Слияние кода завершено, страница обновится автоматически
Flink является стандартным реального времени обработчика, основанным на событийной модели. В то время как Spark Streaming использует модель микробатчей (Micro-Batch).
Structured Streaming не поддерживает прямое объединение с таблицами, но можно использовать map, flatMap и udf для реализации этой функциональности, все эти операторы являются синхронными и не поддерживают асинхронное ввод-вывод. Однако Structured Streaming поддерживает прямое объединение со статическими наборами данных, что также помогает реализовать объединение с таблицами, конечно, таблицы должны быть неизменяемыми.
Flink поддерживает объединение с таблицами, кроме map и flatMap, Flink имеет асинхронные операторы ввод-вывода, которые могут использоваться для реализации таблиц и повышения производительности.
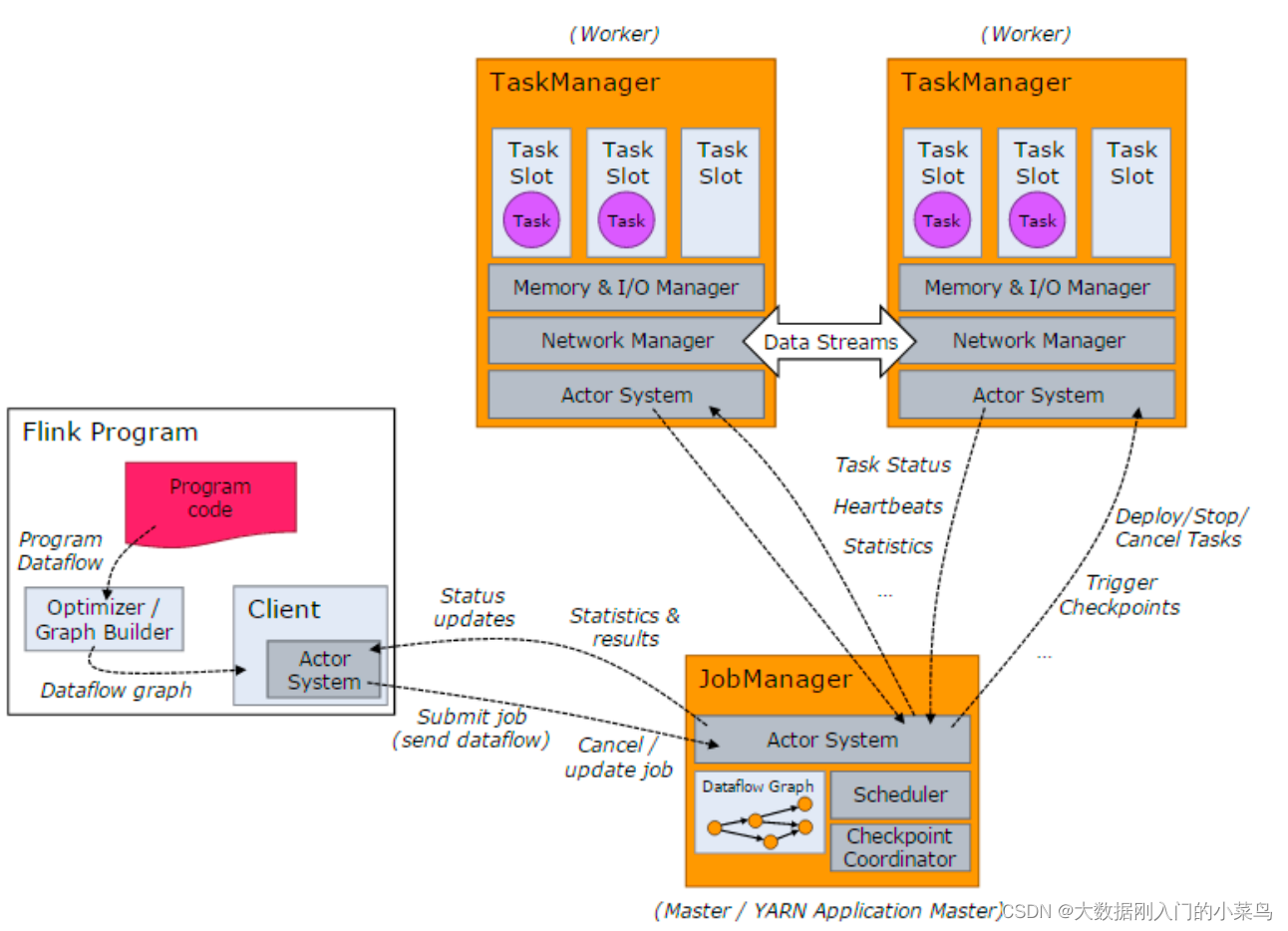
При запуске Flink-кластера, сначала запускается JobManager и один или несколько TaskManager. Задачи отправляются клиентом.1. JobManager, который затем распределяет задачи на различные TaskManager для выполнения. Затем TaskManager отправляют данные обратно в JobManager в виде пульса и статистической информации. TaskManager между собой передают данные в виде потока. Все три являются независимыми процессами JVM.
1.1. Клиент (Client) представляет собой сущность, которая отправляет задачу (Job), и может находиться на любой машине (взаимодействие с окружением JobManager возможно). После отправки задачи клиент может завершить процесс (для потоковых задач), либо продолжить работу и ждать возврата результата.1.2. JobManager отвечает за распределение задач и координацию задач для выполнения контрольных точек (checkpoints), что очень похоже на роль Nimbus в Storm. Получив задачу и JAR-файлы от клиента, он создает оптимизированный план выполнения и распределяет задачи на TaskManager для выполнения.
1.3. При запуске TaskManager устанавливается количество слотов (slots), каждый из которых может запустить одну задачу, являющуюся потоком. Получив задачи от JobManager, TaskManager запускает их и устанавливает соединение Netty с предыдущими компонентами, чтобы получать и обрабатывать данные.
Flink может быть развернут несколькими способами, включая standalone режим, YARN, Mesos, Kubernetes, Docker, AWS, Google Compute Engine, MAPR и другие.


Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )