Слияние кода завершено, страница обновится автоматически
English | Chinese
PaddlePALM (PArallel Learning from Multi-tasks) — это гибкий, универсальный и легко используемый NLP-фреймворк для масштабной предобученной подготовки и обучения с несколькими задачами. PALM представляет собой верхнеуровневый фреймворк, предназначенный для быстрого создания высокопроизводительных моделей NLP.
С помощью PaddlePALM можно легко исследовать модели чтения и понимания с высокой устойчивостью, обученные с использованием различных вспомогательных задач. Модели, обученные на основе PALM D-Net, заняли первое место на международном конкурсе по чтению и пониманию текста EMNLP2019.
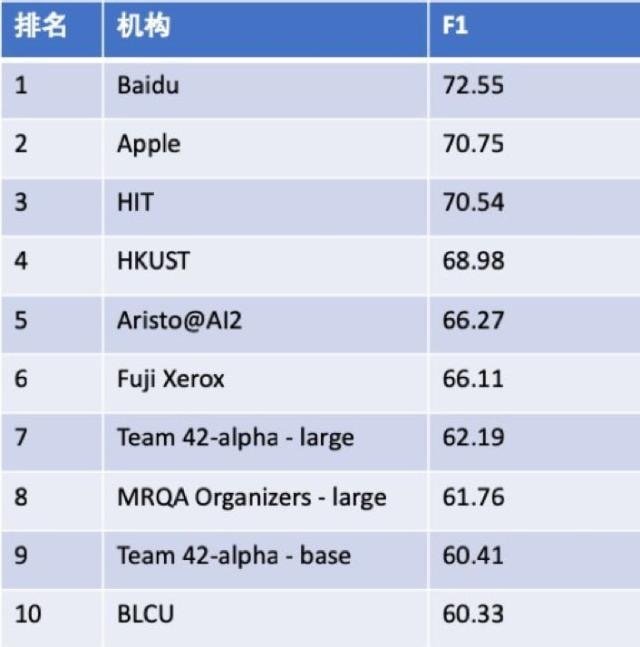
Рейтинг MRQA2019
Кроме снижения затрат на исследования в области NLP, PaddlePALM был применён в "поисковой системе Baidu", что значительно повысило точность понимания запросов пользователей и качество найденных ответов, обеспечивая высокую надёжность и производительность обучения и вывода.
examples.|
Датасет
|
chnsenticorp | Пары вопросов Quora | MSRA-NER (SIGHAN2006) |
CMRC2018 | |||
|---|---|---|---|---|---|---|---|
|
Метрика
|
точность
|
F1-мера
|
точность
|
F1-мера
|
F1-мера
|
EM
|
F1-мера
|
|
тест
|
тест
|
тест
|
разработка
|
||||
| ERNIE Base | 95.8 | 95.8 | 86.2 | 82.2 | 99.2 | 64.3 | 85.2 |

Схема архитектуры PALM
PaddlePALM — это хорошо спроектированный высокий уровень NLP-фреймворк. Лёгкий код PaddlePALM может эффективно реализовать наблюдаемое обучение, необучаемое/автономное обучение, мультизадачное обучение и перенос обучения. В архитектуре PaddlePALM есть три слоя, от нижнего до верхнего: компонентный слой, трейнер слой и слой высокого уровня трейнера.
В компонентном слое PaddlePALM предоставляются шесть расщепленных компонентов для выполнения задач NLP. Каждый компонент включает множество заранее определённых классов и базового класса. Заранее определённые классы предназначены для типичных задач NLP, в то время как базовый класс помогает пользователям создать новый класс (на основе заранее определённых классов или базовых классов).
Трейнер слой используется для создания вычислительной графики с выбранными компонентами, тренировки и прогнозирования. Этот слой описывает стратегии обучения, сохранение и загрузку моделей, оценку и процесс прогнозирования. Один трейнер может обрабатывать только одну задачу.Высокий уровень трейнера слой используется для сложных стратегий обучения и вывода, таких как мультизадачное обучение. Вы можете добавить вспомогательные задачи для тренировки устойчивых NLP-моделей (повышение производительности модели на тестовой выборке и за её пределами) или совместного обучения нескольких связанных задач для повышения производительности каждого из них.| Модуль | Описание | | - | - | | paddlepalm | Высокий уровень NLP-предварительной подготовки и мультизадачного обучения на основе фреймворка PaddlePaddle. | | paddlepalm.reader | Предопределённые инструменты для чтения и предобработки данных задач. | | paddlepalm.backbone | Предопределённые основные сети, такие как BERT, ERNIE, RoBERTa. | | paddlepalm.head | Предопределённые выходные слои задач. | | paddlepalm.lr_sched | Предопределённые стратегии планирования скорости обучения. | | paddlepalm.optimizer | Предопределённые оптимизаторы. | | paddlepalm.downloader | Модуль управления и загрузки предварительно обученных моделей. | | paddlepalm.Trainer | Единицы обучения/прогнозирования задач. Трейнеры используются для создания вычислительной графики, управления процессами обучения и оценки, реализации сохранения/загрузки моделей/точек контроля и предварительно обученных моделей/точек контроля. | | paddlepalm.MultiHeadTrainer | Модуль для выполнения мультизадачного обучения/прогнозирования. Один MultiHeadTrainer основан на нескольких трейнерах. Реализует повторное использование основных сетей между задачами, мультизадачное обучение и вывод. |
PaddlePALM поддерживает Python 2 и Python 3, Linux и Windows, CPU и GPU. Первым методом установки PaddlePALM является через pip. Просто запустите следующую команду:
pip install paddlepalm
git clone https://github.com/PaddlePaddle/PALM.git cd PALM && python setup.py install
### Библиотечные зависимости
- Python >= 2.7
- CUDA >= 9.0
- cuDNN >= 7.0
- PaddlePaddle >= 1.7.0 (пожалуйста, обратитесь к [инструкциям по установке](http://www.paddlepaddle.org/#quick-start))
### Загрузка предобученных моделей
Мы предоставляем множество предобученных моделей для инициализации параметров основной сети модели. Обучение больших NLP-моделей, таких как 12-слойные Transformer, с использованием предобученной модели фактически более эффективно, чем случайная инициализация. Чтобы просмотреть все доступные предобученные модели и скачать их, выполните следующий код в интерпретаторе Python (введите команду `python` в shell):
```python
>>> from paddlepalm import downloader
>>> downloader.ls('pretrain')
Доступные предобученные элементы:
=> RoBERTa-zh-base
=> RoBERTa-zh-large
=> ERNIE-v2-en-base
=> ERNIE-v2-en-large
=> XLNet-cased-base
=> XLNet-cased-large
=> ERNIE-v1-zh-base
=> ERNIE-v1-zh-base-max-len-512
=> BERT-en-uncased-large-whole-word-masking
=> BERT-en-cased-large-whole-word-masking
=> BERT-en-uncased-base
=> BERT-en-uncased-large
=> BERT-en-cased-base
=> BERT-en-cased-large
=> BERT-multilingual-uncased-base
=> BERT-multilingual-cased-base
=> BERT-zh-base
>>> downloader.download('pretrain', 'BERT-en-uncased-base', './pretrain_models')
...
paddlepalm.reader для создания reader, который будет загружать данные и генерировать входные признаки. Затем вызовите метод reader.load_data для загрузки данных обучения.paddlepalm.load_data для создания основной сети модели для извлечения текстовых признаков (например, контекстных словных вложений, вложений предложений).reader.register_with для регистрации reader с основной сетью. После этого шага reader сможет использовать входные признаки, созданные основной сетью.paddlepalm.head. Создайте голову задачи, которая может предоставлять потери обучения для тренировки и прогнозные результаты для модели.paddlepalm.Trainer для создания тренера задачи, затем используйте Trainer.build_forward для построения графа прямого распространения, содержащего основную сеть и голову задачи (созданные на шагах 2 и 4).paddlepalm.optimizer (если требуется, создайте paddlepalm.lr_sched) для создания оптимизатора, затем используйте train.build_back для обратного построения.trainer.fit_reader для передачи подготовленного reader и данных (реализовано на шаге 1) тренеру.trainer.load_pretrain для загрузки предобученной модели или используйте trainer.load_pretrain для загрузки checkpoint, или не загружайте никакие обученные параметры, а затем используйте trainer.train для обучения.Дополнительные реализационные детали см. в примерах:- Эмоциональный анализ
Обучение с несколькими задачами выполняется следующим образом:
Trainer (каждый Trainer соответствует одной задаче), а затем используйте их для создания MultiHeadTrainer.multi_head_trainer.build_forward для построения многозадачной графики прямого распространения.paddlepalm.optimizer (если требуется, создайте paddlepalm.lr_sched) для создания оптимизатора, а затем используйте multi_head_trainer.build_backward для создания обратного распространения.multi_head_trainer.fit_readers, чтобы поместить все подготовленные читатели и данные в multi_head_trainer.multi_head_trainer.load_pretrain для загрузки предобученной модели или используйте multi_head_trainer.load_checkpoint для загрузки checkpoint, либо не загружайте уже обученные параметры, а затем используйте multi_head_trainer.train для обучения.Сохранение/загрузка multi_head_trainer и прогнозирование аналогичны операциям с trainer.
Дополнительные реализационные детали multi_head_trainer см. в:- ATIS: Совместное обучение намерений диалога и заполнения слотов
При сохранении моделей/checkpoints и логов во время обучения вызовите метод trainer.set_saver. Дополнительные реализационные детали см. здесь:ссылка.
После завершения обучения выполните прогнозирование и оценку, создав дополнительного читателя, основной блок и голову (повторите шаги 1–4 выше), при этом важно указать phase='predict' при создании. Затем используйте метод predict тренера для прогнозирования (необходимость создания дополнительного тренера отсутствует). Дополнительные реализационные детали см. здесь:ссылка.
Если ваша среда имеет несколько GPU, вы можете контролировать количество и индексы этих GPU через переменные окружения CUDA_VISIBLE_DEVICES. Например, если у вас есть четыре GPU с индексами 0, 1, 2, 3, вы можете запустить команду, чтобы использовать только GPU2.
CUDA_VISIBLE_DEVICES=2 python run.py
Использование нескольких GPU требует разделения номеров GPU запятой. Например, чтобы использовать GPU 2 и GPU 3, выполните следующую команду:
CUDA_VISIBLE_DEVICES=2,3 python run.py
```В режиме работы с несколькими GPU PaddlePALM автоматически распределяет данные каждого батча между доступными GPU. Например, если `batch_size` установлен в 64, и есть 4 GPU доступных для использования PaddlePALM, то фактический размер батча на каждом GPU будет равен 64 / 4 = 16. Поэтому **при использовании нескольких GPU важно, чтобы значение batch_size делилось на количество доступных GPU без остатка**.
## Лицензионное соглашение
Этот гайд предоставлен [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) и лицензирован под [лицензией Apache-2.0](https://github.com/PaddlePaddle/models/blob/develop/LICENSE).
Вы можете оставить комментарий после Вход в систему
Неприемлемый контент может быть отображен здесь и не будет показан на странице. Вы можете проверить и изменить его с помощью соответствующей функции редактирования.
Если вы подтверждаете, что содержание не содержит непристойной лексики/перенаправления на рекламу/насилия/вульгарной порнографии/нарушений/пиратства/ложного/незначительного или незаконного контента, связанного с национальными законами и предписаниями, вы можете нажать «Отправить» для подачи апелляции, и мы обработаем ее как можно скорее.
Опубликовать ( 0 )