступен только если объект реализует интерфейс `Cloneable`, в противном случае будет выброшено исключение `CloneNotSupportedException`. (внимание: этот ответ может вызвать вопросы о паттернах проектирования)
4. getClass()
```java
public final Class<?> getClass();
```Финальный метод, который используется для получения типа объекта во время выполнения. Этот метод возвращает объект класса `Class`, представляющий текущий объект. Эффект аналогичен `Object.class`. (внимание: этот ответ может вызвать вопросы о загрузке классов и рефлексии)5. equals()
Метод `equals()` используется для сравнения содержимого двух объектов. По умолчанию (наследуемый от класса `Object`) `equals` и `==` эквивалентны, если только они не переопределены. (внимание: этот ответ может вызвать вопросы о различиях между `equals` и `==` и принципах реализации `HashMap`)
6. hashCode()
Метод `hashCode()` используется для возврата хэш-кода объекта, представляющего его физический адрес. Часто этот метод вместе с `equals` переопределяется для обеспечения того, что равные объекты имеют одинаковый хэш-код. (внимание: этот ответ может вызвать вопросы о принципах реализации `HashMap`)
7. toString()
Метод `toString()` возвращает строковое представление объекта. Нечего особенного сказать.
8. wait()
Метод `wait()` заставляет текущий поток ждать, пока другой поток не вызовет метод `notify()` или `notifyAll()` для этого объекта. (это может вызвать вопросы о коммуникации между потоками и различиях между `wait` и `sleep`)
9. wait(long timeout)
Заводит текущий поток в состояние ожидания до тех пор, пока другой поток не вызовет метод `notify()` или `notifyAll()` для этого объекта или время ожидания не истечёт.
10. wait(long timeout, int nanos)
Заводит текущий поток в состояние ожидания до тех пор, пока другой поток не вызовет метод `notify()` или `notifyAll()` для этого объекта, поток не будет прерван другим потоком или время ожидания не истечёт.11.notify()
Пробуждает один из ожидающих потоков на этом объекте монитора.
12.notifyAll()
Пробуждает все ожидающие потоки на этом объекте монитора.
13.finalize()
Метод finalize() вызывается сборщиком мусора, когда он определяет, что больше нет ссылок на этот объект.
---
## 25. Основные параметры и рабочий процесс Java-пула потоков, стратегия отказа
Рабочий процесс пула потоков:
(1) Когда количество потоков меньше количества ядерных потоков, используются ядерные потоки.
( Yöntem (1): Eğer thread sayısının çekirdek thread sayısından az olduğunu belirtiyorsa, çekirdek threadleri kullanılır.
(2) Если количество ядерных потоков меньше общего количества потоков, избыточные потоки помещаются в очередь задач (блокирующая очередь).
(2) Если количество ядерных потоков меньше общего количества потоков, избыточные потоки помещаются в очередь задач (блокирующая очередь).
(3) Когда очередь задач (блокирующая очередь) заполнена, запускается максимальное количество потоков.
(3) Когда очередь задач (блокирующая очередь) заполнена, запускается максимальное количество потоков.
(4) Когда достигнуто максимальное количество потоков, запускается стратегия отказа.
(4) Когда достигнуто максимальное количество потоков, запускается стратегия отказа.
.jpg)
Ответ: Есть четыре стратегии отказа
1.ThreadPoolExecutor.AbortPolicy
**По умолчанию используется стратегия отказа AbortPolicy**, которая отбрасывает задачу и выбрасывает исключение RejectedExecutionException (т.е. последующие отправленные запросы не будут помещены в очередь и не будут обработаны, а выбросят исключение).
2.ThreadPoolExecutor.DiscardPolicy
Отбрасывает задачу, но не выбрасывает исключение. Если очередь задач заполнена, все последующие задачи будут отброшены, причем это будет тихое отбрасывание (никаких исключений не будет выброшено, задачи просто отброшены).
3.ThreadPoolExecutor.DiscardOldestPolicy
Отбрасывает самую старую задачу из очереди задач. Если очередь задач заполнена, самая старая задача будет отброшена, чтобы освободить место для новой задачи.
4.ThreadPoolExecutor.CallerRunsPolicy
Задача выполняется тем потоком, который её отправил. Если очередь задач заполнена, задача будет выполнена тем потоком, который её отправил, вместо того чтобы отбросить её или выбросить исключение.3.ThreadPoolExecutor.DiscardOldestPolicy
**Отбрасывает самую старую задачу из очереди**, затем заново отправляет отброшенную задачу (отбрасывает самую старую задачу из очереди, но не выбрасывает исключение; задачи просто отбрасываются).
4.ThreadPoolExecutor.CallerRunsPolicy
**Выполняет задачу вызывающим потоком** (не отбрасывает задачи, все задачи будут выполнены, никаких исключений не будет выброшено).
## 26. Примеры часто возникающих исключений в Java-разработке
`java.lang.NullPointerException` (исключение при обращении к пустому объекту)
Вызов непроинициализированного объекта или объекта, который не существует
`java.lang.ClassNotFoundException`
Указанный класс отсутствует
`java.lang.NumberFormatException`
Исключение при преобразовании строки в число
`java.lang.IndexOutOfBoundsException`
Индекс за пределами массива
`java.lang.IllegalArgumentException`
Некорректный аргумент метода
`java.lang.IllegalAccessException`
Отсутствие доступа
`java.lang.ArithmeticException`
Исключение при выполнении арифметических операций
`java.lang.FileNotFoundException`
Файл не найден
`java.lang.ArrayStoreException`
Исключение при хранении данных в массиве
`java.lang.NoSuchMethodException`
Метод не существует
`java.util.concurrent.RejectedExecutionException`
Исключение при отказе выполнить задачу в пуле потоков
`java.lang.OutOfMemoryError`
Ошибка недостатка памяти
`java.lang.NoClassDefFoundError`
Ошибка отсутствия определения класса
При попытке Java-виртуальной машины или загрузчика классов создать экземпляр класса, если определение этого класса отсутствует, выбрасывается данное исключение.Исключения, связанные с нарушением принципов безопасности: `SecurityException`
Исключения при работе с базой данных: `SQLException`
Исключения ввода-вывода: `IOException`
Исключения сетевого соединения: `SocketException`
## 27. Различие между перегрузкой (overload) и переопределением (override) в Java
### 1. Правила переопределения
```cpp
1. Переопределение происходит между родительским и дочерним классом.
2. Доступ к переопределенному методу в дочернем классе должен быть не менее широким, чем в родительском (public > default > protected > private).
3. Методы, объявленные как static или private в родительском классе, не могут быть переопределены, но могут быть переопределены в дочернем классе.
4. Методы родительского класса могут быть переопределены только дочерними классами.
5. При переопределении метода в дочернем классе, тип возвращаемого значения, параметры и порядок параметров должны совпадать с теми же параметрами в родительском классе.
1. Перегрузка может происходить внутри одного класса или между родительским и дочерним классом.
2. Перегрузка не зависит от типа возвращаемого значения, она требует одинакового имени метода, но различающихся параметров или порядка параметров.
## 28. Как TCP обеспечивает надежную передачу данных?- Приложение разделяет данные на блоки, которые TCP считает наиболее подходящими для отправки.
- TCP присваивает номер каждому отправленному пакету, а приемник сортирует пакеты по порядку и передает отсортированные данные приложению.
- **Проверка целостности**: TCP будет проверять контрольную сумму своего заголовка и данных. Это конечная проверка целостности, цель которой — выявить любые изменения данных во время передачи. Если контрольная сумма полученного сегмента отличается, TCP отбрасывает этот сегмент и не подтверждает его получение.
- TCP-приемник игнорирует повторяющиеся данные.
- **Управление потоком данных**: Каждая сторона TCP-соединения имеет буфер фиксированного размера. TCP-приемник позволяет отправителю отправлять только те данные, которые могут поместиться в буфере приемника. Когда приемник не может обрабатывать данные отправителя, он может сообщить последнему замедлить скорость отправки, чтобы избежать потери пакетов. TCP использует протокол слайдинг окна для управления потоком данных.
- **Управление конгестией**: Когда сеть перегружена, TCP снижает скорость отправки данных.
- **Протокол ARQ**: Этот протокол также используется для обеспечения надежной передачи. Его основная идея заключается в том, что после отправки каждого сегмента отправитель останавливается и ждет подтверждения от получателя.После получения подтверждения отправитель отправляет следующий сегмент.
- **Передача при истечении времени**: Когда TCP отправляет сегмент, он запускает таймер, ожидая подтверждения от получателя. Если подтверждение не приходит вовремя, сегмент отправляется повторно.## 29. Различия между TCP и UDP и их применение
### Различия
Ответ: TCP и UDP относятся к транспортному уровню.
1. TCP ориентирован на соединение (как телефонный звонок, который требует установления соединения); UDP не требует установления соединения.
2. TCP предоставляет надежные услуги. То есть, данные, переданные через TCP-соединение, будут переданы без ошибок, без потерь, без повторений и в правильном порядке; UDP старается доставить данные, но не гарантирует надежность.
3. TCP ориентирован на поток байтов, то есть TCP рассматривает данные как непрерывный поток байтов без структуры; UDP ориентирован на сообщения; UDP не имеет управления конгестией, поэтому сетевые перегрузки не приводят к снижению скорости отправки источника (что полезно для реального времени, таких как IP-телефония, видеоконференции в реальном времени и т.д.).
4. Каждое TCP-соединение является точкой к точке; UDP поддерживает одно к одному, одно ко многим, многие к одному и многие к многим взаимодействия.
5. Заголовок TCP занимает 20 байт; заголовок UDP мал, всего 8 байт.
6. Логический канал связи TCP является двунаправленным надежным каналом, UDP же представляет собой недостоверный канал.В некоторых случаях использование UDP действительно является наиболее эффективным подходом (обычно используется для мгновенного обмена сообщениями), например: голосовые вызовы в QQ, видеозвонки в QQ, прямые трансляции и т. д.TCP обычно используется для передачи файлов, отправки и получения электронной почты, удалённого входа и других сценариев.
## 30. Взаимозапираемые и невзаимозапираемые блокировки в Java
Взаимозапирающая блокировка означает, что блокировка может быть повторно захвачена одним и тем же потоком, но не другими потоками.
Взаимозапирающую блокировку также называют рекурсивной блокировкой.
**synchronized и ReentrantLock являются взаимозапирающими блокировками**.
**Одним из значений взаимозапирающей блокировки является предотвращение мёртвых琐事,继续翻译剩余部分:
блокировок.**
Основной принцип реализации достигается путём привязки счетчика запросов и потока, владеющего блокировкой, к каждой блокировке. Когда счетчик равен нулю, блокировка считается не занятой; когда поток запрашивает не занятую блокировку, JVM фиксирует владельца блокировки и устанавливает счетчик запросов в 1.
Если тот же поток снова запрашивает эту блокировку, счетчик будет увеличен;
каждый раз, когда занимающий поток покидает блок synchronized, значение счетчика уменьшается. Блокировка будет освобождена только тогда, когда счетчик достигнет нуля.
## Направление: Подробное объяснение LockSupport
**LockSupport представляет собой усовершенствованную версию механизма wait/notify**.
Как известно, библиотека concurrent основана на фреймворке AQS (AbstractQueuedSynchronizer). Этот фреймворк использует класс Unsafe для операций CAS (Compare and Swap) и класс LockSupport для операций park/unpark. Поэтому LockSupport является одним из ключевых компонентов библиотеки concurrent. Для понимания библиотеки concurrent логично начать именно с этого.
Фреймворк AQS использует два класса:
- Класс Unsafe обеспечивает операции CAS.
- Класс LockSupport обеспечивает операции park/unpark.`**LockSupport**`, бир тред энгелме арч классıdır**, туттун методулары **статик методулардын**, Бу класс, тредлердин һәрһандыктан энгелленмесине һәм натураһый энгели ҡалдырмaya өҫтөнгө өсмөлөт таңır. Сонуктан, LockSupport, Unsafe классынан native кодларына өсмөлөт ҡаҙаныр.LockSupport — это инструмент, который создает основу для блокировки и разблокировки потоков. LockSupport обеспечивает возможность блокировать и разблокировать потоки с помощью методов park() и unpark(). LockSupport связывает каждую нить с разрешением (permit). Разрешение можно рассматривать как значение 1 или 0. По умолчанию, разрешение равно 0; при вызове метода unpark(), разрешение становится равным 1. При вызове метода park(), если разрешение равно 1, поток немедленно возвращается, если же разрешение равно 0, поток блокируется. При вызове метода unpark(), разрешение становится равным 1. Каждый поток может получить только одно разрешение; при множественных вызовах метода unpark(), разрешение становится равным 1 только один раз.
Методы park() и unpark() не вызывают проблем смертельного замыкания, которые могут возникнуть при использовании методов Thread.suspend и Thread.resume. В связи с наличием разрешений, конкуренция между потоком, который вызывает park, и другим потоком, который пытается его unpark, остается активной.
Также существует версия метода park, которая позволяет установить время ожидания.```java
public static void park(Object blocker); // приостанавливает текущий поток
public static void parkNanos(Object blocker, long nanos); // приостанавливает текущий поток, но с ограничением времени ожидания
public static void parkUntil(Object blocker, long deadline); // приостанавливает текущий поток до определенного времени
public static void park(); // бесконечно приостанавливает текущий поток
public static void parkNanos(long nanos); // приостанавливает текущий поток, но с ограничением времени ожидания
public static void parkUntil(long deadline); // приостанавливает текущий поток до определенного времени
public static void unpark(Thread thread); // восстанавливает текущий поток
public static Object getBlocker(Thread t);
```Почему названо `park`? Слово `park` на английском означает "парковка". Если мы рассматриваем поток как автомобиль, то `park` означает "остановить автомобиль", а `unpark` — "восстановить и запустить автомобиль".
Можно использовать эти методы для блокировки и пробуждения потоков. Они имеют некоторые схожие функции с `wait` и `notify`, но `LockSupport` намного мощнее и удобнее.
**Вопросы для собеседования**
**1) Почему можно сначала пробудить поток, а затем заблокировать его?**
Потому что `unpark` предоставляет сертификат, который может быть использован при вызове `park`, чтобы законно потребовать этот сертификат, поэтому поток не будет заблокирован.
**2) Почему два вызова `unpark` и два вызова `park` в конце концов приводят к блокировке потока?**
Потому что количество сертификатов может быть не более одного, два вызова `unpark` и один вызов `unpark` дают одинаковый результат, то есть добавляется один сертификат;
два вызова `park` требуют двух сертификатов для снятия блокировки, сертификатов недостаточно, поэтому поток остается заблокированным.
## 32. Ожидание и пробуждение потоков в Java (три способа реализации)
### synchronizedОжидание `wait` пробуждение `notify` и ещё одно пробуждение всех потоков `notifyAll`. **`wait` и `notify` не могут существовать вне блока синхронизации, иначе будет выброшено исключение `IllegalMonitorStateException`.** В методах синхронизированного контроля или в блоках синхронизации вызываются методы `wait()`, `notify()` и `notifyAll()`. Если эти методы вызываются в методах, не являющихся синхронизированными, программа может успешно скомпилироваться, но при выполнении будет выброшено исключение `IllegalMonitorStateException`. Это исключение сопровождается неопределённой ошибкой, такой как "текущий поток не является владельцем". Это означает, что поток, вызывающий методы `wait()`, `notify()` и `notifyAll()`, должен "владеть" блоком монитора объекта перед тем, как вызвать эти методы. Если текущий поток не является владельцем блока монитора данного объекта, то при попытке вызова методов `notify()`, `notifyAll()` или `wait()` будет выброшено это исключение.### Реентрантный замокlock.newCondition
await() ожидание
signal() пробуждение
Вышеуказанные методы ожидания и пробуждения имеют проблему, связанную с последовательностью и необходимостью блокировки. Например, первый поток может не иметь блокировки, а второй поток всё равно может использовать метод пробуждения без выброса исключения. Однако, проблема заключается в том, что при компиляции будет выдано сообщение об ошибке. Кроме того, порядок вызова методов ожидания и пробуждения также имеет значение, и если метод пробуждения вызывается до метода ожидания, это также приведёт к выбросу исключения.
### LockSupport
Здесь есть методы park() и unpark(), которые используются для блокировки и разблокировки потока соответственно. У этих методов нет проблемы с последовательностью, но они должны использоваться парами. Если метод разблокировки вызывается раньше, чем метод блокировки, то последующие вызовы park() не будут работать. Внутри одного потока только первый вызов park() будет работать, а все последующие вызовы park() будут игнорированы, если другой поток уже разблокировал его. Поэтому выбор метода зависит от ситуации.
Основное преимущество этого подхода в том, что он не генерирует исключений и не требует строгой последовательности вызовов, что делает его более гибким в зависимости от ситуации.## 33. Основные принципы работы AQS
### **1) Основные знания о AQS**
- Volatile-переменная `state` используется для поддержания состояния синхронизации
- Состояние `state` изменяется с помощью операции CAS
- AQS основан на CLH-очереди (CLH-очередь была модифицирована в двунаправленную очередь)
- Каждый ожидающий поток упаковывается в узел `Node` и помещается в очередь
- AQS основан на шаблоне метода модели
- `LockSupport` используется для управления блокировкой и разблокировкой потока
- В AQS узел `Node` может представлять два типа ресурсов: исключительный (например, `ReentrantLock`) и совместный (например, `CountDownLatch`, `Semaphore`)
- Первый узел `Node` в FIFO-очереди является фиктивным узлом (или стражником), а второй узел `Node` — это реальный узел, представляющий поток.
### **Метод Дерево Карта**
Короткое описание: **AQS** — абстрактный очередной синхронизатор, аббревиатурой AQS. AQS используется как основной фреймворк для создания блокировок или других синхронизационных компонентов. Он использует целочисленную volatile переменную `state` для поддержания состояния синхронизации, а также использует встроенный FIFO-очередь для выполнения задачи очереди потоков, ожидающих доступ к ресурсу. AQS предоставляет полезную основу для множества синхронизационных компонентов, которые зависят от одной атомарной переменной `state`.
### 3) CLH-очередь в AQS
Проще говоря, AQS основан на CLH-очереди, использует `volatile` для изменения общего состояния `state`, потоки изменяют состояние с помощью `CAS`, успешное изменение приводит к получению блокировки, неудачное изменение приводит к добавлению потока в очередь ожидания, где он будет дожидаться своего пробуждения. CLH (Craig, Landin, и Hagersten) очередь представляет собой **виртуальную двунаправленную очередь**, то есть фактическая очередь не существует, а существуют лишь связи между узлами. AQS оборачивает каждый поток, запрашивающий доступ к общему ресурсу, в узел (Node) CLH-очереди для управления распределением блокировок.
### 4) Дизайн паттернов AQS
**Дизайн AQS основан на шаблоне метода**. Подклассы управляют состоянием синхронизации, наследуя AQS и реализуя его абстрактные методы-шаблоны. Внутри этих методов-шаблонов происходит реальное управление состоянием синхронизации (например, `tryAcquire`, `tryRelease`, `tryAcquireShared`, `tryReleaseShared`).
### 5) Концепция реализации AQS**Основные идеи реализации AQS**: Внутри AQS поддерживается CLH-очередь для управления блокировками. Потоки пытаются получить блокировку; если это невозможно, текущий поток и его состояние упаковываются в узел (Node) и добавляются в очередь синхронизации. Затем потоки продолжают циклически пытаться получить блокировку, пока они не станут прямым преемником головы очереди. Если попытка неудачна, поток блокируется до тех пор, пока его не разбудят. Когда поток, удерживающий блокировку, освобождает её, он разбуживает следующий поток в очереди. Классы Semaphore, ReentrantLock и CountDownLatch содержат внутренний класс Sync, который наследует AQS.**Внимание: AQS является спин-блокировкой**: во время ожидания разблокировки часто используется спин-блокировка (while (!CAS())), которая постоянно пытается получить блокировку до тех пор, пока она не будет успешно получена другим потоком.
Блокировки, реализованные с использованием AQS, включают **спин-блокировки, мьютексы, блокировки чтения/записи, условные переменные, семафоры и барьеры**.
### 6) Часто используемые синхронизаторы на основе AQS

## 34. Использование ключевого слова instanceof
Ключевое слово `instanceof` является двуместным оператором в Java, используемым для проверки, является ли объект экземпляром определенного класса или интерфейса. Синтаксис:
boolean result = obj instanceof Class
Здесь `obj` — это объект, а `Class` — это класс или интерфейс. Если `obj` является экземпляром `Class`, или его прямым или косвенным подклассом, или реализацией интерфейса `Class`, то результат `result` вернёт `true`, в противном случае — `false`.
Примечание: компилятор проверяет, может ли `obj` быть преобразован в тип справа, если нет — возникает ошибка компиляции. Если тип не определён, компиляция проходит, но конкретное поведение зависит от времени выполнения.```
int i = 0;
System.out.println(i instanceof Integer); // Компиляция не пройдет, так как i — это примитивный тип, а не ссылочный
System.out.println(i instanceof Object); // Компиляция не пройдет
Integer integer = new Integer(1);
System.out.println(integer instanceof Integer); // true
// false, согласно спецификации Java SE для оператора instanceof, если obj равен null, то он вернет false. System.out.println(null instanceof Object);
## 35. Сколько способов создания объекта в Java?
Java предоставляет четыре способа создания объекта:
- создание нового объекта с помощью ключевого слова `new`
- использование механизма рефлексии
- применение механизма клонирования (`clone`)
- использование механизма сериализации
## 36. Могут ли два неравнозначных объекта иметь одинаковый хэш-код?
Да, это возможно. При конфликте хэша два неравнозначных объекта могут иметь одинаковый хэш-код. Обычно используются следующие методы для решения конфликтов хэша:
Метод цепочек: каждый узел хэш-таблицы имеет указатель next, несколько узлов хэш-таблицы могут быть связаны в односвязный список с помощью указателя next, и эти узлы могут быть хранены в одном индексе. Метод открытой адресации: при конфликте хэша ищется следующий свободный адрес хэша, и запись может быть помещена в этот адрес. Метод двойного хэширования: это метод с несколькими различными функциями хэширования. При конфликте хэша используется вторая, третья... функции хэширования для вычисления адреса, пока не будет найдено место без конфликта.
## 37. Какие есть способы использования ключевого слова `final`?
Ключевое слово `final` можно использовать для объявления:
- констант (`final static`),
- методов (`final void`),
- классов (`final class`).1. Класс, помеченный ключевым словом `final`, не может быть наследован.
2. Метод, помеченный ключевым словом `final`, не может быть переопределен.
3. Переменная, помеченная ключевым словом `final`, не может быть изменена. Если это ссылка, то сама ссылка не может быть изменена, но содержимое, на которое она указывает, может быть изменено.
4. Метод, помеченный ключевым словом `final`, JVM может попытаться встроить его для повышения производительности выполнения.
5. Константа, помеченная ключевым словом `final`, хранится в пуле констант во время компиляции.Кроме того, компилятор следует двум правилам для ключевого слова `final`:
- Внутри конструктора запись в поле типа `final` и присваивание ссылки на созданный объект другому полю не могут быть переставлены местами.
- Первое чтение ссылки на объект с полем типа `final` и последующее чтение этого поля не могут быть переставлены местами.
## 38. Есть ли различия между `a=a+b` и `a+=b`?
Оператор `+=` выполняет **неявное преобразование типов**, а операция `a=a+b` не выполняет автоматическое преобразование типов. Например:
byte a = 127; byte b = 127; b = a + b; // Ошибка компиляции: cannot convert from int to byte b += a;
Имеется ошибка. При выполнении операций с типом `short`, компилятор автоматически преобразует его в `int`. То есть результат `s1 + 1` будет типа `int`, а `s1` — типа `short`, что вызывает ошибку компиляции.
Правильный способ:
short s1 = 1; s1 += 1;
Оператор `+=` выполняет приведение типа результата выражения справа к типу переменной слева.
## 39. try, catch, finally, в try есть return, выполняется ли finally?
Выполняется, и код `finally` выполняется до `return` в `try`.```
Заключение:
1. Независимо от того, была ли выброшена ошибка или нет, код блока `finally` всегда выполнится;
2. Даже если в блоках `try` или `catch` есть `return`, блок `finally` всё равно выполнится;
3. Выполнение блока `finally` происходит после вычисления выражения `return`, но перед тем как вернуть значение (значение сохраняется, и блок `finally` не изменяет это значение);
4. В блоке `finally` лучше не использовать `return`, так как это может привести к преждевременному завершению программы и возврату значения, отличного от того, которое было сохранено в блоках `try` или `catch`.
```## 40. 3 * 0.1 == 0.3, что вернёт сравнение?
false, поскольку некоторые числа с плавающей запятой не могут быть точно представлены.
.jpg)
## 41. Когда происходит полная сборка мусора (Full GC)?
Полная сборка мусора (Full GC) происходит при следующих четырёх условиях:
```1. Недостаток пространства в старшем поколении
Проблема недостатка пространства в старшем поколении возникает при переходе объектов из младшего поколения и создании больших объектов или массивов. Если после выполнения полной сборки мусора (Full GC) пространство все ещё недостаточно, будет выброшено следующее исключение: java.lang.OutOfMemoryError: Java heap space. Для предотвращения полной сборки мусора (Full GC) в таких ситуациях следует оптимизировать процесс так, чтобы объекты были собраны на этапе младшей сборки мусора (Minor GC), увеличить время жизни объектов в младшем поколении и избегать создания слишком больших объектов и массивов.```**2. Полное заполнение области Permanent Generation**
В области Permanent Generation хранятся данные классов и другие метаданные. При большом количестве загружаемых классов, используемых рефлексии и вызываемых методов, область Permanent Generation может заполниться. В случае, если сборка мусора с использованием алгоритма CMS не настроена, будет выполнена полная сборка мусора (Full GC). Если даже после полной сборки мусора (Full GC) память не освобождается, JVM выбросит следующее исключение: `java.lang.OutOfMemoryError: PermGen space`. Для предотвращения заполнения области Permanent Generation и последующей полной сборки мусора (Full GC) можно увеличить размер области Permanent Generation или перейти на использование алгоритма CMS.**3. Возникновение ошибок promotion failed и concurrent mode failure при использовании CMS для сборки мусора в старшем поколении**
При использовании CMS для сборки мусора в старшем поколении важно проверять логи сборки мусора на наличие ошибок promotion failed и concurrent mode failure. Ошибка promotion failed возникает при выполнении младшей сборки мусора (Minor GC), когда объекты не могут поместиться в зону выживания (survivor space) и должны быть перемещены в старшее поколение, но там нет места. Ошибка concurrent mode failure возникает при выполнении CMS, когда объекты пытаются быть перемещены в старшее поколение, но там нет места.
Для решения этих проблем можно увеличить размер зоны выживания (survivor space) и старшего поколения, либо уменьшить порог активации параллельной сборки мусора. Однако в версиях JDK 5.0+ и 6.0+ возможна проблема, связанная с багом JDK 29, который может привести к задержкам при выполнении шага очистки (sweeping) после завершения этапа отметки (remark). Для решения этой проблемы можно установить параметр -XX:CMSMaxAbortablePrecleanTime=5 (единицы измерения — миллисекунды).**4. Средний размер объектов, переходящих из младшего поколения в старшее, превышает доступное пространство в старшем поколении.**
Это сложная ситуация, при которой HotSpot проверяет, достаточно ли доступного пространства в старшем поколении для перехода объектов из младшего поколения. Если средний размер объектов, переходящих из младшего поколения в старшее, превышает доступное пространство в старшем поколении, будет выполнена полная сборка мусора (Full GC).Например, если после первой младшей сборки мусора (Minor GC) 6 МБ объектов перешли в старшее поколение, то при следующей младшей сборке мусора (Minor GC) будет проверено, достаточно ли доступного пространства в старшем поколении для этих объектов. Если доступное пространство меньше 6 МБ, будет выполнена полная сборка мусора (Full GC). Когда новое поколение начинает использовать PS GC, подход немного отличается: PS GC также проверяет оставшееся пространство в старшем поколении после Minor GC. Например, после первой Minor GC в приведённом выше примере PS GC проверяет, является ли оставшееся пространство в старшем поколении больше 6 МБ. Если это значение меньше, то происходит сборка мусора в старшем поколении.
Кроме вышеперечисленных четырёх случаев, для приложений Sun JDK, использующих RMI для RPC или управления, по умолчанию полная сборка мусора (Full GC) выполняется каждые 60 минут. Интервал выполнения Full GC можно настроить, передав параметр -Dsun.rmi.dgc.client.gcInterval=3600000 при запуске, или запретить вызов System.gc через RMI с помощью параметра -XX:+DisableExplicitGC.
## 42. Подробное описание молодого поколения, старшего поколения и постоянной зоны JVM
При работе с JVM, кучу обычно разделяют на три части: молодое поколение, старшее поколение и постоянная зона.
### 1) Молодое поколениеОсновное назначение — хранение новых объектов. Обычно занимает одну треть пространства кучи. Из-за частой создания объектов, молодое поколение часто вызывает MinorGC для очистки мусора.
Молодое поколение состоит из трёх областей: **Eden, SurvivorFrom и SurvivorTo**.
**Eden**: Это место рождения новых Java-объектов (если новый объект занимает много памяти, он сразу выделяется в старшее поколение). Когда Eden заполнен, происходит MinorGC для очистки молодого поколения.
**SurvivorTo**: Сохраняет объекты, которые выжили после последней MinorGC.
**SurvivorFrom**: Объекты, которые выжили после предыдущей MinorGC, и которые будут проверены в текущей MinorGC.
Когда JVM не может выделить достаточно места для нового объекта (когда Eden полон), происходит MinorGC. Чем меньше используется пространство молодого поколения, тем чаще происходит MinorGC.
**MinorGC использует алгоритм копирования**.
### 2) Старшее поколение
Объекты в старшем поколении более стабильны, поэтому MajorGC не выполняется часто.
**Условия для выполнения MajorGC:**
1. Перед MajorGC обычно происходит MinorGC, чтобы новые объекты из молодого поколения могли переместиться в старшее поколение. Когда пространство старшего поколения становится недостаточным, MajorGC запускается.
2. Когда невозможно найти достаточное непрерывное пространство для нового большого объекта, MajorGC запускается для очистки мусора и освобождения места.**MajorGC использует алгоритм маркировки-удаления (или маркировки-упаковки)**.
MajorGC требует больше времени, так как сначала требуется полное сканирование, а затем удаление. MajorGC также может создавать фрагментацию памяти. Для снижения потерь памяти обычно требуется объединение или маркировка для удобства следующего распределения.
Когда старшее поколение тоже заполнено, возникает исключение OutOfMemoryError (OOM).
### 3) Постоянная зона (заменена метаданными в Java 8)
Это область памяти, предназначенная для постоянного хранения информации. **Основное назначение — хранение информации о Class и Meta (метаданных)**.
Когда класс загружается, его метаданные помещаются в постоянную зону. Однако GC не удаляет информацию из постоянной зоны во время работы основной программы. Поэтому информация в постоянной зоне может расти с увеличением количества загруженных классов, что может привести к исключению OutOfMemoryError (OOM).Примечание: **В Java 8 постоянная зона была заменена областью метаданных (метасpace)**. Основное пространство сущностей и поколение постоянных данных имеют схожие характеристики, так как они представляют реализацию области методов в спецификации JVM. Однако самое значительное различие между основным пространством и поколением постоянных данных заключается в том, что основное пространство не находится в виртуальной машине, а использует локальную память. Поэтому по умолчанию размер основного пространства ограничен только доступной локальной памятью. Метаданные классов помещаются в native memory, строки и статические переменные классов — в куче Java. Таким образом, количество метаданных классов, которое можно загрузить, больше не контролируется параметром MaxPermSize, а зависит от фактически доступного пространства.Различия между Full GC и Major GC (по рекомендации 1 не стоит зацикливаться на различиях этих концепций, а следует сосредоточиться на решении проблем).
## 43. Процесс сборки мусора и его триггеры
Full GC — это сборка мусора всего пространства кучи, включая молодое и старое поколения.
Major GC — это сборка мусора старого поколения.
Minor GC триггер:
- Когда область Eden заполнена, JVM запускает Minor GC.
Major GC триггер:
- Обычно перед Major GC происходит Minor GC, чтобы объекты нового поколения могли перейти в старое поколение. Когда пространство старого поколения недостаточно, запускается Major GC.
- Когда невозможно найти достаточно большое непрерывное пространство для выделения новому созданному большому объекту (например, массиву), запускается Major GC для сборки мусора и освобождения пространства.
Triggers для Full GC:
- Вызов System.gc может рекомендовать выполнение Full GC, но не обязательно приводит к нему.
- Недостаток пространства в старом поколении.
- Недостаток пространства в области методов.
- После Minor GC средний размер объектов, перешедших в старое поколение, больше доступного пространства в старом поколении.
- При перемещении объектов из области Eden и From Space в To Space.
- Когда область постоянных данных заполнена, также запускается Full GC, что приводит к выгрузке метаданных классов и методов.## Правила распределения объектов
**Объекты предпочитают распределяться в области Eden**, если в этой области недостаточно места, виртуальная машина выполняет мелкую сборку мусора (Minor GC).
- **Большие объекты сразу переходят в старое поколение** (большие объекты — это те, которые требуют значительное количество непрерывной памяти). Целью является избежание большого количества копирования памяти между областью Eden и двумя областями Survivor (новое поколение использует алгоритм копирования для сборки мусора).
- Объекты с длительным сроком жизни переходят в старое поколение. Виртуальная машина определяет возрастной счетчик для каждого объекта, если объект пережил одну мелкую сборку мусора (Minor GC), он перемещается в область Survivor, а затем каждый раз при следующей мелкой сборке мусора возраст объекта увеличивается на 1, до тех пор пока он не достигнет порогового значения и не перейдет в старое поколение.
- Динамическое определение возраста объекта. Если суммарный размер всех объектов одного возраста в области Survivor превышает половину пространства Survivor, объекты этого возраста или более старые могут сразу перейти в старое поколение.
- Гарантия распределения памяти. При каждой мелкой сборке мусора (Minor GC) JVM вычисляет средний размер объектов, перемещаемых из области Survivor в старое поколение.Если этот размер больше оставшегося пространства в старом поколении, выполняется полная сборка мусора (Full GC). Если меньше, проверяется значение параметра HandlePromotionFailure; если true, выполняется мониторная сборка мусора (Monitor GC), если false, выполняется полная сборка мусора (Full GC).
## 45. Краткое описание объектной структуры в JavaОбъекты Java состоят из трех частей: **объектного заголовка, экземплярных данных, выравнивания и заполнения**.
Заголовок объекта состоит из двух частей. Первая часть хранит данные о времени выполнения объекта: хэш-код, поколение сборки мусора, состояние блокировки, владелец блокировки, идентификатор потока с предпочтением (обычно занимает 32/64 бита). Вторая часть представляет собой указатель на метаданные типа класса объекта (то есть, какой класс представляет данный объект). Если объект является массивом, то заголовок объекта также включает часть, используемую для записи длины массива.
Экземплярные данные используются для хранения действительной информации объекта (включая наследуемые от родительских классов и определенные самим объектом).
Выравнивание и заполнение: JVM требует, чтобы начальный адрес объекта был кратным 8 байтам (выравнивание на 8 байт).
## 46. Что такое загрузчики классов? Какие виды загрузчиков классов существуют?
Код, реализующий получение двоичного представления класса по его полному имени, называется загрузчиком классов.
Основные виды загрузчиков классов:1. **Загрузчик системных классов** (Bootstrap ClassLoader) используется для загрузки ядра Java. Он недоступен для прямого использования в Java-программах.
2. **Загрузчик расширений** (extensions class loader): используется для загрузки расширений Java. Java-виртуальная машина предоставляет каталог расширений. Этот загрузчик ищет и загружает классы в этом каталоге.
3. **Загрузчик системных классов** (system class loader): он загружает классы Java по пути CLASSPATH. Обычно все классы Java-приложения загружаются этим загрузчиком. Его можно получить через `ClassLoader.getSystemClassLoader()`.
4. **Пользовательские загрузчики классов**, реализуемые путем наследования от класса `java.lang.ClassLoader`.## 47. Различия между # и $ в MyBatis
1. `#` преобразует переданные данные в строку, автоматически добавляя двойные кавычки. Например, `order by #user_id#`, если переданное значение равно 111, то сгенерированное SQL будет выглядеть как `order by "111"`, а если переданное значение равно id, то SQL будет выглядеть как `order by "id"`.
2. `$` вставляет переданные данные напрямую в SQL. Например, `order by $user_id$`, если переданное значение равно 111, то сгенерированное SQL будет выглядеть как `order by user_id`, а если переданное значение равно id, то SQL будет выглядеть как `order by id`.
3. Использование `#` способствует предотвращению SQL-инъекций.
4. Использование `$` не предотвращает SQL-инъекции.
5. `$` обычно используется для передачи имен объектов базы данных, таких как имя таблицы.
6. Когда возможно использование `#`, лучше использовать именно его.
## 48. Процесс загрузки Bean в Spring
Основные классы: ApplicationContext
BeanFactory
BeanDefinitionRegistry
BeanPostProcessor1: Создайте объект типа ApplicationContext;
2: Вызовите метод-обработчик BeanFactory после выполнения сканирования;
3: Циклически анализируйте информацию о сканированных классах;
4: Создайте объект BeanDefinition для хранения информации, полученной в результате анализа;
5: Сохраните созданный объект BeanDefinition в кэше beanDefinitionMap для последующего использования при создании бинов;
6: Вновь вызовите метод-обработчик BeanFactory;
7: Конечно, Spring выполняет множество других задач, таких как международная локализация, регистрация BeanPostProcessor и т. д. Если нас интересует только процесс создания бина, то на этом этапе Spring вызывает метод finishBeanFactoryInitialization для создания одиночных бинов. Перед созданием бина Spring выполняет проверку, которая включает в себя перебор всех сканированных классов и проверку каждого бина на предмет его ленивости, прототипа, абстрактности и т. д.;
8: После завершения проверки Spring определяет конструктор для создания объекта, так как Spring использует рефлексию для создания объектов через конструкторы;
9: После определения конструктора Spring использует рефлексию для создания объекта. Обратите внимание, что это объект, объект, объект; на данном этапе объект уже создан, но это ещё не полный бин, поскольку свойства объекта ещё не были внедрены;
10: Spring обрабатывает объединённые BeanDefinition;11: Определяет, поддерживает ли циклическую зависимость, если поддерживает, то заводит фабрику в singletonFactories — map;
12: Определяет необходимость внедрения свойств;
13: Если требуется внедрение свойств, начинается процесс внедрения;
14: Определяет тип бина и вызывает методы интерфейса Aware;
15: Вызывает методы обратного вызова жизненного цикла;
16: Если требуется, завершает процесс создания прокси;
17: Сохраняет бин в пуле одиночных объектов — бин завершен — находится в контейнере Spring;## 49. Новые возможности Java 8
### 1) Lambda-выражения
Lambda-выражения, также известные как замыкания, являются наиболее важной новой возможностью, которая способствовала выпуску Java 8.
Lambda-выражения позволяют передавать функции в качестве параметров методов (передача функций в методы).
Использование lambda-выражений позволяет сделать код более компактным и чистым.
// (int x, int y) -> x + y
Пример:
public class Java8Tester { public static void main(String args[]) { Java8Tester tester = new Java8Tester();
// Объявление типа
MathOperation addition = (int a, int b) -> a + b;
// Без объявления типа
MathOperation subtraction = (a, b) -> a - b;
// Возврат значения в фигурных скобках
MathOperation multiplication = (int a, int b) -> { return a * b; };
// Без фигурных скобок и возврата значения
MathOperation division = (int a, int b) -> a / b;
System.out.println("10 + 5 = " + tester.operate(10, 5, addition));
System.out.println("10 - 5 = " + tester.operate(10, 5, subtraction));
System.out.println("10 x 5 = " + tester.operate(10, 5, multiplication));
System.out.println("10 / 5 = " + tester.operate(10, 5, division));
// Без скобок
GreetingService greetService1 = message ->
System.out.println("Привет " + message);
// Скобки
GreetingService greetService2 = (message) ->
System.out.println("Привет " + message);
greetService1.sayMessage("Runoob");
greetService2.sayMessage("Google");
}
interface MathOperation { int operation(int a, int b); }
interface GreetingService { void sayMessage(String message); }
private int operate(int a, int b, MathOperation mathOperation) { return mathOperation.operation(a, b); } }
### 2) Методические ссылкиМетодические ссылки позволяют указывать метод по его имени.
Использование методических ссылок делает конструкцию языка более компактной и лаконичной, уменьшая количество избыточного кода.
Методические ссылки используются с помощью пары двоеточий **::**.
```java
import java.util.List;
import java.util.ArrayList;
public class Java8Tester {
public static void main(String args[]) {
List<String> names = new ArrayList<>();
names.add("Google");
names.add("Runoob");
names.add("Taobao");
names.add("Baidu");
names.add("Sina");
names.forEach(System.out::println);
}
}
Функциональный интерфейс (Functional Interface) — это интерфейс, содержащий ровно один абстрактный метод, но может содержать несколько неабстрактных методов.
Функциональные интерфейсы могут быть неявно преобразованы в лямбда-выражения.
Лямбда-выражения и методические ссылки (включая методические ссылки) используются для этого.
Например, определение функционального интерфейса:
@FunctionalInterface
interface GreetingService {
void sayMessage(String message);
}
Java 8 добавила возможность определения по умолчанию методов в интерфейсах.
Кратко говоря, по умолчанию методы — это методы, которые уже реализованы в интерфейсе, и не требуют реализации в классах, которые этот интерфейс реализуют.
Для определения по умолчанию метода достаточно добавить ключевое слово default перед методом.```java
public interface Vehicle {
default void print() {
System.out.println("Я — автомобиль!");
}
}
### 5) Поток (Stream)
Java 8 API добавил новый абстрактный тип данных, называемый потоком Stream, который позволяет работать с данными в декларативном стиле.
Stream позволяет использовать SQL-подобные запросы для работы с коллекциями Java.
API Stream значительно повышает продуктивность Java-разработчиков, позволяя писать эффективный, чистый и лаконичный код.
Элементы потока проходят через цепочку операций (промежуточных операций), и в конце концов результат получается благодаря терминальной операции.
### 6) Класс Optional
Класс Optional представляет контейнер для значения, которое может быть null. Если значение существует, метод `isPresent()` вернет true, а метод `get()` вернет само значение. Optional является контейнером: он может хранить значение типа T или просто null. Optional предоставляет множество полезных методов, что позволяет избежать явной проверки на null.
Введение класса Optional хорошо решает проблему NullPointerException.
**Пример:**
```java
import java.util.Optional;
public class Java8Tester8 {
public static void main(String args[]) {
Java8Tester8 java8Tester = new Java8Tester8();
Integer value1 = null;
Integer value2 = new Integer(10);
// Optional.ofNullable - позволяет передавать null как параметр
Optional<Integer> a = Optional.ofNullable(value1);
// Optional.of - если переданный параметр равен null, выбрасывает исключение NullPointerException
Optional<Integer> b = Optional.of(value2);
System.out.println(java8Tester.sum(a, b));
}
}
``````markdown
public Integer sum(Optional<Integer> a, Optional<Integer> b) {
// Optional.isPresent - проверяет наличие значения
System.out.println("Первый параметр существует?: " + a.isPresent());
System.out.println("Второй параметр существует?: " + b.isPresent());
// Optional.orElse - если значение существует, возвращает его, иначе возвращает значение по умолчанию
Integer value1 = a.orElse(new Integer(0));
// Optional.get - получает значение, значение должно существовать
Integer value2 = b.get();
return value1 + value2;
}
}
Nashorn — это движок для выполнения JavaScript.
Nashorn JavaScript движок был отключен в Java 15.
Это было помечено как:
@deprecated (forRemoval = true)
С JDK 1.8 Nashorn заменил Rhino (JDK 1.6, JDK 1.7) как встроенный JavaScript движок Java. Nashorn полностью поддерживает спецификацию ECMAScript 5.1 и некоторые расширения. Он использует новые языковые возможности, определенные в JSR 292, включая invokedynamic, который был введен в JDK 7, чтобы компилировать JavaScript в Java байткод.
По сравнению с предыдущим Rhino реализованием, это привело к увеличению производительности в 2-10 раз.
Java 8 улучшил обработку дат и времени, выпустив новый Date-Time API (JSR 310).
- **Небезопасность в многопоточной среде** — класс `java.util.Date` не является потокобезопасным. Все датовые классы являются изменяемыми, что является одним из крупнейших недостатков Java-классов для работы с датами.
- **Плохое проектирование** — определение датовых/временных классов в Java не последовательно выполнено. Классы для работы с датами присутствуют как в пакете `java.util`, так и в пакете `java.sql`. Кроме того, классы для форматирования и парсинга находятся в пакете `java.text`. Класс `java.util.Date` одновременно содержит как дату, так и время, в то время как класс `java.sql.Date` содержит только дату, что не имеет логического объяснения. Также эти два класса имеют одинаковое имя, что само по себе является очень плохим дизайном.
- **Проблемы с часовым поясом** — датовые классы не поддерживают международные стандарты и не имеют поддержки часовых поясов. Поэтому в Java были введены классы `java.util.Calendar` и `java.util.TimeZone`, но они также страдают от вышеупомянутых проблем.
Java 8 в пакете **java.time** предоставляет множество новых API. Вот два наиболее важных из них:- **Local (локальный)** — упрощает работу с датами и временем, не учитывая часовой пояс.
- **Zoned (с учётом часового пояса)** — позволяет работать с датами и временем, учитывая определённый часовой пояс.
Новый пакет `java.time` охватывает все операции с датами, временем, датами/временем, часовым поясом, моментами времени (instants), периодами (periods) и часами (clock).
```java
import java.time.LocalDate;
import java.time.LocalTime;
import java.time.LocalDateTime;
import java.time.Month;
public class Java8Tester {
public static void main(String args[]) {
Java8Tester java8tester = new Java8Tester();
java8tester.testLocalDateTime();
}
public void testLocalDateTime() {
// Получение текущей даты и времени
LocalDateTime currentTime = LocalDateTime.now();
System.out.println("Текущее время: " + currentTime);
LocalDate date1 = currentTime.toLocalDate();
System.out.println("date1: " + date1);
Month month = currentTime.getMonth();
int day = currentTime.getDayOfMonth();
int seconds = currentTime.getSecond();
System.out.println("Месяц: " + month + ", День: " + day + ", Секунды: " + seconds);
LocalDateTime date2 = currentTime.withDayOfMonth(10).withYear(2012);
System.out.println("date2: " + date2);
// 12 декабря 2014
LocalDate date3 = LocalDate.of(2014, Month.DECEMBER, 12);
System.out.println("date3: " + date3);
// 22 часа 15 минут
LocalTime date4 = LocalTime.of(22, 15);
System.out.println("date4: " + date4);
// Парсинг строки
LocalTime date5 = LocalTime.parse("20:15:30");
System.out.println("date5: " + date5);
}
}
В Java 8 базовая реализация Base64 стала частью стандартной библиотеки Java.
Java 8 включает в себя кодировщики и декодировщики Base64.Класс Base64 предоставляет набор статических методов для получения трёх типов BASE64-кодировщиков и декодировщиков:
Вложенные классы
| Номер | Вложенный класс & Описание |
|---|---|
| 1 | статический класс Base64.Decoder Этот класс реализует декодер для декодирования байтовых данных с использованием кодировки Base64. |
| 2 | статический класс Base64.Encoder Этот класс реализует кодировщик для кодирования байтовых данных с использованием кодировки Base64. |
Характеристики:
(1) Протокол открыт и независим от конкретного оборудования и операционной системы.
(2) Независим от сетевого оборудования, может работать в широкополосных сетях и особенно хорошо подходит для Интернета.(3) Унифицированный адрес для всех устройств и терминалов в сети, каждый имеет уникальный адрес.
(4) Стандартизация верхних уровней протоколов, что позволяет предоставлять различные надежные сетевые услуги.
Это значит, что приложение должно установить соединение TCP перед использованием протокола TCP. После завершения передачи данных соединение TCP должно быть закрыто.
Каждое соединение TCP должно быть один-к-одному.
TCP обеспечивает надёжную доставку данных. Данные, переданные через соединение TCP, не теряются, не повторяются, не содержат ошибок и доставляются в правильном порядке.
TCP обеспечивает полудуплексное соединение. TCP позволяет приложениям на обоих концах соединения отправлять данные в любое время. В каждом конце соединения есть буферы отправки и приема для временного хранения данных. При отправке приложение передает данные в буфер TCP и может продолжать работу, а TCP отправляет данные в подходящее время. При получении TCP сохраняет данные в буфер, и приложение может считывать данные из буфера в подходящее время.5. Ориентирован на поток байтов. "Поток (Stream)" в TCP означает последовательность байтов, входящих в процесс или выходящих из него.
Оrientированность на поток байтов означает, что хотя приложение и взаимодействует с TCP по одному блоку данных (разного размера), TCP рассматривает данные как последовательность безструктурных байтов.
До JDK 1.7 HashMap была реализована с использованием массива и связного списка, причём применялся метод вставки в начало списка.
С JDK 1.8 при решении конфликтов хеширования произошли значительные изменения. Когда длина связного списка превышает пороговое значение (по умолчанию 8), перед тем как преобразовать список в бинарное дерево поиска (красно-черное дерево), проверяется длина текущего массива. Если она меньше 64, происходит увеличение размера массива, а не преобразование в бинарное дерево поиска. В противном случае связный список преобразуется в бинарное дерево поиска (красно-черное дерево), чтобы снизить время поиска. При этом используется метод вставки в конец списка.
Хеш-карта (HashMap) по умолчанию инициализируется размером в 16 элементов. Когда количество элементов в хеш-карте превышает пороговое значение, определяемое коэффициентом загрузки и текущим размером карты, происходит расширение карты, при котором её размер удваивается.> Внимание: Мы можем также предварительно установить начальный размер карты, зная количество данных, которое будет храниться в ней (начальный размер = количество данных / коэффициент загрузки). Преимуществом этого подхода является возможность снизить количество операций расширения (resize()), что повышает производительность хеш-карты.
Вопрос: Опишите метод put() для хеш-карты (HashMap).
Ответ: Исходя из анализа исходного кода, можно ответить на этот вопрос, рассматривая версии JDK 7 и 8:1. По ключу применяется хеш-функция, чтобы получить индекс массива.
2. Если элемент на данном индексе отсутствует, то ключ и значение упаковываются в объект типа Entry (в JDK 1. 7 это Entry, а в JDK 1. 8 — Node) и помещаются на соответствующую позицию.
3. Если элемент на данном индексе уже существует, то требуется различать ситуации:
(i) В случае JDK 1. 7 сначала проверяется необходимость расширения. Если расширение необходимо, то оно выполняется. Если расширение не требуется, то создаётся объект Entry и добавляется в список методом "head insertion".
(ii) В случае JDK 1. 8 сначала проверяется тип объекта на данной позиции. Это может быть либо узел дерева красно-черного (TreeNode), либо узел списка (Node):
(a) Если это узел дерева красно-черного, то ключ и значение упаковываются в новый узел дерева и добавляются в дерево. При этом проверяется наличие ключа в дереве, и если он уже существует, то значение обновляется.
(b) Если это узел списка, то ключ и значение упаковываются в новый узел списка и добавляются в конец списка методом "tail insertion". При этом проверяется наличие ключа в списке, и если он уже существует, то значение обновляется. После добавления нового узла в список проверяется его размер, и если он превышает 8, то список преобразуется в дерево красно-черного.
(c) После добавления ключа и значения в список или дерево красно-черного проверяется необходимость расширения.Если расширение необходимо, то завершается метод put().## 52. Что такое модель родительского делегирования?Сначала стоит понять, что такое загрузчик классов. Проще говоря, загрузчик классов загружает файлы классов в памяти JVM по их полному имени и преобразует их в объекты типа Class. Если рассматривать с точки зрения JVM, то существуют всего два типа загрузчиков классов:
Bootstrap ClassLoader): реализован на языке C++ (для HotSpot), отвечает за загрузку библиотек классов, расположенных в директории <JAVA_HOME>\lib или указанной через параметр -Xbootclasspath, в память.Java и наследуются от абстрактного класса ClassLoader. Например:
Extension ClassLoader): отвечает за загрузку всех библиотек классов, расположенных в директории <JAVA_HOME>\lib\ext или указанной через системную переменную java.ext.dirs.Application ClassLoader): отвечает за загрузку библиотек классов, указанных в пути классов пользователя (classpath). Мы можем использовать этот класс-лоадер напрямую. Обычно, если мы не создаем свой класс-лоадер, используется именно этот лоадер по умолчанию. Процесс работы модели двойной родительской делегации заключается в следующем: если один загрузчик классов получает запрос на загрузку класса, он сначала не пытается загрузить этот класс самостоятельно, а делегирует этот запрос загрузчику родительского класса для выполнения.Каждый загрузчик классов действует таким образом, и только когда родительский загрузчик не может найти указанный класс в своей области поиска (то есть выбрасывает исключение ClassNotFoundException), потомственный загрузчик пытается загрузить класс самостоятельно.IoC означает инверсию управления и представляет собой концепцию дизайна программирования на объектах. Без использования этой концепции нам приходится самостоятельно поддерживать зависимости между объектами, что часто приводит к чрезмерной связанности объектов. Особенно в крупных проектах отношения между объектами могут быть очень сложными, что затрудняет поддержание кода. IoC решает эту проблему, помогая поддерживать зависимости между объектами и снижая связность между ними.
Когда говорят об IoC, нельзя не упомянуть DI, где DI означает внедрение зависимостей, это способ реализации IoC. Поскольку термин IoC абстрактен, а DI более конкретен, часто используют DI как синоним для IoC. В большинстве случаев мы просто считаем IoC и DI равнозначными, что стало обычной практикой. Основной ключевой момент внедрения зависимостей — это контейнер IoC, который по сути является фабрикой.Дополнительный ответ для получения дополнительных баллов. Перед появлением популярности легковесных подходов Java EE, таких как Spring, в реальных проектах чаще использовалась модель программирования с использованием EJB. В модели EJB разработчики должны были создавать компоненты EJB, которые должны соответствовать спецификациям EJB для выполнения в контейнере EJB, обеспечивая таким образом такие базовые службы, как управление транзакциями и жизненным циклом.Сервисы, предоставляемые Spring, не отличаются от тех, что предоставляются EJB, но способы их получения различаются: Spring IoC предоставляет базовый контейнер JavaBeans, который управляет зависимостями через паттерн IoC и усиливает базовые функции JavaBeans, такие как управление транзакциями и жизненным циклом, через внедрение зависимостей и AOP.
Что касается EJB, то даже простой EJB-компонент требует создания удалённого/локального интерфейса, интерфейса Home и класса-реализации Bean. Кроме того, EJB не могут работать вне контейнера EJB, а поиск других EJB-компонентов требует использования методов, таких как JNDI, что приводит к зависимости от контейнера EJB и спецификаций. То есть Spring преобразует EJB-компоненты в POJO или JavaBeans, тем самым снижая зависимость от традиционных спецификаций J2EE.
При разработке приложений разработчики часто используют компоненты, которые зависят друг от друга. Если эти зависимости закреплены в дизайне компонентов, это может привести к жёсткости зависимостей и увеличению трудностей поддержки. В этом случае использование IoC позволяет перевернуть направление получения ресурсов, делая контейнер IoC активным управляющим этими зависимостями и внедряющим их в компоненты, что делает управление этими зависимостями более гибким.[Дополнительная информация] Spring предоставляет два типа контейнеров: BeanFactory и ApplicationContext.
BeanFactory: это базовый контейнер IoC, который предоставляет полную поддержку IoC. Без специальной настройки используется стратегия отложенной инициализации. Объекты-управляемые инициализируются и получают внедренные зависимости только тогда, когда клиентский объект требует доступ к ним. Поэтому контейнер быстрее запускается и требует меньше ресурсов. Для ситуаций с ограниченными ресурсами и менее строгими требованиями к функциональности BeanFactory является подходящим выбором.ApplicationContext: он построен поверх BeanFactory и представляет собой более продвинутый контейнер. В дополнение ко всему, что предоставляет BeanFactory, ApplicationContext также предлагает ряд продвинутых возможностей, таких как публикация событий и поддержка международной информации. Все управляемые объекты в контейнере ApplicationContext инициализируются и связываются сразу после запуска контейнера. Поэтому, в сравнении с BeanFactory, ApplicationContext требует больше системных ресурсов, а также время запуска контейнера будет больше, так как все инициализации выполняются сразу при старте. В тех случаях, когда системные ресурсы достаточно изобильны, и требуется больше функциональности, контейнер типа ApplicationContext является более подходящим выбором.
В конкретной реализации существуют три основных способа внедрения:
Инъекция через конструктор означает, что объект, который подлежит инъекции, может объявить зависимости в списке параметров своего конструктора, тем самым указывая внешнему миру о своих зависимостях. Затем служба IoC (Inversion of Control) проверяет конструктор объекта, получает список необходимых зависимостей и инъектирует соответствующие объекты. Этот метод инъекции более прямолинейный, так как после создания объекта он сразу становится доступным для использования.2. Инжекция через setter-методы позволяет изменять свойства объекта с помощью setter-методов. Таким образом, текущий объект может добавить setter-методы для своих зависимостей, чтобы служба IoC могла установить соответствующие объекты зависимостей. В отличие от инжекции через конструктор, этот метод не позволяет сразу использовать объект после его создания, но предоставляет большую гибкость.
Инжекция через интерфейсы в отличие от двух предыдущих методов, инжекция через интерфейсы менее очевидна. Объект, который подлежит инжекции, должен реализовать определенный интерфейс, предоставляющий метод для инжекции зависимостей. Служба IoC использует эти интерфейсы для понимания того, какие зависимости должны быть инжектированы в объект. Этот метод считается более жестким и сложным по сравнению с другими методами инжекции.
В целом, инжекция через конструктор и setter-методы являются наиболее распространенными из-за своей низкой инвазивности и простоты понимания и использования. Инжекция через интерфейсы, будучи более инвазивной, в последнее время стала менее популярной.
Список встроенных объектов JSP и их свойств представлен ниже:
Запрос клиента упакован в объект request, через который можно получить информацию о запросе клиента и отправить ответ. Это экземпляр класса HttpServletRequest.### 2) Объект response
Объект response содержит информацию об ответе на запрос клиента, но в JSP его использование является редким. Это экземпляр класса HttpServletResponse.
Объект session представляет собой сессию между клиентом и сервером, которая начинается при подключении клиента к серверу и заканчивается при отключении клиента. Это экземпляр класса HttpSession.
Объект out является экземпляром класса JspWriter и используется для вывода контента на клиент.
Объект page указывает на текущую JSP-веб-страницу саму по себе, что похоже на указатель this в классах. Это экземпляр класса java.lang.Object.
Объект application обеспечивает возможность обмена данными между пользователями, позволяя хранить глобальные переменные. Он существует с момента запуска сервера до его завершения. В течение этого времени объект доступен для всех пользователей, и любое изменение его свойств влияет на все пользователей. Объект application является экземпляром класса ServletContext.
Объект exception представляет собой объект исключения, который создается при возникновении исключения во время выполнения страницы. Если JSP-страница должна использовать этот объект, то необходимо установить isErrorPage в true, иначе компиляция невозможна. Этот объект является экземпляром класса java.lang.Throwable.### 8) Объект pageContext
Объект pageContext предоставляет доступ ко всем объектам внутри JSP-страницы и к пространствам имён. Он может получить доступ к сессии, связанной с текущей страницей, а также к определённым свойствам приложения. Этот объект можно рассматривать как интеграцию всех функций страницы, и его имя класса также называется pageContext.
config
Объект config используется для передачи информации о Servlet-инициализации, включая параметры инициализации (через имя и значение свойства) и информацию о сервере (через передачу объекта ServletContext).
Грациозное завершение работы Spring Boot-приложений означает, что при остановке приложения завершаются все активные запросы, но новые запросы больше не принимаются. В этой статье подробно рассмотрены методы грациозного завершения работы Spring Boot-приложений, включая использование Actuator, Shutdown Endpoint, Spring Application и Spring Boot Admin.
В официальной документации Spring Boot указано, что для слушания событий успешного запуска и завершения проекта достаточно реализовать определённые интерфейсы. Эти интерфейсы включают:- Интерфейс CommandLineRunner: когда приложение успешно запущено, но ещё не начало принимать трафик, вызывается реализация этого интерфейса.
Интерфейс ApplicationRunner: работает аналогично интерфейсу CommandLineRunner.
Интерфейс DisposableBean: когда приложение готовится к завершению, вызывается реализация этого интерфейса. Также можно использовать аннотацию @PreDestroy; методы, помеченные этой аннотацией, будут вызваны. На основе этого процесса мы можем создать слушатель сервиса, который будет отслеживать успешное запуск проекта и его завершение. Пример кода приведён ниже:```markdown @Component public class AppListener implements CommandLineRunner, DisposableBean {
@Override public void run(String... args) throws Exception { System.out.println("Приложение успешно запущено, начинается предзагрузка данных"); }
@Override public void destroy() throws Exception { System.out.println("Приложение закрывается, очистка данных"); }
}
Каждый `SpringApplication`, при запуске, регистрирует в JVM закрытий-хук (`shutdown hook`), чтобы гарантировать, что `ApplicationContext` будет правильно завершён при выходе. Все методы закрытия сервиса основаны на этом принципе.
### Метод 1: Закрытие сервиса через механизм конечных точек Actuator
Для использования этого метода необходимо добавить зависимость `spring-boot-starter-actuator`.

По умолчанию конечная точка `shutdown` отключена, её можно включить в файле `application.properties`:
management.endpoint.shutdown.enabled=true
Хотя конечные точки Actuator поддерживают удалённый доступ через JMX или HTTP, по умолчанию конечная точка `shutdown` не поддерживает доступ через HTTP. Поэтому для использования HTTP запросов для закрытия сервиса, её также нужно включить:
management.endpoints.web.exposure.include=shutdown
После запуска Spring Boot сервиса, используйте POST запрос для вызова следующего интерфейса, чтобы закрыть сервис!
http://127.0.0.1:8080/actuator/shutdown

```### Метод 2: Закрытие сервиса с помощью метода close ApplicationContext
Если вы не хотите добавлять зависимость `spring-boot-starter-actuator` для закрытия сервиса, вы можете использовать метод `close` объекта `ApplicationContext`. Этот метод автоматически уничт Yöntem 2: Сервис закрытие с помощью метода close ApplicationContext
Если вы не хотите добавлять зависимость `spring-boot-starter-actuator` для закрытия сервиса, вы можете использовать метод `close` объекта `ApplicationContext`. Этот метод автоматически уничтожает объекты `bean` и закрывает сервис.
Необходимо получить объект `ApplicationContext` при запуске приложения и вызвать метод `close` в нужном месте. Пример кода представлен ниже:

Конечно, мы можем самостоятельно написать контроллер `Controller`, получить соответствующий объект `ApplicationContext` и использовать метод `close` через API для остановки сервиса. Пример кода представлен ниже:

### Метод 3: Отслеживание PID сервиса и закрытие с помощью команды kill
Использование метода API для остановки сервиса может считаться небезопасным, так как утечка API может позволить пользователям случайно запрашивать этот API для остановки сервиса, что может иметь серьезные последствия. Поэтому многие рекомендуют использовать другие способы остановки сервиса на стороне сервера, например, через команды управления процессами.
При запуске `springboot` можно записать PID приложения в файл `app.pid`, путь к которому можно указать. Затем можно использовать скрипты для остановки сервиса.Пример кода при запуске представлен ниже:

С помощью следующей команды можно безопасно остановить сервис:
cat /home/app/project1/app.pid | xargs kill
Этот метод является одним из наиболее распространенных решений в операционной системе Linux, хотя реализация может отличаться. В некоторых случаях не требуется создавать файл, достаточно получить PID приложения другими способами.
**Если использовать метод `kill -9 <pid>`, то слушатели сервиса не получат никаких сообщений, что эквивалентно принудительному завершению приложения. Этот метод не рекомендуется!**
### Метод 4: Использование метода exit класса SpringApplication для остановки сервиса
Вызов метода `SpringApplication.exit()` также позволяет безопасно завершить работу программы и вернуть код завершения, который будет передан всем контекстам. В конечном итоге, вызов `System.exit()` передаст этот код ошибки JVM.
Пример кода представлен ниже:
@SpringBootApplication public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(Application.class, args);
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Остановка сервиса через 5 секунд
exitApplication(context);
}
}
```1. Использование ключевого слова new: это самый распространенный способ создания объекта.
MyClass obj = new MyClass();
MyClass obj = MyClass.class.newInstance();
Cloneable, можно использовать метод clone() для создания копии объекта.MyClass obj1 = new MyClass();
MyClass obj2 = obj1.clone();
MyClass obj = MyFactory.createInstance();
MyClass obj = MyClass.getInstance();
MyEnum enumInstance = MyEnum.INSTANCE;
## Сценарии использования ThreadLocal и возникающие проблемы
## Введение в модель родительского делегирования и ситуации, нарушающие её
## Bean в Spring и модель родительского делегирования
## Уровни изоляции в MySQL
## Как решить проблему phantom reads
## Задачи, выполняемые с помощью локировки промежутков
## Задачи, выполняемые с помощью механизма многовариантного контроля версий (MVCC)
## Различия между TCP и UDP
## Задачи, выполняемые с помощью состояния TIME_WAIT
## Внимание при создании индексов в MySQL
## Проблемы, связанные с созданием объединённых индексов
## Принцип левостороннего соответствия
## Влияние редкости данных на эффективность индексации
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.

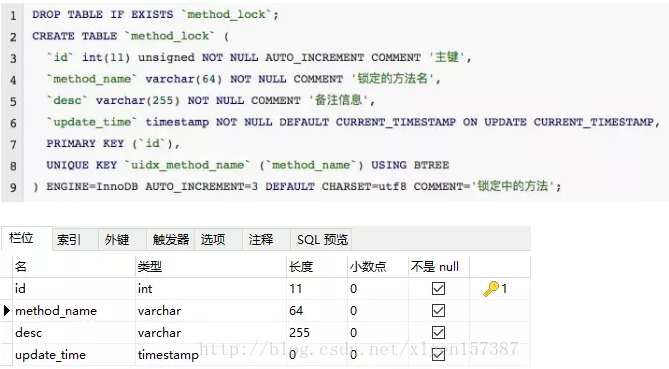

Опубликовать ( 0 )