Слияние кода завершено, страница обновится автоматически
Английский | Китайский
PaddlePALM (PArallel Learning from Multi-tasks) — это быстрый, гибкий, расширяемый и удобный в использовании фреймворк для масштабной предобучаемости и многотаскового обучения в области естественного языка. PaddlePALM представляет собой высокий уровень фреймворка, целенаправленно направленный на быстрое развитие высокопроизводительных моделей NLP.
С помощью PaddlePALM легко достичь эффективного исследования надежного обучения моделей NLP с несколькими вспомогательными задачами. Например, используя PaddlePALM, созданный моделью D-Net был признан первой позицией на треке EMNLP2019 MRQA.
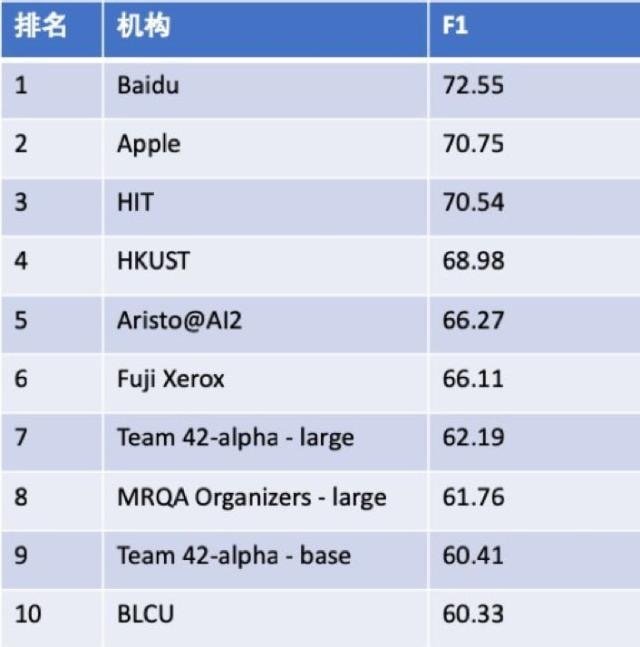
Лидборд MRQA2019
Помимо исследовательской области, PaddlePALM был применён на поисковой системе Baidu, чтобы повысить точность понимания запросов пользователей и минирования ответов, что свидетельствует о высокой надёжности и производительности PaddlePALM.
Встроенная популярная основа NLP и предобученные модели: множество передовых общих архитектур моделей и предобученных моделей (например, BERT, ERNIE, RoBERTa...) встроены.
Удобное многотасковое обучение: требуется всего один API для совместного обучения нескольких задач с переиспользованием параметров.
Поддерживает обучение/оценку с несколькими GPU: автоматически распознаёт и адаптируется к режиму работы с несколькими GPU для ускорения обучения и вывода.
Дружественно к предобучению: самонастраивающиеся задачи (например, маска для языковой модели) встроены для упрощения предобучения. Легко обучаться с нуля.
Удобство кастомизации: поддерживает кастомизацию любого компонента (например, основа, голова задачи, читатель и оптимизатор) с переиспользованием заранее определённых, что даёт разработчикам высокую гибкость и эффективность для адаптации к различным сценариям NLP.Вы можете легко воспроизводить следующие конкурентоспособные результаты с минимальным количеством кода, что охватывает большинство задач NLP, таких как классификация, соответствие, последовательное маркирование, чтение с пониманием содержания, понимание диалогов и так далее. Более подробная информация доступна в примерах.
|
Датасет
|
chnsenticorp | Соответствие пар вопросов Quora | MSRA-NER (SIGHAN2006) |
CMRC2018 | |||
|---|---|---|---|---|---|---|---|
|
Метрика
|
точность
|
F1-score
|
точность
|
F1-score
|
F1-score
|
EM
|
F1-score
|
|
тест
|
тест
|
тест
|
разработка
|
||||
| ERNIE Base | 95.8 | 95.8 | 86.2 | 82.2 | 99.2 | 64.3 | 85.2 |
<img src="https://tva1.sinaimg.cn/large/0082zybply1gbyo8d4ltoj31ag0n3tby.jpg" alt="Пример" width="600px" height="auto">
<p align="center">
<em>Схема архитектуры</em>
</p>
PaddlePALM — это хорошо спроектированный высокий уровень NLP-фреймворк. Вы можете эффективно достичь наблюдаемого обучения, ненаблюдаемого/самонастроенного обучения, многозадачного обучения и обучения с переносом с минимальным количеством кода на основе PaddlePALM. В архитектуре PaddlePALM есть три слоя: слой компонентов, слой трейнеров и высший уровень слоя трейнеров снизу вверх. В компонентном слое PaddlePALM предоставляются 6 отделенных компонентов для выполнения задачи NLP. Каждый компонент включает богатые заранее определенные классы и базовый класс. Заранее определенные классы предназначены для типичных задач NLP, а базовый класс помогает пользователям создавать новый класс (на основе заранее определенных или от базового).Слой трейнера предназначен для создания вычислительного графика с выбранными компонентами и выполнения обучения и прогнозирования. Стратегия обучения, сохранение и загрузка модели, процедуры оценки и прогнозирования описаны в этом слое. Обратите внимание, что один трейнер может обрабатывать только одну задачу.
Высший уровень слоя трейнера предназначен для сложной стратегии обучения и вывода, например, многозадачного обучения. Вы можете добавить вспомогательные задачи для обучения устойчивых моделей NLP (повышения производительности тестовых наборов и внеобластной производительности модели) или совместного обучения нескольких связанных задач для повышения производительности каждой задачи.| модуль | иллюстрация | | - | - | | paddlepalm | открыта система предварительного обучения и многозадачного обучения NLP, основанная на PaddlePaddle. | | paddlepalm.reader | коллекция эластичных читателей данных для конкретных задач. | | paddlepalm.backbone | коллекция классических моделей представления NLP, таких как BERT, ERNIE, RoBERTa. | | paddlepalm.head | коллекция специализированных выходных слоёв для задач. | | paddlepalm.lr_sched | коллекция планировщиков скорости обучения. | | paddlepalm.optimizer | коллекция оптимизаторов. | | paddlepalm.downloader | модуль загрузки предварительно обученных моделей с конфигурационными и словарными файлами. | | paddlepalm.Trainer | основная единица для запуска сессии одиночного обучения/предсказания. Трейнер создаёт вычислительный граф, управляет процессом обучения и оценки, обеспечивает сохранение модели/точки контроля и загрузку предварительно обученной модели/точки контроля. | | paddlepalm.MultiHeadTrainer | основная единица для запуска сессии многозадачного обучения/предсказания. Мультиголовый трейнер создан на основе нескольких трейнеров. Кроме наследования от трейнера, он дополнительно обеспечивает переиспользование основного блока модели между задачами, выбор трейнеров для многозадачного обучения и мультиголовый вывод для эффективной оценки и предсказания. |## Установка
PaddlePALM поддерживает как Python 2, так и Python 3, Linux и Windows, CPU и GPU. Предпочтительный способ установки PaddlePALM — через pip. Просто выполните следующие команды в вашей оболочке:
pip install paddlepalm
git clone https://github.com/PaddlePaddle/PALM.git
cd PALM && python setup.py install
Мы включаем множество предобученных моделей для инициализации параметров основной части модели. Обучение больших моделей NLP, таких как 12-слойные трансформеры, с использованием предобученных моделей практически эффективнее, чем обучение с случайно инициализированными параметрами. Чтобы просмотреть все доступные предобученные модели и скачать их, выполните следующий код в интерпретаторе Python (введите команду python в командной строке):
>>> from paddlepalm import downloader
>>> downloader.ls('pretrain')
Доступные предобученные элементы:
=> RoBERTa-zh-base
=> RoBERTa-zh-large
=> ERNIE-v2-en-base
=> ERNIE-v2-en-large
=> XLNet-cased-base
=> XLNet-cased-large
=> ERNIE-v1-zh-base
=> ERNIE-v1-zh-base-max-len-512
=> BERT-en-uncased-large-whole-word-masking
=> BERT-en-cased-large-whole-word-masking
=> BERT-en-uncased-base
=> BERT-en-uncased-large
=> BERT-en-cased-base
=> BERT-en-cased-large
=> BERT-multilingual-uncased-base
=> BERT-multilingual-cased-base
=> BERT-zh-base
>>> downloader.download('pretrain', 'BERT-en-uncased-base', './pretrain_models')
...
```## Пример использования
#### Быстрая настройка8 шагов для запуска типичной задачи обучения NLP:
1. Используйте `paddlepalm.reader` для создания *чтения* данных набора и генерации входных признаков, затем вызовите метод `reader.load_data` для загрузки ваших данных обучения.
2. Используйте `paddlepalm.backbone` для создания модели *основы* для извлечения текстовых признаков (например, контекстное слово вложение, вложение предложения).
3. Зарегистрируйте ваш *чтение* с помощью вашего *основы* через метод `reader.register_with`. После этого шага ваш читатель может выдавать входные признаки, используемые основой.
4. Используйте `paddlepalm.head` для создания выходной части задачи *головы*. Эта голова может предоставлять потерю задачи для обучения и прогнозирующие результаты для вывода модели.
5. Создайте обучаемый объект задачи с помощью `paddlepalm.Trainer`, затем постройте граф переднего распространения с использованием основы и выходной части задачи (созданной на шагах 2 и 4) через метод `trainer.build_forward`.
6. Используйте `paddlepalm.optimizer` (и `paddlepalm.lr_sched`, если это необходимо) для создания *оптимизатора*, затем постройте обратное распространение через метод `trainer.build_backward`.
7. Подготовьте чтение и данные (полученные на шаге 1) для тренировщика с помощью метода `trainer.fit_reader`.
8. Загрузите предобученную модель с помощью `trainer.load_pretrain`, или загрузите контрольную точку с помощью `trainer.save_checkpoint`.выполните `load_ckpt` или ничего не делайте для обучения с нуля, затем выполните обучение с помощью `trainer.train`. Для получения более подробной информации о реализации см. следующие демонстрационные примеры:- [Классификация настроений](https://github.com/PaddlePaddle/PALM/tree/master/examples/classification)
- [Соответствие пар вопросов](https://github.com/PaddlePaddle/PALM/tree/master/examples/matching)
- [Распознавание сущностей](https://github.com/PaddlePaddle/PALM/tree/master/examples/tagging)
- [Машинное чтение и понимание контента вроде SQuAD](https://github.com/PaddlePaddle/PALM/tree/master/examples/mrc)
#### Обучение несколькими задачами одновременно
Чтобы запустить обучение нескольким задачам одновременно:
1. повторно создайте компоненты (например, читатель, основной модуль и голова) для каждой задачи, затем выполните шаги 1~5 выше.
2. создайте пустых трейнеров (каждый трейнер соответствует одной задаче) и передайте их для создания `MultiHeadTrainer`.
3. постройте граф передачи нескольких задач с помощью метода `multi_head_trainer.build_forward`.
4. используйте `paddlepalm.optimizer` (и `paddlepalm.lr_sched`, если это необходимо) для создания *оптимизатора*, затем постройте обратную связь через `multi_head_trainer.build_backward`.
5. подготовьте всех созданных читателей и данные для `multi_head_trainer` с помощью метода `multi_head_trainer.fit_readers`.
6. загрузите предобученную модель с помощью `multi_head_trainer.load_pretrain`, или загрузите контрольную точку с помощью `multi_head_trainer.load_ckpt`, или ничего не делайте при обучении с нуля, а затем начните обучение с помощью `multi_head_trainer.train`.
Операции сохранения/загрузки и прогнозирования для `multi_head_trainer` аналогичны операциям для обычного трейнера.Для получения более подробной информации о реализации с использованием `multi_head_trainer`, см.
- [ATIS: совместное обучение распознавания намерений диалога и заполнения слотов](https://github.com/PaddlePaddle/PALM/tree/master/examples/multi-task)
#### Сохранение моделей
Чтобы сохранять модели/контрольные точки и логи во время обучения, просто вызовите метод `trainer.set_saver`. Дополнительные детали реализации см. [здесь](https://github.com/PaddlePaddle/PALM/tree/master/examples).
#### Оценка/Интерпретация
Чтобы сделать прогноз/оценку после этапа обучения, просто создайте ещё три экземпляра читателя, основного модуля и головы с `phase='predict'` (повторите шаги 1~4 выше). Затем сделайте прогнозирование с помощью метода `predict` в трейнере (не требуется создание другого трейнера). Дополнительные детали реализации см. [здесь](https://github.com/PaddlePaddle/PALM/tree/master/examples/predict). Если вы хотите выполнять оценку во время процесса обучения, используйте `trainer.train_one_step()`. Метод `trainer.train_one_step(batch)` позволяет обучаться всего за один шаг, поэтому вы можете вставить код оценки в любой момент процесса обучения. Аргумент `batch` можно получить с помощью метода `trainer.get_one_batch`.
PaddlePALM также поддерживает многоголовое inference, пожалуйста, обратитесь к `examples/multi-task/joint_predict.py`.#### Играйте с несколькими GPU
Если в вашей среде существует несколько GPU, вы можете контролировать количество и индекс этих GPU через переменную окружения [CUDA_VISIBLE_DEVICES](https://devblogs.nvidia.com/cuda-pro-tip-control-gpu-visibility-cuda_visible_devices/). Например, если в вашей среде есть 4 GPU, индексируемых как 0, 1, 2, 3, вы можете запустить только с GPU2 следующими командами:```shell
CUDA_VISIBLE_DEVICES=2 python run.py
Несколько GPU должны быть разделены запятой. Например, запуск с GPU2 и GPU3, следующие команды используются:
CUDA_VISIBLE_DEVICES=2,3 python run.py
В режиме работы с несколькими GPU, PaddlePaddle автоматически распределяет каждый батч между доступными картами. Например, если значение batch_size установлено на 64, а видимых для PaddlePaddle карт 4, то фактический размер батча на каждой карте будет равен 64/4 = 16. Поэтому при работе с несколькими картами необходимо убедиться, что установленный размер батча может быть разделён на количество карт.
Этот учебник предоставлен PaddlePaddle и лицензирован под лицензией Apache-2.0.
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Комментарии ( 0 )